 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Test-Time Training for Approximate Sampling
Jun 09, 2026Efficiently sampling from a complex probability distribution is a fundamental problem which has become increasingly pertinent in recent years with the rise of generative AI, as sophisticated sampling procedures from LLMs have been proposed to solve challenging reasoning problems. The efficacy of such sampling algorithms is limited, however, by the relationship between the LLM and the particular sampling task at hand, which has motivated the framework of test-time training (TTT). TTT works by updating a model's weights in response to partial generations and reward feedback received at inference time, thus adapting to the particular problem. In this work, we propose a formalization for TTT as the problem of producing a sample from a given probability measure $μ^\star$ belonging to a known class ${F}$ of distributions, given an oracle $\hat μ$ which yields approximate density estimates for $μ^\star$. This is closely related to the problem of reducing sampling to approximate counting studied in seminal works of Jerrum, Valiant & Vazirani (1986) and Jerrum & Sinclair (1989): namely, when ${F}$ is the class of all distributions, it coincides exactly with the aforementioned counting-to-sampling reduction. In this paper, we first show a quadratic lower bound on the query complexity of sampling from $μ^\star$ given query access to $\hat μ$ (for sufficiently large classes ${F}$), thus showing that the random walk approach proposed by Jerrum & Sinclair (1989) and refined by Hayes & Sinclair (2010), is optimal. This answers an open question posed by Hayes & Sinclair. We then show that this lower bound can be circumvented if the size of ${F}$ is bounded appropriately. As we discuss, this latter result can be viewed as an abstraction of TTT, and thus represents a starting point for the development of a principled theoretical framework for TTT.
Learning $\mathsf{AC}^0$ Under Graphical Models
Apr 07, 2026In a landmark result, Linial, Mansour and Nisan (J. ACM 1993) gave a quasipolynomial-time algorithm for learning constant-depth circuits given labeled i.i.d. samples under the uniform distribution. Their work has had a deep and lasting legacy in computational learning theory, in particular introducing the $\textit{low-degree algorithm}$. However, an important critique of many results and techniques in the area is the reliance on product structure, which is unlikely to hold in realistic settings. Obtaining similar learning guarantees for more natural correlated distributions has been a longstanding challenge in the field. In particular, we give quasipolynomial-time algorithms for learning $\mathsf{AC}^0$ substantially beyond the product setting, when the inputs come from any graphical model with polynomial growth that exhibits strong spatial mixing. The main technical challenge is in giving a workaround to Fourier analysis, which we do by showing how new sampling algorithms allow us to transfer statements about low-degree polynomial approximation under the uniform setting to graphical models. Our approach is general enough to extend to other well-studied function classes, like monotone functions and halfspaces.
Steering diffusion models with quadratic rewards: a fine-grained analysis
Feb 18, 2026Inference-time algorithms are an emerging paradigm in which pre-trained models are used as subroutines to solve downstream tasks. Such algorithms have been proposed for tasks ranging from inverse problems and guided image generation to reasoning. However, the methods currently deployed in practice are heuristics with a variety of failure modes -- and we have very little understanding of when these heuristics can be efficiently improved. In this paper, we consider the task of sampling from a reward-tilted diffusion model -- that is, sampling from $p^{\star}(x) \propto p(x) \exp(r(x))$ -- given a reward function $r$ and pre-trained diffusion oracle for $p$. We provide a fine-grained analysis of the computational tractability of this task for quadratic rewards $r(x) = x^\top A x + b^\top x$. We show that linear-reward tilts are always efficiently sampleable -- a simple result that seems to have gone unnoticed in the literature. We use this as a building block, along with a conceptually new ingredient -- the Hubbard-Stratonovich transform -- to provide an efficient algorithm for sampling from low-rank positive-definite quadratic tilts, i.e. $r(x) = x^\top A x$ where $A$ is positive-definite and of rank $O(1)$. For negative-definite tilts, i.e. $r(x) = - x^\top A x$ where $A$ is positive-definite, we prove that the problem is intractable even if $A$ is of rank 1 (albeit with exponentially-large entries).
Subliminal Effects in Your Data: A General Mechanism via Log-Linearity
Feb 04, 2026Training modern large language models (LLMs) has become a veritable smorgasbord of algorithms and datasets designed to elicit particular behaviors, making it critical to develop techniques to understand the effects of datasets on the model's properties. This is exacerbated by recent experiments that show datasets can transmit signals that are not directly observable from individual datapoints, posing a conceptual challenge for dataset-centric understandings of LLM training and suggesting a missing fundamental account of such phenomena. Towards understanding such effects, inspired by recent work on the linear structure of LLMs, we uncover a general mechanism through which hidden subtexts can arise in generic datasets. We introduce Logit-Linear-Selection (LLS), a method that prescribes how to select subsets of a generic preference dataset to elicit a wide range of hidden effects. We apply LLS to discover subsets of real-world datasets so that models trained on them exhibit behaviors ranging from having specific preferences, to responding to prompts in a different language not present in the dataset, to taking on a different persona. Crucially, the effect persists for the selected subset, across models with varying architectures, supporting its generality and universality.
