 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp feature-learning transitions and Bayes-optimal neural scaling laws in extensive-width networks
May 11, 2026We study the information-theoretic limits of learning a one-hidden-layer teacher network with hierarchical features from noisy queries, in the context of knowledge transfer to a smaller student model. We work in the high-dimensional regime where the teacher width $k$ scales linearly with the input dimension $d$ -- a setting that captures large-but-finite-width networks and has only recently become analytically tractable. Using a heuristic leave-one-out decoupling argument, validated numerically throughout, we derive asymptotically sharp characterizations of the Bayes-optimal generalization error and individual feature overlaps via a system of closed fixed-point equations. These equations reveal that feature learnability is governed by a sequence of sharp phase transitions: as data grows, teacher features become recoverable sequentially, each through a discontinuous jump in overlap. This sequential acquisition underlies a precise notion of \textit{effective width} $k_c$ -- the number of learnable features at a given data budget $n$ -- which unifies two distinct scaling regimes: a feature-learning regime in which the Bayes-optimal generalization error $\varepsilon^{\rm BO}$ scales as $ n^{1/(2β)-1}$, and a refinement regime in which it scales as $n^{-1}$, where $β>1/2$ is the exponent of the power-law feature hierarchy. Both laws collapse to the single relation $\varepsilon^{\rm BO}=Θ(k_c d/n)$. We further show empirically that a student trained with \textsc{Adam} near the effective width $k_c$ achieves these optimal scaling laws (up to a small algorithmic gap), and provide an information-theoretic account of the associated scaling in model size.
When pre-training hurts LoRA fine-tuning: a dynamical analysis via single-index models
Feb 02, 2026Pre-training on a source task is usually expected to facilitate fine-tuning on similar downstream problems. In this work, we mathematically show that this naive intuition is not always true: excessive pre-training can computationally slow down fine-tuning optimization. We study this phenomenon for low-rank adaptation (LoRA) fine-tuning on single-index models trained under one-pass SGD. Leveraging a summary statistics description of the fine-tuning dynamics, we precisely characterize how the convergence rate depends on the initial fine-tuning alignment and the degree of non-linearity of the target task. The key take away is that even when the pre-training and down- stream tasks are well aligned, strong pre-training can induce a prolonged search phase and hinder convergence. Our theory thus provides a unified picture of how pre-training strength and task difficulty jointly shape the dynamics and limitations of LoRA fine-tuning in a nontrivial tractable model.
Statistical mechanics of extensive-width Bayesian neural networks near interpolation
May 30, 2025For three decades statistical mechanics has been providing a framework to analyse neural networks. However, the theoretically tractable models, e.g., perceptrons, random features models and kernel machines, or multi-index models and committee machines with few neurons, remained simple compared to those used in applications. In this paper we help reducing the gap between practical networks and their theoretical understanding through a statistical physics analysis of the supervised learning of a two-layer fully connected network with generic weight distribution and activation function, whose hidden layer is large but remains proportional to the inputs dimension. This makes it more realistic than infinitely wide networks where no feature learning occurs, but also more expressive than narrow ones or with fixed inner weights. We focus on the Bayes-optimal learning in the teacher-student scenario, i.e., with a dataset generated by another network with the same architecture. We operate around interpolation, where the number of trainable parameters and of data are comparable and feature learning emerges. Our analysis uncovers a rich phenomenology with various learning transitions as the number of data increases. In particular, the more strongly the features (i.e., hidden neurons of the target) contribute to the observed responses, the less data is needed to learn them. Moreover, when the data is scarce, the model only learns non-linear combinations of the teacher weights, rather than "specialising" by aligning its weights with the teacher's. Specialisation occurs only when enough data becomes available, but it can be hard to find for practical training algorithms, possibly due to statistical-to-computational~gaps.
Information-theoretic reduction of deep neural networks to linear models in the overparametrized proportional regime
May 06, 2025We rigorously analyse fully-trained neural networks of arbitrary depth in the Bayesian optimal setting in the so-called proportional scaling regime where the number of training samples and width of the input and all inner layers diverge proportionally. We prove an information-theoretic equivalence between the Bayesian deep neural network model trained from data generated by a teacher with matching architecture, and a simpler model of optimal inference in a generalized linear model. This equivalence enables us to compute the optimal generalization error for deep neural networks in this regime. We thus prove the "deep Gaussian equivalence principle" conjectured in Cui et al. (2023) (arXiv:2302.00375). Our result highlights that in order to escape this "trivialisation" of deep neural networks (in the sense of reduction to a linear model) happening in the strongly overparametrized proportional regime, models trained from much more data have to be considered.
