 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Inference for Longitudinal Linear Regression
Jan 15, 2026Differential Privacy (DP) provides a rigorous framework for releasing statistics while protecting individual information present in a dataset. Although substantial progress has been made on differentially private linear regression, existing methods almost exclusively address the item-level DP setting, where each user contributes a single observation. Many scientific and economic applications instead involve longitudinal or panel data, in which each user contributes multiple dependent observations. In these settings, item-level DP offers inadequate protection, and user-level DP - shielding an individual's entire trajectory - is the appropriate privacy notion. We develop a comprehensive framework for estimation and inference in longitudinal linear regression under user-level DP. We propose a user-level private regression estimator based on aggregating local regressions, and we establish finite-sample guarantees and asymptotic normality under short-range dependence. For inference, we develop a privatized, bias-corrected covariance estimator that is automatically heteroskedasticity- and autocorrelation-consistent. These results provide the first unified framework for practical user-level DP estimation and inference in longitudinal linear regression under dependence, with strong theoretical guarantees and promising empirical performance.
A theoretical framework for M-posteriors: frequentist guarantees and robustness properties
Oct 01, 2025We provide a theoretical framework for a wide class of generalized posteriors that can be viewed as the natural Bayesian posterior counterpart of the class of M-estimators in the frequentist world. We call the members of this class M-posteriors and show that they are asymptotically normally distributed under mild conditions on the M-estimation loss and the prior. In particular, an M-posterior contracts in probability around a normal distribution centered at an M-estimator, showing frequentist consistency and suggesting some degree of robustness depending on the reference M-estimator. We formalize the robustness properties of the M-posteriors by a new characterization of the posterior influence function and a novel definition of breakdown point adapted for posterior distributions. We illustrate the wide applicability of our theory in various popular models and illustrate their empirical relevance in some numerical examples.
Generalized Linear Models with 1-Bit Measurements: Asymptotics of the Maximum Likelihood Estimator
Jan 09, 2025
This work establishes regularity conditions for consistency and asymptotic normality of the multiple parameter maximum likelihood estimator(MLE) from censored data, where the censoring mechanism is in the form of $1$-bit measurements. The underlying distribution of the uncensored data is assumed to belong to the exponential family, with natural parameters expressed as a linear combination of the predictors, known as generalized linear model (GLM). As part of the analysis, the Fisher information matrix is also derived for both censored and uncensored data, which helps to quantify the impact of censoring and assess the performance of the MLE. The choice of GLM allows one to consider a variety of practical examples where 1-bit estimation is of interest. In particular, it is shown how the derived results can be used to analyze two practically relevant scenarios: the Gaussian model with both unknown mean and variance, and the Poisson model with an unknown mean.
Max-sliced Wasserstein concentration and uniform ratio bounds of empirical measures on RKHS
May 21, 2024Optimal transport and the Wasserstein distance $\mathcal{W}_p$ have recently seen a number of applications in the fields of statistics, machine learning, data science, and the physical sciences. These applications are however severely restricted by the curse of dimensionality, meaning that the number of data points needed to estimate these problems accurately increases exponentially in the dimension. To alleviate this problem, a number of variants of $\mathcal{W}_p$ have been introduced. We focus here on one of these variants, namely the max-sliced Wasserstein metric $\overline{\mathcal{W}}_p$. This metric reduces the high-dimensional minimization problem given by $\mathcal{W}_p$ to a maximum of one-dimensional measurements in an effort to overcome the curse of dimensionality. In this note we derive concentration results and upper bounds on the expectation of $\overline{\mathcal{W}}_p$ between the true and empirical measure on unbounded reproducing kernel Hilbert spaces. We show that, under quite generic assumptions, probability measures concentrate uniformly fast in one-dimensional subspaces, at (nearly) parametric rates. Our results rely on an improvement of currently known bounds for $\overline{\mathcal{W}}_p$ in the finite-dimensional case.
Is it easier to count communities than find them?
Dec 21, 2022
Random graph models with community structure have been studied extensively in the literature. For both the problems of detecting and recovering community structure, an interesting landscape of statistical and computational phase transitions has emerged. A natural unanswered question is: might it be possible to infer properties of the community structure (for instance, the number and sizes of communities) even in situations where actually finding those communities is believed to be computationally hard? We show the answer is no. In particular, we consider certain hypothesis testing problems between models with different community structures, and we show (in the low-degree polynomial framework) that testing between two options is as hard as finding the communities. In addition, our methods give the first computational lower bounds for testing between two different `planted' distributions, whereas previous results have considered testing between a planted distribution and an i.i.d. `null' distribution.
