 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes SGD Seek Flatness or Sharpness? An Exactly Solvable Model
Feb 04, 2026A large body of theory and empirical work hypothesizes a connection between the flatness of a neural network's loss landscape during training and its performance. However, there have been conceptually opposite pieces of evidence regarding when SGD prefers flatter or sharper solutions during training. In this work, we partially but causally clarify the flatness-seeking behavior of SGD by identifying and exactly solving an analytically solvable model that exhibits both flattening and sharpening behavior during training. In this model, the SGD training has no \textit{a priori} preference for flatness, but only a preference for minimal gradient fluctuations. This leads to the insight that, at least within this model, it is data distribution that uniquely determines the sharpness at convergence, and that a flat minimum is preferred if and only if the noise in the labels is isotropic across all output dimensions. When the noise in the labels is anisotropic, the model instead prefers sharpness and can converge to an arbitrarily sharp solution, depending on the imbalance in the noise in the labels spectrum. We reproduce this key insight in controlled settings with different model architectures such as MLP, RNN, and transformers.
Learning with Restricted Boltzmann Machines: Asymptotics of AMP and GD in High Dimensions
May 23, 2025



The Restricted Boltzmann Machine (RBM) is one of the simplest generative neural networks capable of learning input distributions. Despite its simplicity, the analysis of its performance in learning from the training data is only well understood in cases that essentially reduce to singular value decomposition of the data. Here, we consider the limit of a large dimension of the input space and a constant number of hidden units. In this limit, we simplify the standard RBM training objective into a form that is equivalent to the multi-index model with non-separable regularization. This opens a path to analyze training of the RBM using methods that are established for multi-index models, such as Approximate Message Passing (AMP) and its state evolution, and the analysis of Gradient Descent (GD) via the dynamical mean-field theory. We then give rigorous asymptotics of the training dynamics of RBM on data generated by the spiked covariance model as a prototype of a structure suitable for unsupervised learning. We show in particular that RBM reaches the optimal computational weak recovery threshold, aligning with the BBP transition, in the spiked covariance model.
Neural Thermodynamics I: Entropic Forces in Deep and Universal Representation Learning
May 18, 2025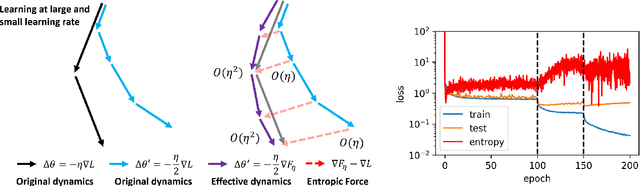



With the rapid discovery of emergent phenomena in deep learning and large language models, explaining and understanding their cause has become an urgent need. Here, we propose a rigorous entropic-force theory for understanding the learning dynamics of neural networks trained with stochastic gradient descent (SGD) and its variants. Building on the theory of parameter symmetries and an entropic loss landscape, we show that representation learning is crucially governed by emergent entropic forces arising from stochasticity and discrete-time updates. These forces systematically break continuous parameter symmetries and preserve discrete ones, leading to a series of gradient balance phenomena that resemble the equipartition property of thermal systems. These phenomena, in turn, (a) explain the universal alignment of neural representations between AI models and lead to a proof of the Platonic Representation Hypothesis, and (b) reconcile the seemingly contradictory observations of sharpness- and flatness-seeking behavior of deep learning optimization. Our theory and experiments demonstrate that a combination of entropic forces and symmetry breaking is key to understanding emergent phenomena in deep learning.
Fundamental Limits of Matrix Sensing: Exact Asymptotics, Universality, and Applications
Mar 18, 2025In the matrix sensing problem, one wishes to reconstruct a matrix from (possibly noisy) observations of its linear projections along given directions. We consider this model in the high-dimensional limit: while previous works on this model primarily focused on the recovery of low-rank matrices, we consider in this work more general classes of structured signal matrices with potentially large rank, e.g. a product of two matrices of sizes proportional to the dimension. We provide rigorous asymptotic equations characterizing the Bayes-optimal learning performance from a number of samples which is proportional to the number of entries in the matrix. Our proof is composed of three key ingredients: $(i)$ we prove universality properties to handle structured sensing matrices, related to the ''Gaussian equivalence'' phenomenon in statistical learning, $(ii)$ we provide a sharp characterization of Bayes-optimal learning in generalized linear models with Gaussian data and structured matrix priors, generalizing previously studied settings, and $(iii)$ we leverage previous works on the problem of matrix denoising. The generality of our results allow for a variety of applications: notably, we mathematically establish predictions obtained via non-rigorous methods from statistical physics in [ETB+24] regarding Bilinear Sequence Regression, a benchmark model for learning from sequences of tokens, and in [MTM+24] on Bayes-optimal learning in neural networks with quadratic activation function, and width proportional to the dimension.
Parameter Symmetry Breaking and Restoration Determines the Hierarchical Learning in AI Systems
Feb 07, 2025