Optimal generalisation and learning transition in extensive-width shallow neural networks near interpolation
Jan 30, 2025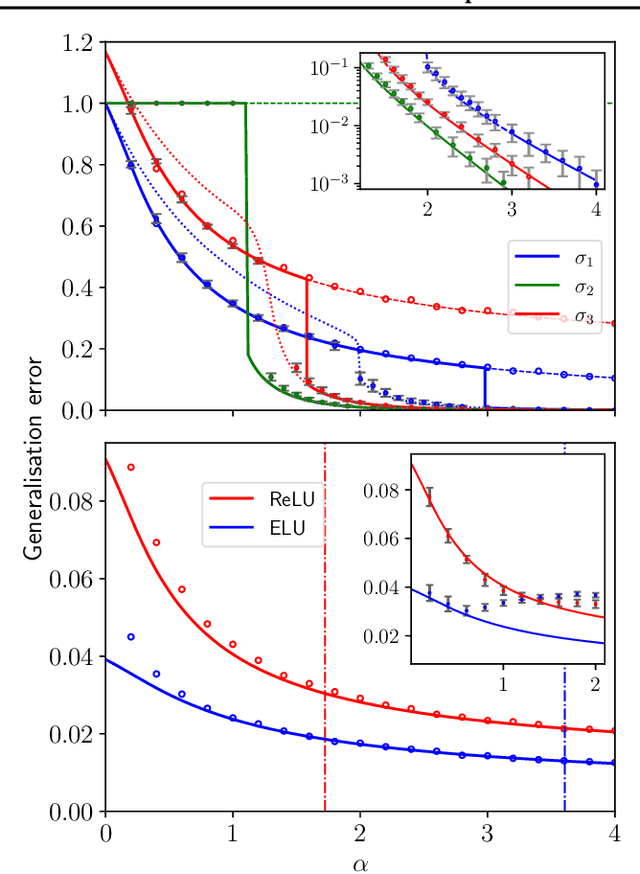

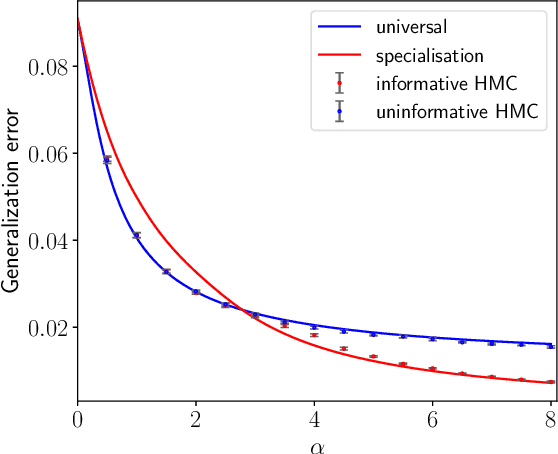
We consider a teacher-student model of supervised learning with a fully-trained 2-layer neural network whose width $k$ and input dimension $d$ are large and proportional. We compute the Bayes-optimal generalisation error of the network for any activation function in the regime where the number of training data $n$ scales quadratically with the input dimension, i.e., around the interpolation threshold where the number of trainable parameters $kd+k$ and of data points $n$ are comparable. Our analysis tackles generic weight distributions. Focusing on binary weights, we uncover a discontinuous phase transition separating a "universal" phase from a "specialisation" phase. In the first, the generalisation error is independent of the weight distribution and decays slowly with the sampling rate $n/d^2$, with the student learning only some non-linear combinations of the teacher weights. In the latter, the error is weight distribution-dependent and decays faster due to the alignment of the student towards the teacher network. We thus unveil the existence of a highly predictive solution near interpolation, which is however potentially hard to find.
