 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs it easier to count communities than find them?
Dec 21, 2022
Random graph models with community structure have been studied extensively in the literature. For both the problems of detecting and recovering community structure, an interesting landscape of statistical and computational phase transitions has emerged. A natural unanswered question is: might it be possible to infer properties of the community structure (for instance, the number and sizes of communities) even in situations where actually finding those communities is believed to be computationally hard? We show the answer is no. In particular, we consider certain hypothesis testing problems between models with different community structures, and we show (in the low-degree polynomial framework) that testing between two options is as hard as finding the communities. In addition, our methods give the first computational lower bounds for testing between two different `planted' distributions, whereas previous results have considered testing between a planted distribution and an i.i.d. `null' distribution.
The planted matching problem: Sharp threshold and infinite-order phase transition
Mar 17, 2021
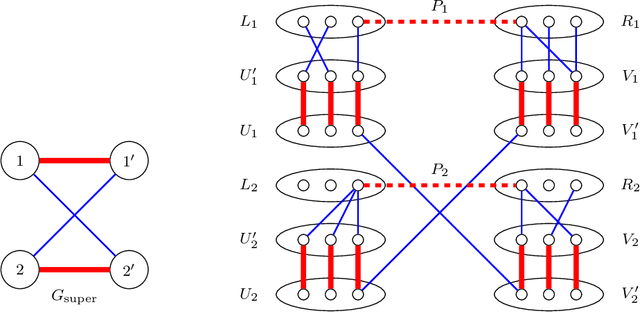

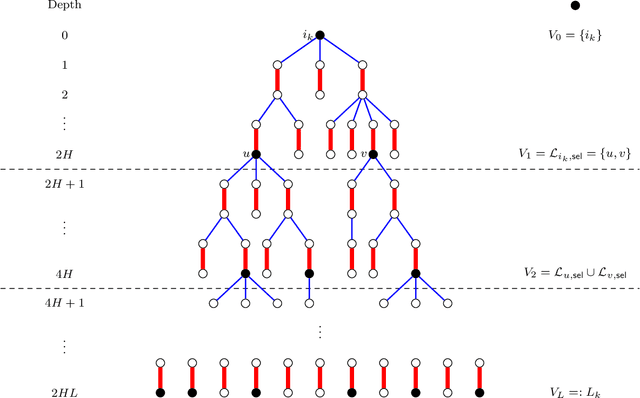
We study the problem of reconstructing a perfect matching $M^*$ hidden in a randomly weighted $n\times n$ bipartite graph. The edge set includes every node pair in $M^*$ and each of the $n(n-1)$ node pairs not in $M^*$ independently with probability $d/n$. The weight of each edge $e$ is independently drawn from the distribution $\mathcal{P}$ if $e \in M^*$ and from $\mathcal{Q}$ if $e \notin M^*$. We show that if $\sqrt{d} B(\mathcal{P},\mathcal{Q}) \le 1$, where $B(\mathcal{P},\mathcal{Q})$ stands for the Bhattacharyya coefficient, the reconstruction error (average fraction of misclassified edges) of the maximum likelihood estimator of $M^*$ converges to $0$ as $n\to \infty$. Conversely, if $\sqrt{d} B(\mathcal{P},\mathcal{Q}) \ge 1+\epsilon$ for an arbitrarily small constant $\epsilon>0$, the reconstruction error for any estimator is shown to be bounded away from $0$ under both the sparse and dense model, resolving the conjecture in [Moharrami et al. 2019, Semerjian et al. 2020]. Furthermore, in the special case of complete exponentially weighted graph with $d=n$, $\mathcal{P}=\exp(\lambda)$, and $\mathcal{Q}=\exp(1/n)$, for which the sharp threshold simplifies to $\lambda=4$, we prove that when $\lambda \le 4-\epsilon$, the optimal reconstruction error is $\exp\left( - \Theta(1/\sqrt{\epsilon}) \right)$, confirming the conjectured infinite-order phase transition in [Semerjian et al. 2020].