The dynamics of learning in modern large AI systems is hierarchical, often characterized by abrupt, qualitative shifts akin to phase transitions observed in physical systems. While these phenomena hold promise for uncovering the mechanisms behind neural networks and language models, existing theories remain fragmented, addressing specific cases. In this paper, we posit that parameter symmetry breaking and restoration serve as a unifying mechanism underlying these behaviors. We synthesize prior observations and show how this mechanism explains three distinct hierarchies in neural networks: learning dynamics, model complexity, and representation formation. By connecting these hierarchies, we highlight symmetry -- a cornerstone of theoretical physics -- as a potential fundamental principle in modern AI.
Remove Symmetries to Control Model Expressivity
Aug 28, 2024When symmetry is present in the loss function, the model is likely to be trapped in a low-capacity state that is sometimes known as a "collapse." Being trapped in these low-capacity states can be a major obstacle to training across many scenarios where deep learning technology is applied. We first prove two concrete mechanisms through which symmetries lead to reduced capacities and ignored features during training. We then propose a simple and theoretically justified algorithm, syre, to remove almost all symmetry-induced low-capacity states in neural networks. The proposed method is shown to improve the training of neural networks in scenarios when this type of entrapment is especially a concern. A remarkable merit of the proposed method is that it is model-agnostic and does not require any knowledge of the symmetry.
Information limits and Thouless-Anderson-Palmer equations for spiked matrix models with structured noise
May 31, 2024

We consider a prototypical problem of Bayesian inference for a structured spiked model: a low-rank signal is corrupted by additive noise. While both information-theoretic and algorithmic limits are well understood when the noise is i.i.d. Gaussian, the more realistic case of structured noise still proves to be challenging. To capture the structure while maintaining mathematical tractability, a line of work has focused on rotationally invariant noise. However, existing studies either provide sub-optimal algorithms or they are limited to a special class of noise ensembles. In this paper, we establish the first characterization of the information-theoretic limits for a noise matrix drawn from a general trace ensemble. These limits are then achieved by an efficient algorithm inspired by the theory of adaptive Thouless-Anderson-Palmer (TAP) equations. Our approach leverages tools from statistical physics (replica method) and random matrix theory (generalized spherical integrals), and it unveils the equivalence between the rotationally invariant model and a surrogate Gaussian model.
Decentralizing Coherent Joint Transmission Precoding via Fast ADMM with Deterministic Equivalents
Mar 28, 2024



Inter-cell interference (ICI) suppression is critical for multi-cell multi-user networks. In this paper, we investigate advanced precoding techniques for coordinated multi-point (CoMP) with downlink coherent joint transmission, an effective approach for ICI suppression. Different from the centralized precoding schemes that require frequent information exchange among the cooperating base stations, we propose a decentralized scheme to minimize the total power consumption. In particular, based on the covariance matrices of global channel state information, we estimate the ICI bounds via the deterministic equivalents and decouple the original design problem into sub-problems, each of which can be solved in a decentralized manner. To solve the sub-problems at each base station, we develop a low-complexity solver based on the alternating direction method of multipliers (ADMM) in conjunction with the convex-concave procedure (CCCP). Simulation results demonstrate the effectiveness of our proposed decentralized precoding scheme, which achieves performance similar to the optimal centralized precoding scheme. Besides, our proposed ADMM solver can substantially reduce the computational complexity, while maintaining outstanding performance.
Decentralizing Coherent Joint Transmission Precoding via Deterministic Equivalents
Mar 15, 2024
In order to control the inter-cell interference for a multi-cell multi-user multiple-input multiple-output network, we consider the precoder design for coordinated multi-point with downlink coherent joint transmission. To avoid costly information exchange among the cooperating base stations in a centralized precoding scheme, we propose a decentralized one by considering the power minimization problem. By approximating the inter-cell interference using the deterministic equivalents, this problem is decoupled to sub-problems which are solved in a decentralized manner at different base stations. Simulation results demonstrate the effectiveness of our proposed decentralized precoding scheme, where only 2 ~ 7% more transmit power is needed compared with the optimal centralized precoder.
When Does Feature Learning Happen? Perspective from an Analytically Solvable Model
Jan 13, 2024



We identify and solve a hidden-layer model that is analytically tractable at any finite width and whose limits exhibit both the kernel phase and the feature learning phase. We analyze the phase diagram of this model in all possible limits of common hyperparameters including width, layer-wise learning rates, scale of output, and scale of initialization. We apply our result to analyze how and when feature learning happens in both infinite and finite-width models. Three prototype mechanisms of feature learning are identified: (1) learning by alignment, (2) learning by disalignment, and (3) learning by rescaling. In sharp contrast, neither of these mechanisms is present when the model is in the kernel regime. This discovery explains why large initialization often leads to worse performance. Lastly, we empirically demonstrate that discoveries we made for this analytical model also appear in nonlinear networks in real tasks.