 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Complexity of Statistics: New Insights from Low-Degree Polynomials
Jun 12, 2025This is a survey on the use of low-degree polynomials to predict and explain the apparent statistical-computational tradeoffs in a variety of average-case computational problems. In a nutshell, this framework measures the complexity of a statistical task by the minimum degree that a polynomial function must have in order to solve it. The main goals of this survey are to (1) describe the types of problems where the low-degree framework can be applied, encompassing questions of detection (hypothesis testing), recovery (estimation), and more; (2) discuss some philosophical questions surrounding the interpretation of low-degree lower bounds, and notably the extent to which they should be treated as evidence for inherent computational hardness; (3) explore the known connections between low-degree polynomials and other related approaches such as the sum-of-squares hierarchy and statistical query model; and (4) give an overview of the mathematical tools used to prove low-degree lower bounds. A list of open problems is also included.
Overcomplete Tensor Decomposition via Koszul-Young Flattenings
Nov 21, 2024Motivated by connections between algebraic complexity lower bounds and tensor decompositions, we investigate Koszul-Young flattenings, which are the main ingredient in recent lower bounds for matrix multiplication. Based on this tool we give a new algorithm for decomposing an $n_1 \times n_2 \times n_3$ tensor as the sum of a minimal number of rank-1 terms, and certifying uniqueness of this decomposition. For $n_1 \le n_2 \le n_3$ with $n_1 \to \infty$ and $n_3/n_2 = O(1)$, our algorithm is guaranteed to succeed when the tensor rank is bounded by $r \le (1-\epsilon)(n_2 + n_3)$ for an arbitrary $\epsilon > 0$, provided the tensor components are generically chosen. For any fixed $\epsilon$, the runtime is polynomial in $n_3$. When $n_2 = n_3 = n$, our condition on the rank gives a factor-of-2 improvement over the classical simultaneous diagonalization algorithm, which requires $r \le n$, and also improves on the recent algorithm of Koiran (2024) which requires $r \le 4n/3$. It also improves on the PhD thesis of Persu (2018) which solves rank detection for $r \leq 3n/2$. We complement our upper bounds by showing limitations, in particular that no flattening of the style we consider can surpass rank $n_2 + n_3$. Furthermore, for $n \times n \times n$ tensors, we show that an even more general class of degree-$d$ polynomial flattenings cannot surpass rank $Cn$ for a constant $C = C(d)$. This suggests that for tensor decompositions, the case of generic components may be fundamentally harder than that of random components, where efficient decomposition is possible even in highly overcomplete settings.
Tensor cumulants for statistical inference on invariant distributions
Apr 29, 2024

Many problems in high-dimensional statistics appear to have a statistical-computational gap: a range of values of the signal-to-noise ratio where inference is information-theoretically possible, but (conjecturally) computationally intractable. A canonical such problem is Tensor PCA, where we observe a tensor $Y$ consisting of a rank-one signal plus Gaussian noise. Multiple lines of work suggest that Tensor PCA becomes computationally hard at a critical value of the signal's magnitude. In particular, below this transition, no low-degree polynomial algorithm can detect the signal with high probability; conversely, various spectral algorithms are known to succeed above this transition. We unify and extend this work by considering tensor networks, orthogonally invariant polynomials where multiple copies of $Y$ are "contracted" to produce scalars, vectors, matrices, or other tensors. We define a new set of objects, tensor cumulants, which provide an explicit, near-orthogonal basis for invariant polynomials of a given degree. This basis lets us unify and strengthen previous results on low-degree hardness, giving a combinatorial explanation of the hardness transition and of a continuum of subexponential-time algorithms that work below it, and proving tight lower bounds against low-degree polynomials for recovering rather than just detecting the signal. It also lets us analyze a new problem of distinguishing between different tensor ensembles, such as Wigner and Wishart tensors, establishing a sharp computational threshold and giving evidence of a new statistical-computational gap in the Central Limit Theorem for random tensors. Finally, we believe these cumulants are valuable mathematical objects in their own right: they generalize the free cumulants of free probability theory from matrices to tensors, and share many of their properties, including additivity under additive free convolution.