Learner-Private Online Convex Optimization
Feb 23, 2021


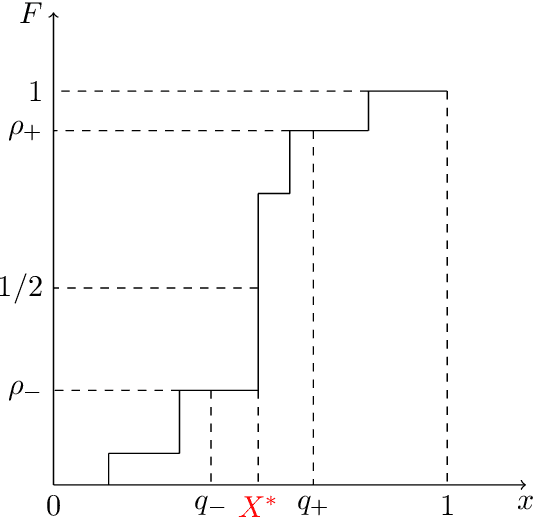
Online convex optimization is a framework where a learner sequentially queries an external data source in order to arrive at the optimal solution of a convex function. The paradigm has gained significant popularity recently thanks to its scalability in large-scale optimization and machine learning. The repeated interactions, however, expose the learner to privacy risks from eavesdropping adversary that observe the submitted queries. In this paper, we study how to optimally obfuscate the learner's queries in first-order online convex optimization, so that their learned optimal value is provably difficult to estimate for the eavesdropping adversary. We consider two formulations of learner privacy: a Bayesian formulation in which the convex function is drawn randomly, and a minimax formulation in which the function is fixed and the adversary's probability of error is measured with respect to a minimax criterion. We show that, if the learner wants to ensure the probability of accurate prediction by the adversary be kept below $1/L$, then the overhead in query complexity is additive in $L$ in the minimax formulation, but multiplicative in $L$ in the Bayesian formulation. Compared to existing learner-private sequential learning models with binary feedback, our results apply to the significantly richer family of general convex functions with full-gradient feedback. Our proofs are largely enabled by tools from the theory of Dirichlet processes, as well as more sophisticated lines of analysis aimed at measuring the amount of information leakage under a full-gradient oracle.
Consistent recovery threshold of hidden nearest neighbor graphs
Nov 18, 2019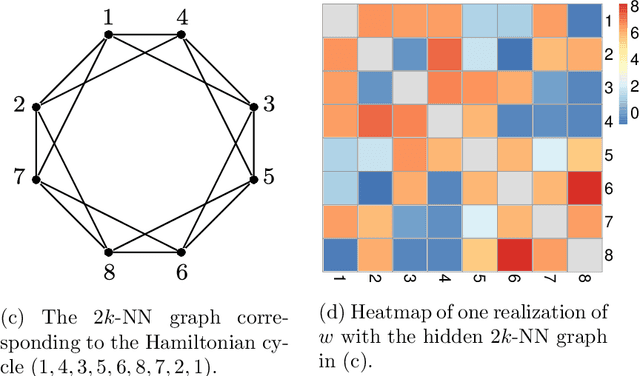
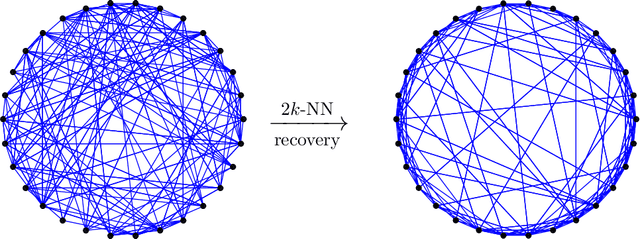


Motivated by applications such as discovering strong ties in social networks and assembling genome subsequences in biology, we study the problem of recovering a hidden $2k$-nearest neighbor (NN) graph in an $n$-vertex complete graph, whose edge weights are independent and distributed according to $P_n$ for edges in the hidden $2k$-NN graph and $Q_n$ otherwise. The special case of Bernoulli distributions corresponds to a variant of the Watts-Strogatz small-world graph. We focus on two types of asymptotic recovery guarantees as $n\to \infty$: (1) exact recovery: all edges are classified correctly with probability tending to one; (2) almost exact recovery: the expected number of misclassified edges is $o(nk)$. We show that the maximum likelihood estimator achieves (1) exact recovery for $2 \le k \le n^{o(1)}$ if $ \liminf \frac{2\alpha_n}{\log n}>1$; (2) almost exact recovery for $ 1 \le k \le o\left( \frac{\log n}{\log \log n} \right)$ if $\liminf \frac{kD(P_n||Q_n)}{\log n}>1$, where $\alpha_n \triangleq -2 \log \int \sqrt{d P_n d Q_n}$ is the R\'enyi divergence of order $\frac{1}{2}$ and $D(P_n||Q_n)$ is the Kullback-Leibler divergence. Under mild distributional assumptions, these conditions are shown to be information-theoretically necessary for any algorithm to succeed. A key challenge in the analysis is the enumeration of $2k$-NN graphs that differ from the hidden one by a given number of edges.