Machine learning for cerebral blood vessels' malformations
Nov 25, 2024
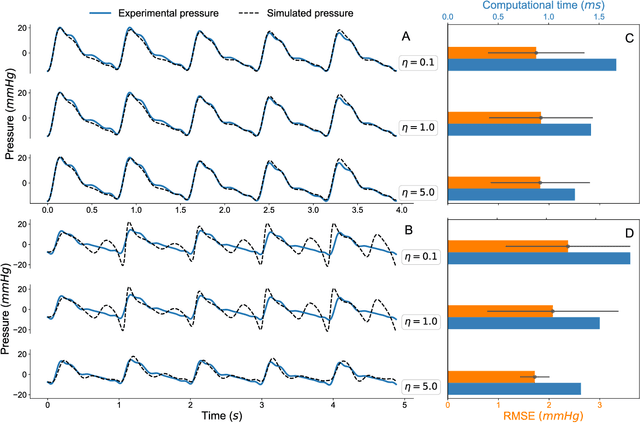


Cerebral aneurysms and arteriovenous malformations are life-threatening hemodynamic pathologies of the brain. While surgical intervention is often essential to prevent fatal outcomes, it carries significant risks both during the procedure and in the postoperative period, making the management of these conditions highly challenging. Parameters of cerebral blood flow, routinely monitored during medical interventions, could potentially be utilized in machine learning-assisted protocols for risk assessment and therapeutic prognosis. To this end, we developed a linear oscillatory model of blood velocity and pressure for clinical data acquired from neurosurgical operations. Using the method of Sparse Identification of Nonlinear Dynamics (SINDy), the parameters of our model can be reconstructed online within milliseconds from a short time series of the hemodynamic variables. The identified parameter values enable automated classification of the blood-flow pathologies by means of logistic regression, achieving an accuracy of 73 %. Our results demonstrate the potential of this model for both diagnostic and prognostic applications, providing a robust and interpretable framework for assessing cerebral blood vessel conditions.
On the phase diagram of extensive-rank symmetric matrix denoising beyond rotational invariance
Nov 04, 2024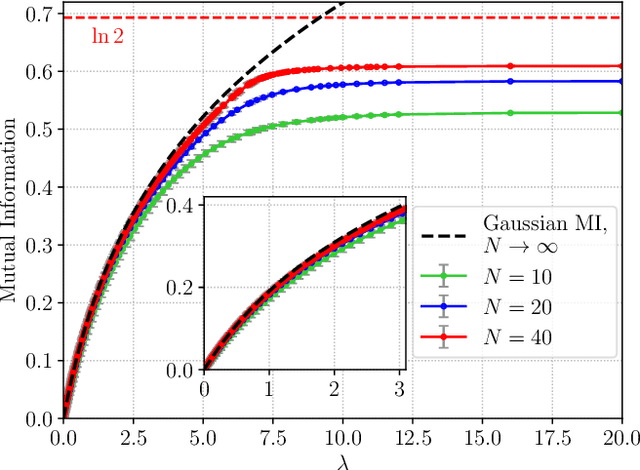
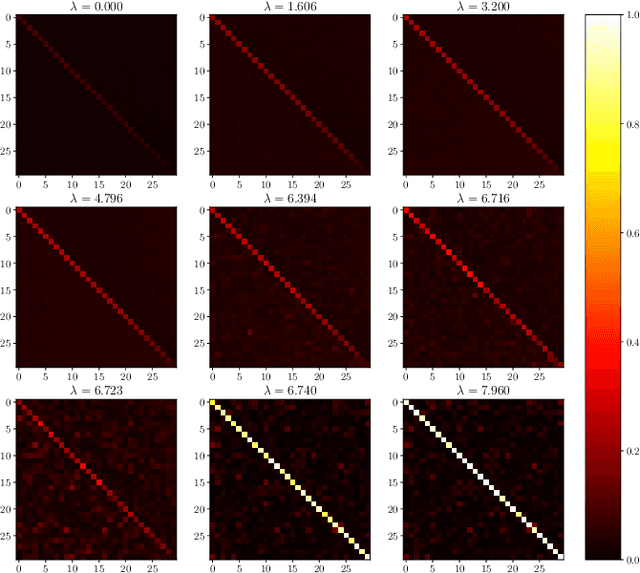
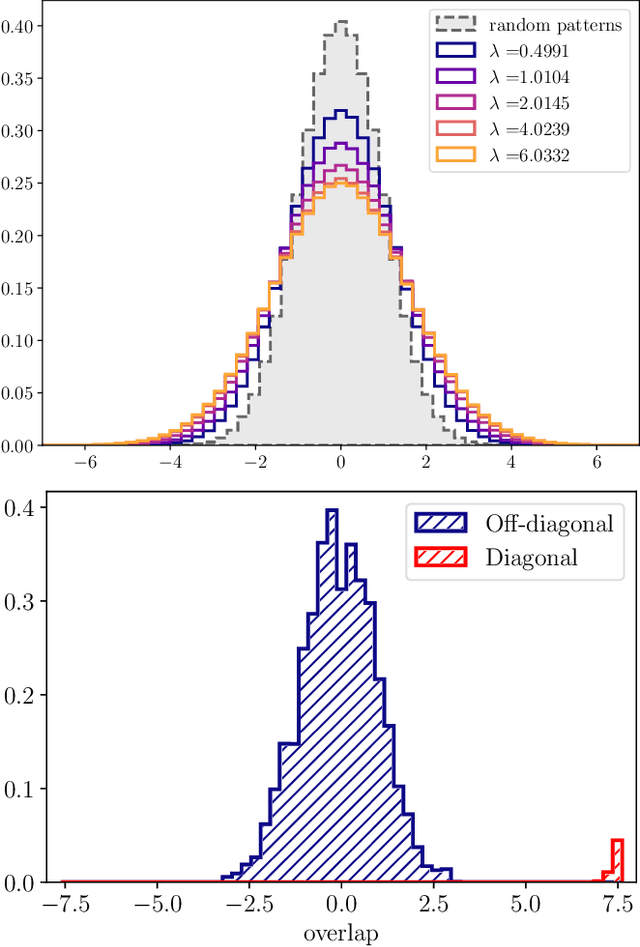
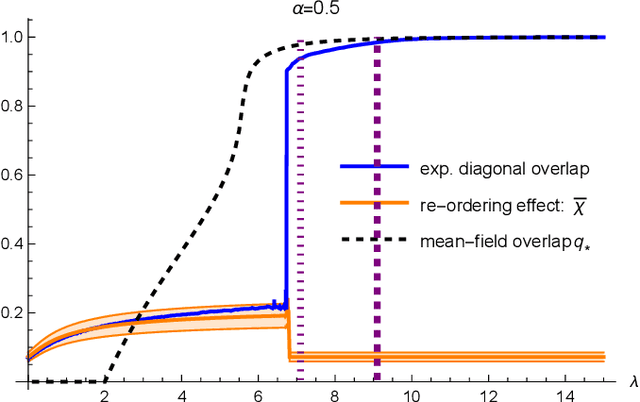