Overcomplete Tensor Decomposition via Koszul-Young Flattenings
Nov 21, 2024Motivated by connections between algebraic complexity lower bounds and tensor decompositions, we investigate Koszul-Young flattenings, which are the main ingredient in recent lower bounds for matrix multiplication. Based on this tool we give a new algorithm for decomposing an $n_1 \times n_2 \times n_3$ tensor as the sum of a minimal number of rank-1 terms, and certifying uniqueness of this decomposition. For $n_1 \le n_2 \le n_3$ with $n_1 \to \infty$ and $n_3/n_2 = O(1)$, our algorithm is guaranteed to succeed when the tensor rank is bounded by $r \le (1-\epsilon)(n_2 + n_3)$ for an arbitrary $\epsilon > 0$, provided the tensor components are generically chosen. For any fixed $\epsilon$, the runtime is polynomial in $n_3$. When $n_2 = n_3 = n$, our condition on the rank gives a factor-of-2 improvement over the classical simultaneous diagonalization algorithm, which requires $r \le n$, and also improves on the recent algorithm of Koiran (2024) which requires $r \le 4n/3$. It also improves on the PhD thesis of Persu (2018) which solves rank detection for $r \leq 3n/2$. We complement our upper bounds by showing limitations, in particular that no flattening of the style we consider can surpass rank $n_2 + n_3$. Furthermore, for $n \times n \times n$ tensors, we show that an even more general class of degree-$d$ polynomial flattenings cannot surpass rank $Cn$ for a constant $C = C(d)$. This suggests that for tensor decompositions, the case of generic components may be fundamentally harder than that of random components, where efficient decomposition is possible even in highly overcomplete settings.
Model Stealing for Any Low-Rank Language Model
Nov 12, 2024Model stealing, where a learner tries to recover an unknown model via carefully chosen queries, is a critical problem in machine learning, as it threatens the security of proprietary models and the privacy of data they are trained on. In recent years, there has been particular interest in stealing large language models (LLMs). In this paper, we aim to build a theoretical understanding of stealing language models by studying a simple and mathematically tractable setting. We study model stealing for Hidden Markov Models (HMMs), and more generally low-rank language models. We assume that the learner works in the conditional query model, introduced by Kakade, Krishnamurthy, Mahajan and Zhang. Our main result is an efficient algorithm in the conditional query model, for learning any low-rank distribution. In other words, our algorithm succeeds at stealing any language model whose output distribution is low-rank. This improves upon the previous result by Kakade, Krishnamurthy, Mahajan and Zhang, which also requires the unknown distribution to have high "fidelity", a property that holds only in restricted cases. There are two key insights behind our algorithm: First, we represent the conditional distributions at each timestep by constructing barycentric spanners among a collection of vectors of exponentially large dimension. Second, for sampling from our representation, we iteratively solve a sequence of convex optimization problems that involve projection in relative entropy to prevent compounding of errors over the length of the sequence. This is an interesting example where, at least theoretically, allowing a machine learning model to solve more complex problems at inference time can lead to drastic improvements in its performance.
Towards characterizing the value of edge embeddings in Graph Neural Networks
Oct 13, 2024Graph neural networks (GNNs) are the dominant approach to solving machine learning problems defined over graphs. Despite much theoretical and empirical work in recent years, our understanding of finer-grained aspects of architectural design for GNNs remains impoverished. In this paper, we consider the benefits of architectures that maintain and update edge embeddings. On the theoretical front, under a suitable computational abstraction for a layer in the model, as well as memory constraints on the embeddings, we show that there are natural tasks on graphical models for which architectures leveraging edge embeddings can be much shallower. Our techniques are inspired by results on time-space tradeoffs in theoretical computer science. Empirically, we show architectures that maintain edge embeddings almost always improve on their node-based counterparts -- frequently significantly so in topologies that have ``hub'' nodes.