Optimal query complexity for private sequential learning
Sep 21, 2019


Motivated by privacy concerns in many practical applications such as Federated Learning, we study a stylized private sequential learning problem: a learner tries to estimate an unknown scalar value, by sequentially querying an external database and receiving binary responses; meanwhile, a third-party adversary observes the learner's queries but not the responses. The learner's goal is to design a querying strategy with the minimum number of queries (optimal query complexity) so that she can accurately estimate the true value, while the adversary even with the complete knowledge of her querying strategy cannot. Prior work has obtained both upper and lower bounds on the optimal query complexity, however, these upper and lower bounds have a large gap in general. In this paper, we construct new querying strategies and prove almost matching upper and lower bounds, providing a complete characterization of the optimal query complexity as a function of the estimation accuracy and the desired levels of privacy.
Fair quantile regression
Jul 19, 2019


Quantile regression is a tool for learning conditional distributions. In this paper we study quantile regression in the setting where a protected attribute is unavailable when fitting the model. This can lead to "unfair'' quantile estimators for which the effective quantiles are very different for the subpopulations defined by the protected attribute. We propose a procedure for adjusting the estimator on a heldout sample where the protected attribute is available. The main result of the paper is an empirical process analysis showing that the adjustment leads to a fair estimator for which the target quantiles are brought into balance, in a statistical sense that we call $\sqrt{n}$-fairness. We illustrate the ideas and adjustment procedure on a dataset of 200,000 live births, where the objective is to characterize the dependence of the birth weights of the babies on demographic attributes of the birth mother; the protected attribute is the mother's race.
The cost-free nature of optimally tuning Tikhonov regularizers and other ordered smoothers
May 29, 2019We consider the problem of selecting the best estimator among a family of Tikhonov regularized estimators, or, alternatively, to select a linear combination of these regularizers that is as good as the best regularizer in the family. Our theory reveals that if the Tikhonov regularizers share the same penalty matrix with different tuning parameters, a convex procedure based on $Q$-aggregation achieves the mean square error of the best estimator, up to a small error term no larger than $C\sigma^2$, where $\sigma^2$ is the noise level and $C>0$ is an absolute constant. Remarkably, the error term does not depend on the penalty matrix or the number of estimators as long as they share the same penalty matrix, i.e., it applies to any grid of tuning parameters, no matter how large the cardinality of the grid is. This reveals the surprising "cost-free" nature of optimally tuning Tikhonov regularizers, in striking contrast with the existing literature on aggregation of estimators where one typically has to pay a cost of $\sigma^2\log(M)$ where $M$ is the number of estimators in the family. The result holds, more generally, for any family of ordered linear smoothers. This encompasses Ridge regression as well as Principal Component Regression. The result is extended to the problem of tuning Tikhonov regularizers with different penalty matrices.
