 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Efficient Velocity Profile Optimization for Movable Antenna-Enabled Sensing Systems
Mar 29, 2026Movable antennas (MAs) enable the reconfiguration of array geometry within a bounded region to exploit sub-wavelength spatial degrees of freedom in wireless communication and sensing systems. However, most prior research has predominantly focused on the communication and sensing performance, overlooking the mechanical power consumption inherent in antenna movement. To bridge this gap, this paper investigates a velocity profile optimization framework for MA-assisted direction-of-arrival (DoA) estimation, explicitly balancing sensing accuracy with mechanical energy consumption of MAs. We first establish a Newtonian-based mechanical energy model, and formulate a functional optimization problem for sensing energy efficiency (EE) maximization. By applying the calculus of variations, this formulation is transformed into an infinite-dimensional problem defined by the Euler-Lagrange equation. To solve it, we propose a spectral discretization framework based on the Galerkin method, which expands the velocity profile over a sinusoidal basis. In the regime where energy consumption is dominated by linear damping, we prove that the optimal velocity profile follows a closed-form sinusoidal shape. For more general scenarios involving strong nonlinear aerodynamic drag, we leverage the Markov-Lukács theorem to transform the kinematic constraints into strictly convex sum-of-squares (SOS) conditions. Consequently, the infinite-dimensional problem is reformulated as a tractable finite-dimensional nonlinear algebraic system, which is solved by a two-layer algorithm combining Dinkelbach's method with successive convex approximation (SCA). Numerical results demonstrate that our optimized velocity profile significantly outperforms baselines in terms of EE across various system configurations. Insights into the optimized velocity profiles and practical design guidelines are also provided.
Orchestrating Joint Offloading and Scheduling for Low-Latency Edge SLAM
Feb 23, 2025Visual Simultaneous Localization and Mapping (vSLAM) is a prevailing technology for many emerging robotic applications. Achieving real-time SLAM on mobile robotic systems with limited computational resources is challenging because the complexity of SLAM algorithms increases over time. This restriction can be lifted by offloading computations to edge servers, forming the emerging paradigm of edge-assisted SLAM. Nevertheless, the exogenous and stochastic input processes affect the dynamics of the edge-assisted SLAM system. Moreover, the requirements of clients on SLAM metrics change over time, exerting implicit and time-varying effects on the system. In this paper, we aim to push the limit beyond existing edge-assist SLAM by proposing a new architecture that can handle the input-driven processes and also satisfy clients' implicit and time-varying requirements. The key innovations of our work involve a regional feature prediction method for importance-aware local data processing, a configuration adaptation policy that integrates data compression/decompression and task offloading, and an input-dependent learning framework for task scheduling with constraint satisfaction. Extensive experiments prove that our architecture improves pose estimation accuracy and saves up to 47% of communication costs compared with a popular edge-assisted SLAM system, as well as effectively satisfies the clients' requirements.
Privacy-Aware Multi-Device Cooperative Edge Inference with Distributed Resource Bidding
Dec 30, 2024



Mobile edge computing (MEC) has empowered mobile devices (MDs) in supporting artificial intelligence (AI) applications through collaborative efforts with proximal MEC servers. Unfortunately, despite the great promise of device-edge cooperative AI inference, data privacy becomes an increasing concern. In this paper, we develop a privacy-aware multi-device cooperative edge inference system for classification tasks, which integrates a distributed bidding mechanism for the MEC server's computational resources. Intermediate feature compression is adopted as a principled approach to minimize data privacy leakage. To determine the bidding values and feature compression ratios in a distributed fashion, we formulate a decentralized partially observable Markov decision process (DEC-POMDP) model, for which, a multi-agent deep deterministic policy gradient (MADDPG)-based algorithm is developed. Simulation results demonstrate the effectiveness of the proposed algorithm in privacy-preserving cooperative edge inference. Specifically, given a sufficient level of data privacy protection, the proposed algorithm achieves 0.31-0.95% improvements in classification accuracy compared to the approach being agnostic to the wireless channel conditions. The performance is further enhanced by 1.54-1.67% by considering the difficulties of inference data.