Low-degree phase transitions for detecting a planted clique in sublinear time
Feb 08, 2024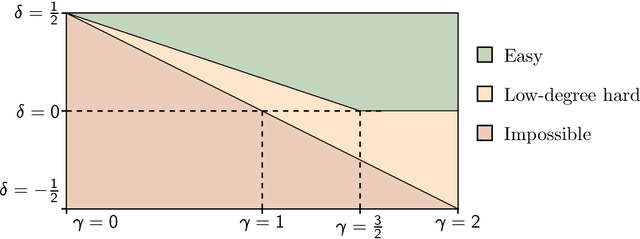
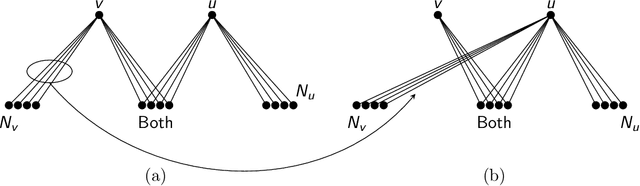
We consider the problem of detecting a planted clique of size $k$ in a random graph on $n$ vertices. When the size of the clique exceeds $\Theta(\sqrt{n})$, polynomial-time algorithms for detection proliferate. We study faster -- namely, sublinear time -- algorithms in the high-signal regime when $k = \Theta(n^{1/2 + \delta})$, for some $\delta > 0$. To this end, we consider algorithms that non-adaptively query a subset $M$ of entries of the adjacency matrix and then compute a low-degree polynomial function of the revealed entries. We prove a computational phase transition for this class of non-adaptive low-degree algorithms: under the scaling $\lvert M \rvert = \Theta(n^{\gamma})$, the clique can be detected when $\gamma > 3(1/2 - \delta)$ but not when $\gamma < 3(1/2 - \delta)$. As a result, the best known runtime for detecting a planted clique, $\widetilde{O}(n^{3(1/2-\delta)})$, cannot be improved without looking beyond the non-adaptive low-degree class. Our proof of the lower bound -- based on bounding the conditional low-degree likelihood ratio -- reveals further structure in non-adaptive detection of a planted clique. Using (a bound on) the conditional low-degree likelihood ratio as a potential function, we show that for every non-adaptive query pattern, there is a highly structured query pattern of the same size that is at least as effective.
Information-Theoretic Thresholds for Planted Dense Cycles
Feb 01, 2024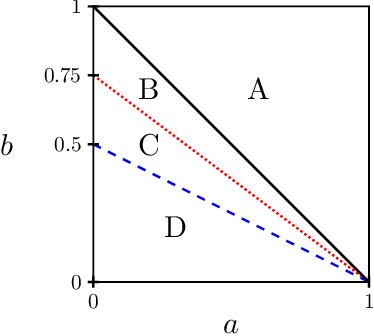
We study a random graph model for small-world networks which are ubiquitous in social and biological sciences. In this model, a dense cycle of expected bandwidth $n \tau$, representing the hidden one-dimensional geometry of vertices, is planted in an ambient random graph on $n$ vertices. For both detection and recovery of the planted dense cycle, we characterize the information-theoretic thresholds in terms of $n$, $\tau$, and an edge-wise signal-to-noise ratio $\lambda$. In particular, the information-theoretic thresholds differ from the computational thresholds established in a recent work for low-degree polynomial algorithms, thereby justifying the existence of statistical-to-computational gaps for this problem.
Precise Error Rates for Computationally Efficient Testing
Nov 01, 2023We revisit the fundamental question of simple-versus-simple hypothesis testing with an eye towards computational complexity, as the statistically optimal likelihood ratio test is often computationally intractable in high-dimensional settings. In the classical spiked Wigner model (with a general i.i.d. spike prior) we show that an existing test based on linear spectral statistics achieves the best possible tradeoff curve between type I and type II error rates among all computationally efficient tests, even though there are exponential-time tests that do better. This result is conditional on an appropriate complexity-theoretic conjecture, namely a natural strengthening of the well-established low-degree conjecture. Our result shows that the spectrum is a sufficient statistic for computationally bounded tests (but not for all tests). To our knowledge, our approach gives the first tool for reasoning about the precise asymptotic testing error achievable with efficient computation. The main ingredients required for our hardness result are a sharp bound on the norm of the low-degree likelihood ratio along with (counterintuitively) a positive result on achievability of testing. This strategy appears to be new even in the setting of unbounded computation, in which case it gives an alternate way to analyze the fundamental statistical limits of testing.