Estimating the Coefficients of a Mixture of Two Linear Regressions by Expectation Maximization
Oct 16, 2018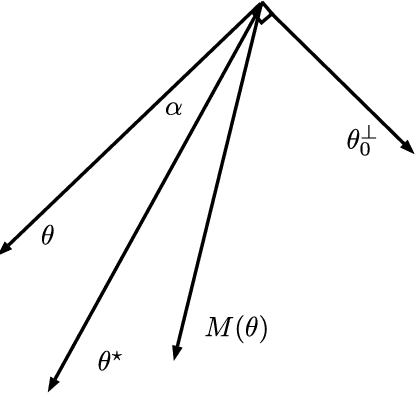
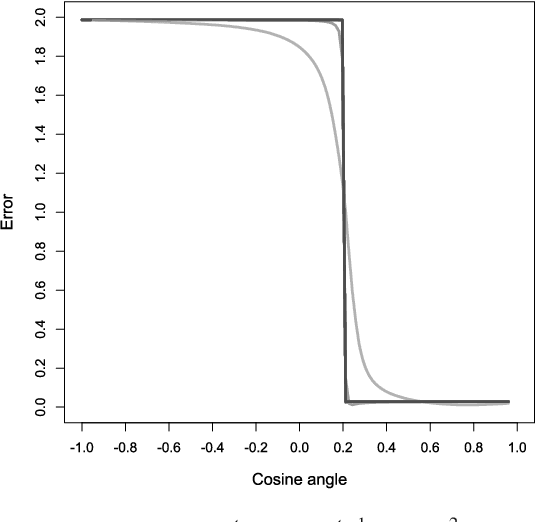
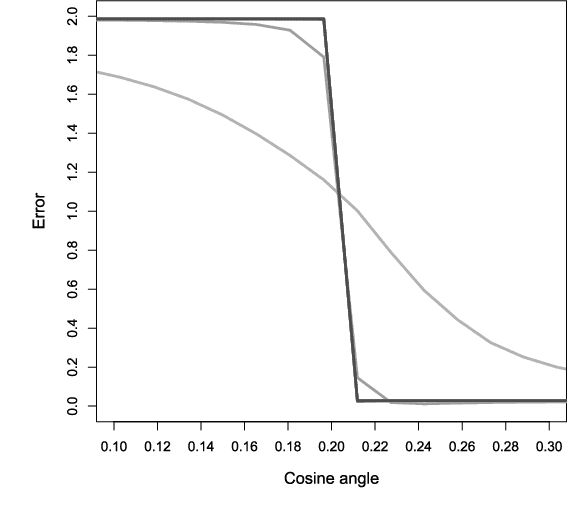
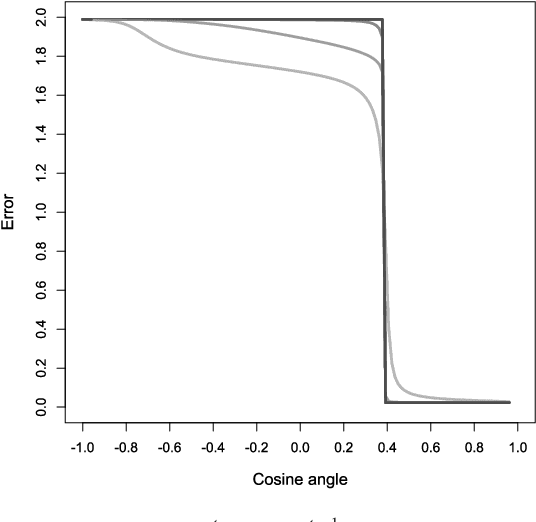
We give convergence guarantees for estimating the coefficients of a symmetric mixture of two linear regressions by expectation maximization (EM). In particular, we show that the empirical EM iterates converge to the target parameter vector at the parametric rate, provided the algorithm is initialized in an unbounded cone. In particular, if the initial guess has a sufficiently large cosine angle with the target parameter vector, a sample-splitting version of the EM algorithm converges to the true coefficient vector with high probability. Interestingly, our analysis borrows from tools used in the problem of estimating the centers of a symmetric mixture of two Gaussians by EM. We also show that the population EM operator for mixtures of two regressions is anti-contractive from the target parameter vector if the cosine angle between the input vector and the target parameter vector is too small, thereby establishing the necessity of our conic condition. Finally, we give empirical evidence supporting this theoretical observation, which suggests that the sample based EM algorithm performs poorly when initial guesses are drawn accordingly. Our simulation study also suggests that the EM algorithm performs well even under model misspecification (i.e., when the covariate and error distributions violate the model assumptions).