 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Simulators: No Regret in a Computationally Bounded World
Jun 11, 2026Understanding the minimal assumptions necessary for generalization is the fundamental question in learning theory. Unfortunately, most results rely heavily on independence (or some proxy thereof) of the data-generating process, while results for strongly dependent data are far more limited. Towards addressing this gap, we introduce the framework of simulatable processes, where the learner has access to a simulator that approximates the distribution generating the data (which may be an arbitrarily complex and dependent process). Surprisingly, given access to such a simulator, we show that we can recover the same learning guarantees as in the classical setting with independent data, namely, error bounds that depend on the VC dimension. Further, we use this framework to study the power of conditional sampling and show strict statistical and computational advantages in this setting. As a highlight of our framework, we exhibit a single algorithm that simultaneously learns any given VC class under all processes samplable in bounded polynomial time, with regret controlled by the time-bounded Kolmogorov complexity of the process. This provides a significant conceptual broadening of the classical PAC model.
The Power of Test-Time Training for Approximate Sampling
Jun 09, 2026Efficiently sampling from a complex probability distribution is a fundamental problem which has become increasingly pertinent in recent years with the rise of generative AI, as sophisticated sampling procedures from LLMs have been proposed to solve challenging reasoning problems. The efficacy of such sampling algorithms is limited, however, by the relationship between the LLM and the particular sampling task at hand, which has motivated the framework of test-time training (TTT). TTT works by updating a model's weights in response to partial generations and reward feedback received at inference time, thus adapting to the particular problem. In this work, we propose a formalization for TTT as the problem of producing a sample from a given probability measure $μ^\star$ belonging to a known class ${F}$ of distributions, given an oracle $\hat μ$ which yields approximate density estimates for $μ^\star$. This is closely related to the problem of reducing sampling to approximate counting studied in seminal works of Jerrum, Valiant & Vazirani (1986) and Jerrum & Sinclair (1989): namely, when ${F}$ is the class of all distributions, it coincides exactly with the aforementioned counting-to-sampling reduction. In this paper, we first show a quadratic lower bound on the query complexity of sampling from $μ^\star$ given query access to $\hat μ$ (for sufficiently large classes ${F}$), thus showing that the random walk approach proposed by Jerrum & Sinclair (1989) and refined by Hayes & Sinclair (2010), is optimal. This answers an open question posed by Hayes & Sinclair. We then show that this lower bound can be circumvented if the size of ${F}$ is bounded appropriately. As we discuss, this latter result can be viewed as an abstraction of TTT, and thus represents a starting point for the development of a principled theoretical framework for TTT.
Reject, Resample, Repeat: Understanding Parallel Reasoning in Language Model Inference
Mar 09, 2026Inference-time methods that aggregate and prune multiple samples have emerged as a powerful paradigm for steering large language models, yet we lack any principled understanding of their accuracy-cost tradeoffs. In this paper, we introduce a route to rigorously study such approaches using the lens of *particle filtering* algorithms such as Sequential Monte Carlo (SMC). Given a base language model and a *process reward model* estimating expected terminal rewards, we ask: *how accurately can we sample from a target distribution given some number of process reward evaluations?* Theoretically, we identify (1) simple criteria enabling non-asymptotic guarantees for SMC; (2) algorithmic improvements to SMC; and (3) a fundamental limit faced by all particle filtering methods. Empirically, we demonstrate that our theoretical criteria effectively govern the *sampling error* of SMC, though not necessarily its final *accuracy*, suggesting that theoretical perspectives beyond sampling may be necessary.
Subliminal Effects in Your Data: A General Mechanism via Log-Linearity
Feb 04, 2026Training modern large language models (LLMs) has become a veritable smorgasbord of algorithms and datasets designed to elicit particular behaviors, making it critical to develop techniques to understand the effects of datasets on the model's properties. This is exacerbated by recent experiments that show datasets can transmit signals that are not directly observable from individual datapoints, posing a conceptual challenge for dataset-centric understandings of LLM training and suggesting a missing fundamental account of such phenomena. Towards understanding such effects, inspired by recent work on the linear structure of LLMs, we uncover a general mechanism through which hidden subtexts can arise in generic datasets. We introduce Logit-Linear-Selection (LLS), a method that prescribes how to select subsets of a generic preference dataset to elicit a wide range of hidden effects. We apply LLS to discover subsets of real-world datasets so that models trained on them exhibit behaviors ranging from having specific preferences, to responding to prompts in a different language not present in the dataset, to taking on a different persona. Crucially, the effect persists for the selected subset, across models with varying architectures, supporting its generality and universality.
