 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMismatched estimation of non-symmetric rank-one matrices corrupted by structured noise
Feb 08, 2023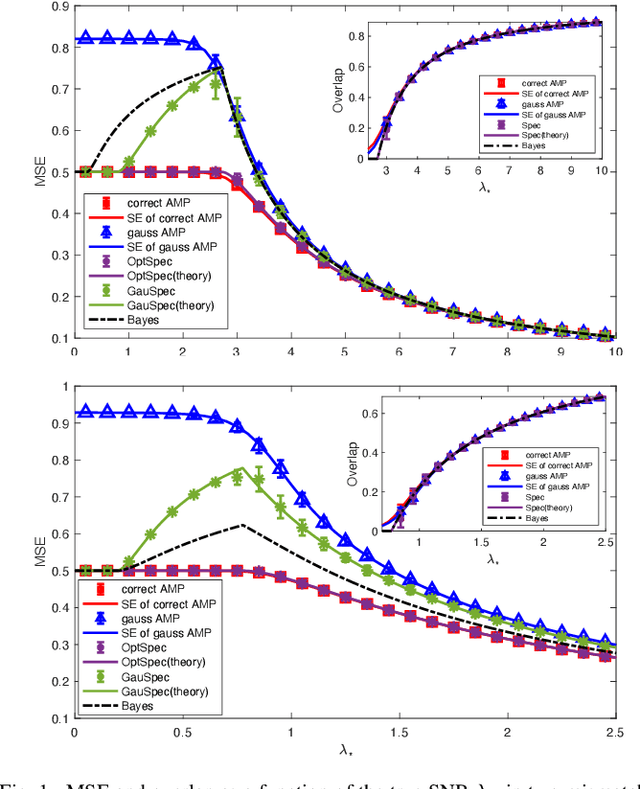
We study the performance of a Bayesian statistician who estimates a rank-one signal corrupted by non-symmetric rotationally invariant noise with a generic distribution of singular values. As the signal-to-noise ratio and the noise structure are unknown, a Gaussian setup is incorrectly assumed. We derive the exact analytic expression for the error of the mismatched Bayes estimator and also provide the analysis of an approximate message passing (AMP) algorithm. The first result exploits the asymptotic behavior of spherical integrals for rectangular matrices and of low-rank matrix perturbations; the second one relies on the design and analysis of an auxiliary AMP. The numerical experiments show that there is a performance gap between the AMP and Bayes estimators, which is due to the incorrect estimation of the signal norm.
Approximate Message Passing for Multi-Layer Estimation in Rotationally Invariant Models
Dec 03, 2022We consider the problem of reconstructing the signal and the hidden variables from observations coming from a multi-layer network with rotationally invariant weight matrices. The multi-layer structure models inference from deep generative priors, and the rotational invariance imposed on the weights generalizes the i.i.d.\ Gaussian assumption by allowing for a complex correlation structure, which is typical in applications. In this work, we present a new class of approximate message passing (AMP) algorithms and give a state evolution recursion which precisely characterizes their performance in the large system limit. In contrast with the existing multi-layer VAMP (ML-VAMP) approach, our proposed AMP -- dubbed multi-layer rotationally invariant generalized AMP (ML-RI-GAMP) -- provides a natural generalization beyond Gaussian designs, in the sense that it recovers the existing Gaussian AMP as a special case. Furthermore, ML-RI-GAMP exhibits a significantly lower complexity than ML-VAMP, as the computationally intensive singular value decomposition is replaced by an estimation of the moments of the design matrices. Finally, our numerical results show that this complexity gain comes at little to no cost in the performance of the algorithm.