Efficiently Learning Markov Random Fields from Dynamics
Sep 09, 2024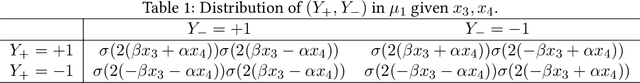
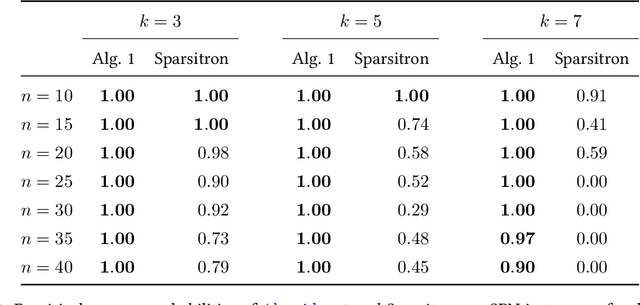
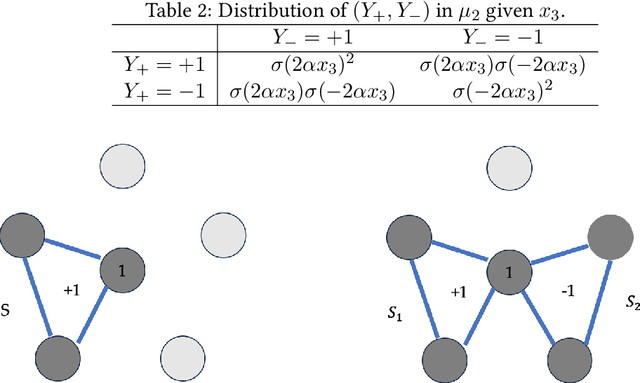
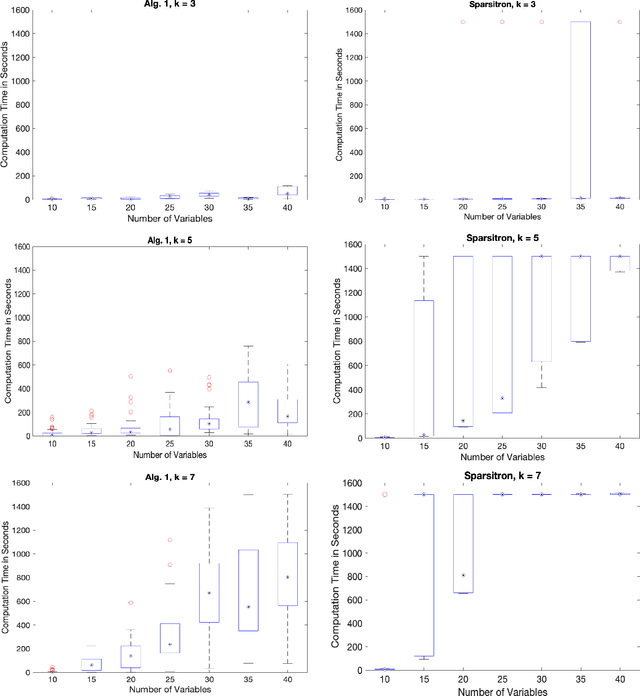
An important task in high-dimensional statistics is learning the parameters or dependency structure of an undirected graphical model, or Markov random field (MRF). Much of the prior work on this problem assumes access to i.i.d. samples from the MRF distribution and state-of-the-art algorithms succeed using $n^{\Theta(k)}$ runtime, where $n$ is the dimension and $k$ is the order of the interactions. However, well-known reductions from the sparse parity with noise problem imply that given i.i.d. samples from a sparse, order-$k$ MRF, any learning algorithm likely requires $n^{\Omega(k)}$ time, impeding the potential for significant computational improvements. In this work, we demonstrate that these fundamental barriers for learning MRFs can surprisingly be completely circumvented when learning from natural, dynamical samples. We show that in bounded-degree MRFs, the dependency structure and parameters can be recovered using a trajectory of Glauber dynamics of length $O(n \log n)$ with runtime $O(n^2 \log n)$. The implicit constants depend only on the degree and non-degeneracy parameters of the model, but not the dimension $n$. In particular, learning MRFs from dynamics is $\textit{provably computationally easier}$ than learning from i.i.d. samples under standard hardness assumptions.
Linear Bellman Completeness Suffices for Efficient Online Reinforcement Learning with Few Actions
Jun 18, 2024One of the most natural approaches to reinforcement learning (RL) with function approximation is value iteration, which inductively generates approximations to the optimal value function by solving a sequence of regression problems. To ensure the success of value iteration, it is typically assumed that Bellman completeness holds, which ensures that these regression problems are well-specified. We study the problem of learning an optimal policy under Bellman completeness in the online model of RL with linear function approximation. In the linear setting, while statistically efficient algorithms are known under Bellman completeness (e.g., Jiang et al. (2017); Zanette et al. (2020)), these algorithms all rely on the principle of global optimism which requires solving a nonconvex optimization problem. In particular, it has remained open as to whether computationally efficient algorithms exist. In this paper we give the first polynomial-time algorithm for RL under linear Bellman completeness when the number of actions is any constant.
The Role of Inherent Bellman Error in Offline Reinforcement Learning with Linear Function Approximation
Jun 18, 2024In this paper, we study the offline RL problem with linear function approximation. Our main structural assumption is that the MDP has low inherent Bellman error, which stipulates that linear value functions have linear Bellman backups with respect to the greedy policy. This assumption is natural in that it is essentially the minimal assumption required for value iteration to succeed. We give a computationally efficient algorithm which succeeds under a single-policy coverage condition on the dataset, namely which outputs a policy whose value is at least that of any policy which is well-covered by the dataset. Even in the setting when the inherent Bellman error is 0 (termed linear Bellman completeness), our algorithm yields the first known guarantee under single-policy coverage. In the setting of positive inherent Bellman error ${\varepsilon_{\mathrm{BE}}} > 0$, we show that the suboptimality error of our algorithm scales with $\sqrt{\varepsilon_{\mathrm{BE}}}$. Furthermore, we prove that the scaling of the suboptimality with $\sqrt{\varepsilon_{\mathrm{BE}}}$ cannot be improved for any algorithm. Our lower bound stands in contrast to many other settings in reinforcement learning with misspecification, where one can typically obtain performance that degrades linearly with the misspecification error.