Provably Learning from Modern Language Models via Low Logit Rank
Dec 10, 2025While modern language models and their inner workings are incredibly complex, recent work (Golowich, Liu & Shetty; 2025) has proposed a simple and potentially tractable abstraction for them through the observation that empirically, these language models all seem to have approximately low logit rank. Roughly, this means that a matrix formed by the model's log probabilities of various tokens conditioned on certain sequences of tokens is well approximated by a low rank matrix. In this paper, our focus is on understanding how this structure can be exploited algorithmically for obtaining provable learning guarantees. Since low logit rank models can encode hard-to-learn distributions such as noisy parities, we study a query learning model with logit queries that reflects the access model for common APIs. Our main result is an efficient algorithm for learning any approximately low logit rank model from queries. We emphasize that our structural assumption closely reflects the behavior that is empirically observed in modern language models. Thus, our result gives what we believe is the first end-to-end learning guarantee for a generative model that plausibly captures modern language models.
High-Dimensional Calibration from Swap Regret
May 27, 2025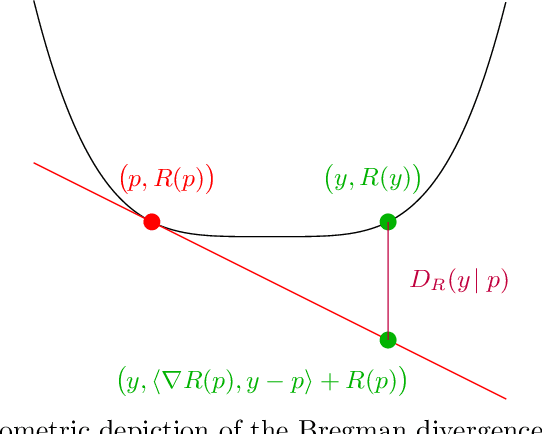
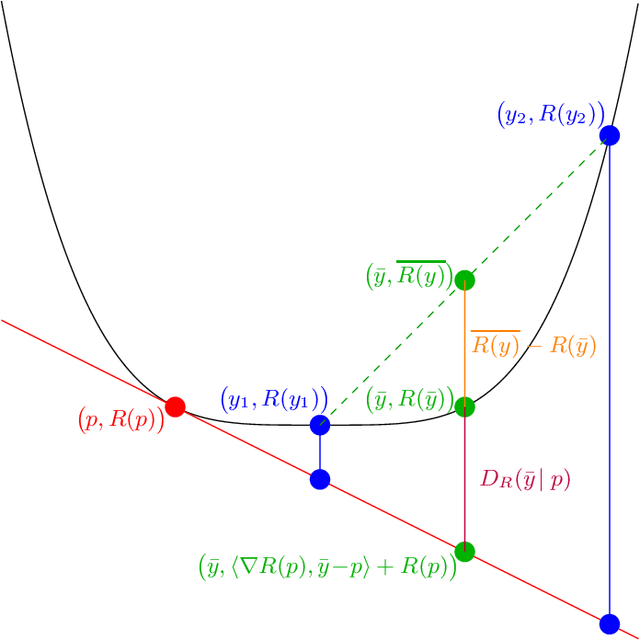

We study the online calibration of multi-dimensional forecasts over an arbitrary convex set $\mathcal{P} \subset \mathbb{R}^d$ relative to an arbitrary norm $\Vert\cdot\Vert$. We connect this with the problem of external regret minimization for online linear optimization, showing that if it is possible to guarantee $O(\sqrt{\rho T})$ worst-case regret after $T$ rounds when actions are drawn from $\mathcal{P}$ and losses are drawn from the dual $\Vert \cdot \Vert_*$ unit norm ball, then it is also possible to obtain $\epsilon$-calibrated forecasts after $T = \exp(O(\rho /\epsilon^2))$ rounds. When $\mathcal{P}$ is the $d$-dimensional simplex and $\Vert \cdot \Vert$ is the $\ell_1$-norm, the existence of $O(\sqrt{T\log d})$-regret algorithms for learning with experts implies that it is possible to obtain $\epsilon$-calibrated forecasts after $T = \exp(O(\log{d}/\epsilon^2)) = d^{O(1/\epsilon^2)}$ rounds, recovering a recent result of Peng (2025). Interestingly, our algorithm obtains this guarantee without requiring access to any online linear