Matrix denoising is central to signal processing and machine learning. Its analysis when the matrix to infer has a factorised structure with a rank growing proportionally to its dimension remains a challenge, except when it is rotationally invariant. In this case the information theoretic limits and a Bayes-optimal denoising algorithm, called rotational invariant estimator [1,2], are known. Beyond this setting few results can be found. The reason is that the model is not a usual spin system because of the growing rank dimension, nor a matrix model due to the lack of rotation symmetry, but rather a hybrid between the two. In this paper we make progress towards the understanding of Bayesian matrix denoising when the hidden signal is a factored matrix $XX^\intercal$ that is not rotationally invariant. Monte Carlo simulations suggest the existence of a denoising-factorisation transition separating a phase where denoising using the rotational invariant estimator remains Bayes-optimal due to universality properties of the same nature as in random matrix theory, from one where universality breaks down and better denoising is possible by exploiting the signal's prior and factorised structure, though algorithmically hard. We also argue that it is only beyond the transition that factorisation, i.e., estimating $X$ itself, becomes possible up to sign and permutation ambiguities. On the theoretical side, we combine mean-field techniques in an interpretable multiscale fashion in order to access the minimum mean-square error and mutual information. Interestingly, our alternative method yields equations which can be reproduced using the replica approach of [3]. Using numerical insights, we then delimit the portion of the phase diagram where this mean-field theory is reliable, and correct it using universality when it is not. Our ansatz matches well the numerics when accounting for finite size effects.