Entropic CLT for Order Statistics
May 10, 2022It is well known that central order statistics exhibit a central limit behavior and converge to a Gaussian distribution as the sample size grows. This paper strengthens this known result by establishing an entropic version of the CLT that ensures a stronger mode of convergence using the relative entropy. In particular, an order $O(1/\sqrt{n})$ rate of convergence is established under mild conditions on the parent distribution of the sample generating the order statistics. To prove this result, ancillary results on order statistics are derived, which might be of independent interest.
Characterizing the SLOPE Trade-off: A Variational Perspective and the Donoho-Tanner Limit
May 27, 2021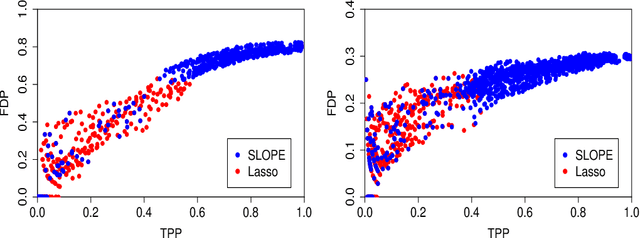
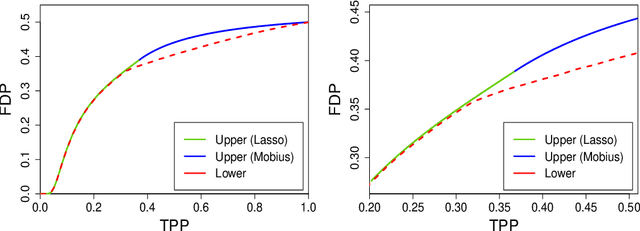
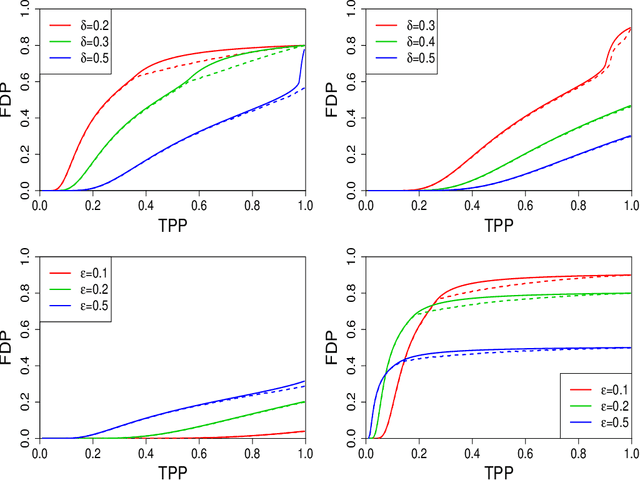
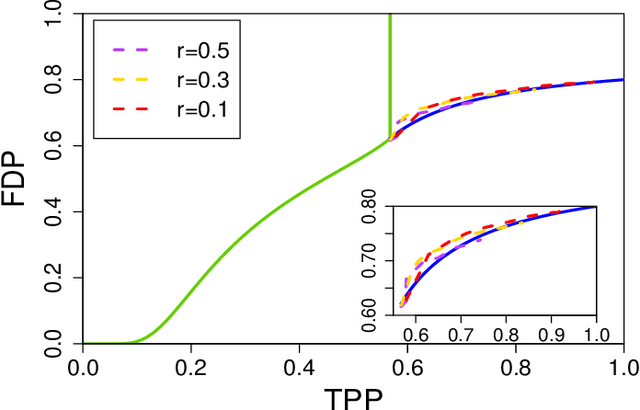
Sorted l1 regularization has been incorporated into many methods for solving high-dimensional statistical estimation problems, including the SLOPE estimator in linear regression. In this paper, we study how this relatively new regularization technique improves variable selection by characterizing the optimal SLOPE trade-off between the false discovery proportion (FDP) and true positive proportion (TPP) or, equivalently, between measures of type I error and power. Assuming a regime of linear sparsity and working under Gaussian random designs, we obtain an upper bound on the optimal trade-off for SLOPE, showing its capability of breaking the Donoho-Tanner power limit. To put it into perspective, this limit is the highest possible power that the Lasso, which is perhaps the most popular l1-based method, can achieve even with arbitrarily strong effect sizes. Next, we derive a tight lower bound that delineates the fundamental limit of sorted l1 regularization in optimally trading the FDP off for the TPP. Finally, we show that on any problem instance, SLOPE with a certain regularization sequence outperforms the Lasso, in the sense of having a smaller FDP, larger TPP and smaller l2 estimation risk simultaneously. Our proofs are based on a novel technique that reduces a variational calculus problem to a class of infinite-dimensional convex optimization problems and a very recent result from approximate message passing theory.