optimization subroutine or knowledge of the optimal rate $\rho$ -- in fact, our algorithm is identical for every setting of $\mathcal{P}$ and $\Vert \cdot \Vert$. Instead, we show that the optimal regularizer for the above OLO problem can be used to upper bound the above calibration error by a swap regret, which we then minimize by running the recent TreeSwap algorithm with Follow-The-Leader as a subroutine. Finally, we prove that any online calibration algorithm that guarantees $\epsilon T$ $\ell_1$-calibration error over the $d$-dimensional simplex requires $T \geq \exp(\mathrm{poly}(1/\epsilon))$ (assuming $d \geq \mathrm{poly}(1/\epsilon)$). This strengthens the corresponding $d^{\Omega(\log{1/\epsilon})}$ lower bound of Peng, and shows that an exponential dependence on $1/\epsilon$ is necessary.
The Role of Sparsity for Length Generalization in Transformers
Feb 24, 2025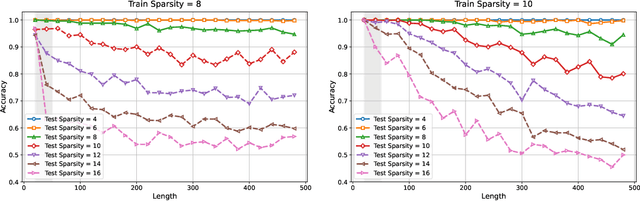

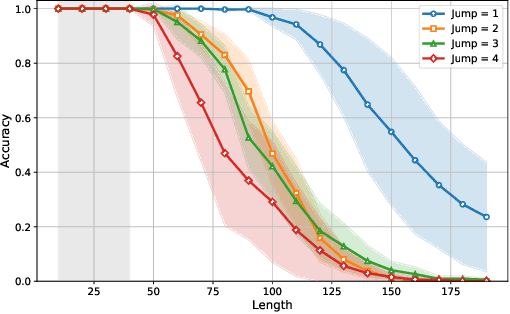
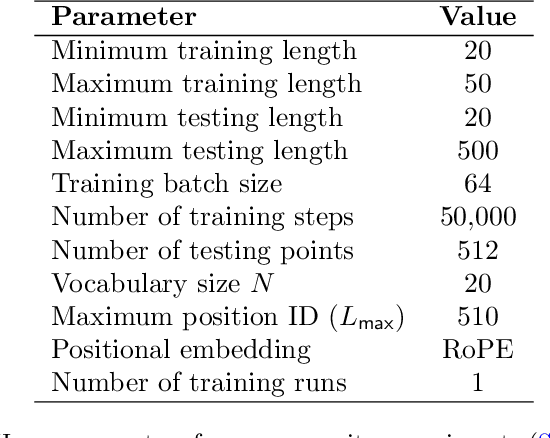
Training large language models to predict beyond their training context lengths has drawn much attention in recent years, yet the principles driving such behavior of length generalization remain underexplored. We propose a new theoretical framework to study length generalization for the next-token prediction task, as performed by decoder-only transformers. Conceptually, we show that length generalization occurs as long as each predicted token depends on a small (fixed) number of previous tokens. We formalize such tasks via a notion we call $k$-sparse planted correlation distributions, and show that an idealized model of transformers which generalize attention heads successfully length-generalize on such tasks. As a bonus, our theoretical model justifies certain techniques to modify positional embeddings which have been introduced to improve length generalization, such as position coupling. We support our theoretical results with experiments on synthetic tasks and natural language, which confirm that a key factor driving length generalization is a ``sparse'' dependency structure of each token on the previous ones. Inspired by our theory, we introduce Predictive Position Coupling, which trains the transformer to predict the position IDs used in a positional coupling approach. Predictive Position Coupling thereby allows us to broaden the array of tasks to which position coupling can successfully be applied to achieve length generalization.