Information limits and Thouless-Anderson-Palmer equations for spiked matrix models with structured noise
May 31, 2024

We consider a prototypical problem of Bayesian inference for a structured spiked model: a low-rank signal is corrupted by additive noise. While both information-theoretic and algorithmic limits are well understood when the noise is i.i.d. Gaussian, the more realistic case of structured noise still proves to be challenging. To capture the structure while maintaining mathematical tractability, a line of work has focused on rotationally invariant noise. However, existing studies either provide sub-optimal algorithms or they are limited to a special class of noise ensembles. In this paper, we establish the first characterization of the information-theoretic limits for a noise matrix drawn from a general trace ensemble. These limits are then achieved by an efficient algorithm inspired by the theory of adaptive Thouless-Anderson-Palmer (TAP) equations. Our approach leverages tools from statistical physics (replica method) and random matrix theory (generalized spherical integrals), and it unveils the equivalence between the rotationally invariant model and a surrogate Gaussian model.
Fundamental limits of overparametrized shallow neural networks for supervised learning
Jul 11, 2023
We carry out an information-theoretical analysis of a two-layer neural network trained from input-output pairs generated by a teacher network with matching architecture, in overparametrized regimes. Our results come in the form of bounds relating i) the mutual information between training data and network weights, or ii) the Bayes-optimal generalization error, to the same quantities but for a simpler (generalized) linear model for which explicit expressions are rigorously known. Our bounds, which are expressed in terms of the number of training samples, input dimension and number of hidden units, thus yield fundamental performance limits for any neural network (and actually any learning procedure) trained from limited data generated according to our two-layer teacher neural network model. The proof relies on rigorous tools from spin glasses and is guided by ``Gaussian equivalence principles'' lying at the core of numerous recent analyses of neural networks. With respect to the existing literature, which is either non-rigorous or restricted to the case of the learning of the readout weights only, our results are information-theoretic (i.e. are not specific to any learning algorithm) and, importantly, cover a setting where all the network parameters are trained.
Mismatched estimation of non-symmetric rank-one matrices corrupted by structured noise
Feb 08, 2023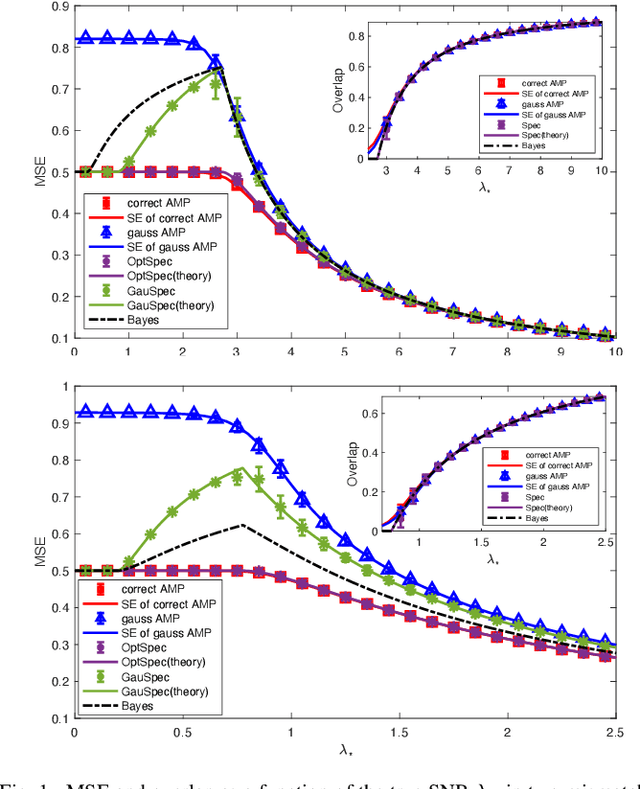
We study the performance of a Bayesian statistician who estimates a rank-one signal corrupted by non-symmetric rotationally invariant noise with a generic distribution of singular values. As the signal-to-noise ratio and the noise structure are unknown, a Gaussian setup is incorrectly assumed. We derive the exact analytic expression for the error of the mismatched Bayes estimator and also provide the analysis of an approximate message passing (AMP) algorithm. The first result exploits the asymptotic behavior of spherical integrals for rectangular matrices and of low-rank matrix perturbations; the second one relies on the design and analysis of an auxiliary AMP. The numerical experiments show that there is a performance gap between the AMP and Bayes estimators, which is due to the incorrect estimation of the signal norm.