A unifying tutorial on Approximate Message Passing
May 05, 2021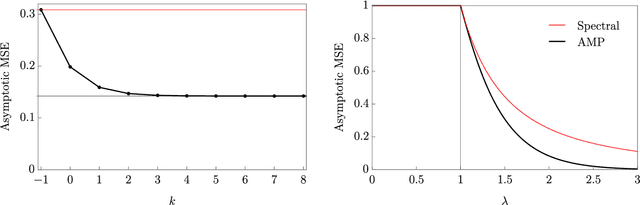

Over the last decade or so, Approximate Message Passing (AMP) algorithms have become extremely popular in various structured high-dimensional statistical problems. The fact that the origins of these techniques can be traced back to notions of belief propagation in the statistical physics literature lends a certain mystique to the area for many statisticians. Our goal in this work is to present the main ideas of AMP from a statistical perspective, to illustrate the power and flexibility of the AMP framework. Along the way, we strengthen and unify many of the results in the existing literature.
On the Robustness to Misspecification of $α$-Posteriors and Their Variational Approximations
Apr 16, 2021$\alpha$-posteriors and their variational approximations distort standard posterior inference by downweighting the likelihood and introducing variational approximation errors. We show that such distortions, if tuned appropriately, reduce the Kullback-Leibler (KL) divergence from the true, but perhaps infeasible, posterior distribution when there is potential parametric model misspecification. To make this point, we derive a Bernstein-von Mises theorem showing convergence in total variation distance of $\alpha$-posteriors and their variational approximations to limiting Gaussian distributions. We use these distributions to evaluate the KL divergence between true and reported posteriors. We show this divergence is minimized by choosing $\alpha$ strictly smaller than one, assuming there is a vanishingly small probability of model misspecification. The optimized value becomes smaller as the the misspecification becomes more severe. The optimized KL divergence increases logarithmically in the degree of misspecification and not linearly as with the usual posterior.
All-or-nothing statistical and computational phase transitions in sparse spiked matrix estimation
Jun 14, 2020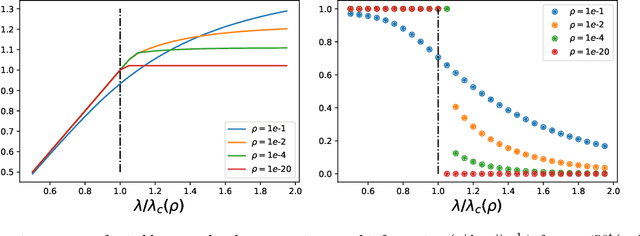

We determine statistical and computational limits for estimation of a rank-one matrix (the spike) corrupted by an additive gaussian noise matrix, in a sparse limit, where the underlying hidden vector (that constructs the rank-one matrix) has a number of non-zero components that scales sub-linearly with the total dimension of the vector, and the signal-to-noise ratio tends to infinity at an appropriate speed. We prove explicit low-dimensional variational formulas for the asymptotic mutual information between the spike and the observed noisy matrix and analyze the approximate message passing algorithm in the sparse regime. For Bernoulli and Bernoulli-Rademacher distributed vectors, and when the sparsity and signal strength satisfy an appropriate scaling relation, we find all-or-nothing phase transitions for the asymptotic minimum and algorithmic mean-square errors. These jump from their maximum possible value to zero, at well defined signal-to-noise thresholds whose asymptotic values we determine exactly. In the asymptotic regime the statistical-to-algorithmic gap diverges indicating that sparse recovery is hard for approximate message passing.