Detection of Dense Subhypergraphs by Low-Degree Polynomials
Apr 17, 2023Detection of a planted dense subgraph in a random graph is a fundamental statistical and computational problem that has been extensively studied in recent years. We study a hypergraph version of the problem. Let $G^r(n,p)$ denote the $r$-uniform Erd\H{o}s-R\'enyi hypergraph model with $n$ vertices and edge density $p$. We consider detecting the presence of a planted $G^r(n^\gamma, n^{-\alpha})$ subhypergraph in a $G^r(n, n^{-\beta})$ hypergraph, where $0< \alpha < \beta < r-1$ and $0 < \gamma < 1$. Focusing on tests that are degree-$n^{o(1)}$ polynomials of the entries of the adjacency tensor, we determine the threshold between the easy and hard regimes for the detection problem. More precisely, for $0 < \gamma < 1/2$, the threshold is given by $\alpha = \beta \gamma$, and for $1/2 \le \gamma < 1$, the threshold is given by $\alpha = \beta/2 + r(\gamma - 1/2)$. Our results are already new in the graph case $r=2$, as we consider the subtle log-density regime where hardness based on average-case reductions is not known. Our proof of low-degree hardness is based on a conditional variant of the standard low-degree likelihood calculation.
Detection-Recovery Gap for Planted Dense Cycles
Feb 13, 2023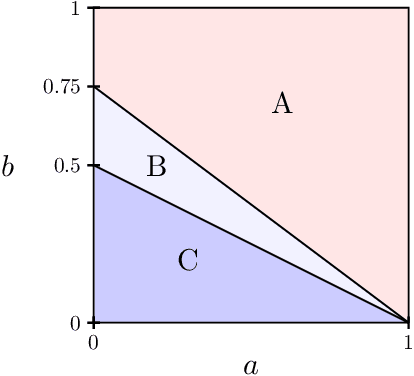
Planted dense cycles are a type of latent structure that appears in many applications, such as small-world networks in social sciences and sequence assembly in computational biology. We consider a model where a dense cycle with expected bandwidth $n \tau$ and edge density $p$ is planted in an Erd\H{o}s-R\'enyi graph $G(n,q)$. We characterize the computational thresholds for the associated detection and recovery problems for the class of low-degree polynomial algorithms. In particular, a gap exists between the two thresholds in a certain regime of parameters. For example, if $n^{-3/4} \ll \tau \ll n^{-1/2}$ and $p = C q = \Theta(1)$ for a constant $C>1$, the detection problem is computationally easy while the recovery problem is hard for low-degree algorithms.
Is it easier to count communities than find them?
Dec 21, 2022
Random graph models with community structure have been studied extensively in the literature. For both the problems of detecting and recovering community structure, an interesting landscape of statistical and computational phase transitions has emerged. A natural unanswered question is: might it be possible to infer properties of the community structure (for instance, the number and sizes of communities) even in situations where actually finding those communities is believed to be computationally hard? We show the answer is no. In particular, we consider certain hypothesis testing problems between models with different community structures, and we show (in the low-degree polynomial framework) that testing between two options is as hard as finding the communities. In addition, our methods give the first computational lower bounds for testing between two different `planted' distributions, whereas previous results have considered testing between a planted distribution and an i.i.d. `null' distribution.
Average-Case Complexity of Tensor Decomposition for Low-Degree Polynomials
Nov 10, 2022Suppose we are given an $n$-dimensional order-3 symmetric tensor $T \in (\mathbb{R}^n)^{\otimes 3}$ that is the sum of $r$ random rank-1 terms. The problem of recovering the rank-1 components is possible in principle when $r \lesssim n^2$ but polynomial-time algorithms are only known in the regime $r \ll n^{3/2}$. Similar "statistical-computational gaps" occur in many high-dimensional inference tasks, and in recent years there has been a flurry of work on explaining the apparent computational hardness in these problems by proving lower bounds against restricted (yet powerful) models of computation such as statistical queries (SQ), sum-of-squares (SoS), and low-degree polynomials (LDP). However, no such prior work exists for tensor decomposition, largely because its hardness does not appear to be explained by a "planted versus null" testing problem. We consider a model for random order-3 tensor decomposition where one component is slightly larger in norm than the rest (to break symmetry), and the components are drawn uniformly from the hypercube. We resolve the computational complexity in the LDP model: $O(\log n)$-degree polynomial functions of the tensor entries can accurately estimate the largest component when $r \ll n^{3/2}$ but fail to do so when $r \gg n^{3/2}$. This provides rigorous evidence suggesting that the best known algorithms for tensor decomposition cannot be improved, at least by known approaches. A natural extension of the result holds for tensors of any fixed order $k \ge 3$, in which case the LDP threshold is $r \sim n^{k/2}$.