Improved bounds for calibration via stronger sign preservation games
Jun 19, 2024A set of probabilistic forecasts is calibrated if each prediction of the forecaster closely approximates the empirical distribution of outcomes on the subset of timesteps where that prediction was made. We study the fundamental problem of online calibrated forecasting of binary sequences, which was initially studied by Foster & Vohra (1998). They derived an algorithm with $O(T^{2/3})$ calibration error after $T$ time steps, and showed a lower bound of $\Omega(T^{1/2})$. These bounds remained stagnant for two decades, until Qiao & Valiant (2021) improved the lower bound to $\Omega(T^{0.528})$ by introducing a combinatorial game called sign preservation and showing that lower bounds for this game imply lower bounds for calibration. We introduce a strengthening of Qiao & Valiant's game that we call sign preservation with reuse (SPR). We prove that the relationship between SPR and calibrated forecasting is bidirectional: not only do lower bounds for SPR translate into lower bounds for calibration, but algorithms for SPR also translate into new algorithms for calibrated forecasting. In particular, any strategy that improves the trivial upper bound for the value of the SPR game would imply a forecasting algorithm with calibration error exponent less than 2/3, improving Foster & Vohra's upper bound for the first time. Using similar ideas, we then prove a slightly stronger lower bound than that of Qiao & Valiant, namely $\Omega(T^{0.54389})$. Our lower bound is obtained by an oblivious adversary, marking the first $\omega(T^{1/2})$ calibration lower bound for oblivious adversaries.
Linear Bellman Completeness Suffices for Efficient Online Reinforcement Learning with Few Actions
Jun 18, 2024One of the most natural approaches to reinforcement learning (RL) with function approximation is value iteration, which inductively generates approximations to the optimal value function by solving a sequence of regression problems. To ensure the success of value iteration, it is typically assumed that Bellman completeness holds, which ensures that these regression problems are well-specified. We study the problem of learning an optimal policy under Bellman completeness in the online model of RL with linear function approximation. In the linear setting, while statistically efficient algorithms are known under Bellman completeness (e.g., Jiang et al. (2017); Zanette et al. (2020)), these algorithms all rely on the principle of global optimism which requires solving a nonconvex optimization problem. In particular, it has remained open as to whether computationally efficient algorithms exist. In this paper we give the first polynomial-time algorithm for RL under linear Bellman completeness when the number of actions is any constant.
The Role of Inherent Bellman Error in Offline Reinforcement Learning with Linear Function Approximation
Jun 18, 2024In this paper, we study the offline RL problem with linear function approximation. Our main structural assumption is that the MDP has low inherent Bellman error, which stipulates that linear value functions have linear Bellman backups with respect to the greedy policy. This assumption is natural in that it is essentially the minimal assumption required for value iteration to succeed. We give a computationally efficient algorithm which succeeds under a single-policy coverage condition on the dataset, namely which outputs a policy whose value is at least that of any policy which is well-covered by the dataset. Even in the setting when the inherent Bellman error is 0 (termed linear Bellman completeness), our algorithm yields the first known guarantee under single-policy coverage. In the setting of positive inherent Bellman error ${\varepsilon_{\mathrm{BE}}} > 0$, we show that the suboptimality error of our algorithm scales with $\sqrt{\varepsilon_{\mathrm{BE}}}$. Furthermore, we prove that the scaling of the suboptimality with $\sqrt{\varepsilon_{\mathrm{BE}}}$ cannot be improved for any algorithm. Our lower bound stands in contrast to many other settings in reinforcement learning with misspecification, where one can typically obtain performance that degrades linearly with the misspecification error.