Integrated Sensing and Communications for Low-Altitude Economy: A Deep Reinforcement Learning Approach
Dec 05, 2024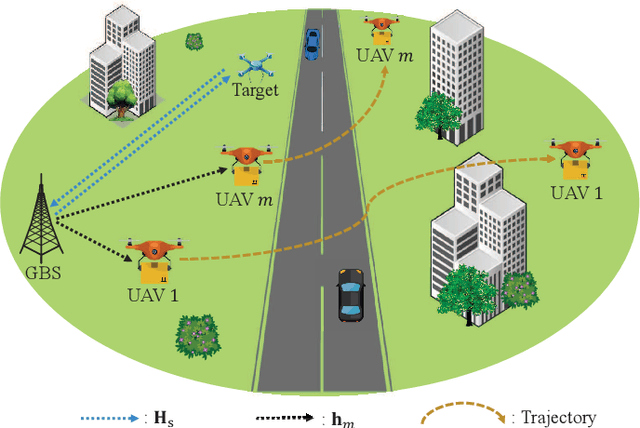
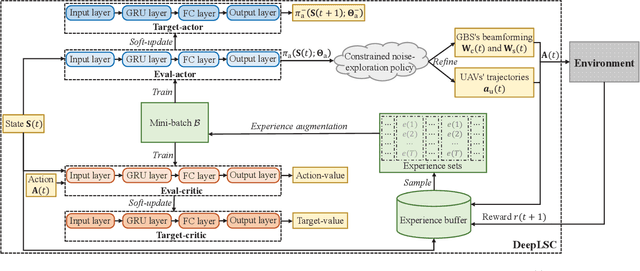
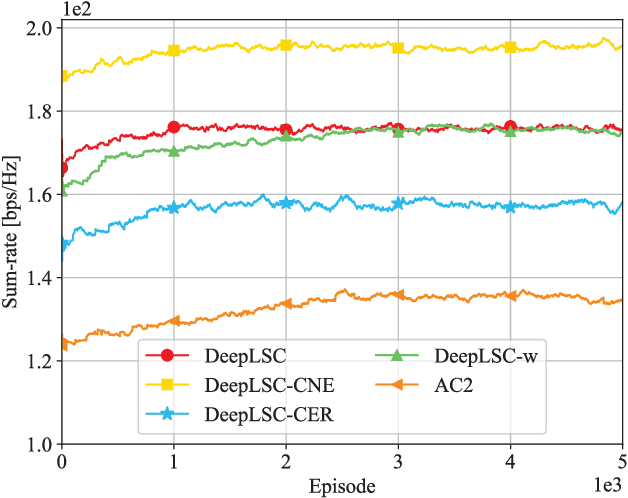
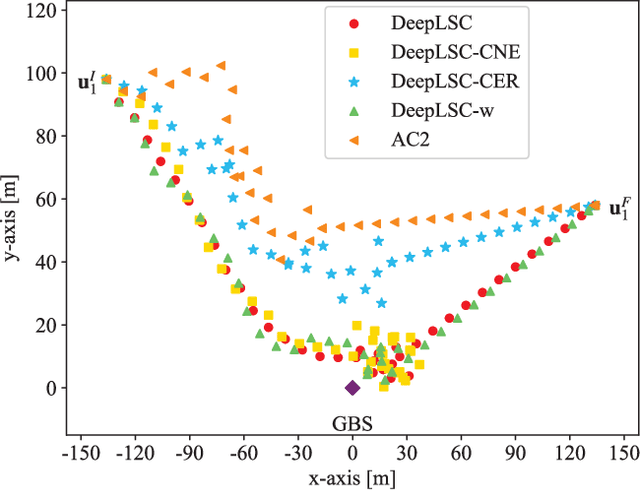
This paper studies an integrated sensing and communications (ISAC) system for low-altitude economy (LAE), where a ground base station (GBS) provides communication and navigation services for authorized unmanned aerial vehicles (UAVs), while sensing the low-altitude airspace to monitor the unauthorized mobile target. The expected communication sum-rate over a given flight period is maximized by jointly optimizing the beamforming at the GBS and UAVs' trajectories, subject to the constraints on the average signal-to-noise ratio requirement for sensing, the flight mission and collision avoidance of UAVs, as well as the maximum transmit power at the GBS. Typically, this is a sequential decision-making problem with the given flight mission. Thus, we transform it to a specific Markov decision process (MDP) model called episode task. Based on this modeling, we propose a novel LAE-oriented ISAC scheme, referred to as Deep LAE-ISAC (DeepLSC), by leveraging the deep reinforcement learning (DRL) technique. In DeepLSC, a reward function and a new action selection policy termed constrained noise-exploration policy are judiciously designed to fulfill various constraints. To enable efficient learning in episode tasks, we develop a hierarchical experience replay mechanism, where the gist is to employ all experiences generated within each episode to jointly train the neural network. Besides, to enhance the convergence speed of DeepLSC, a symmetric experience augmentation mechanism, which simultaneously permutes the indexes of all variables to enrich available experience sets, is proposed. Simulation results demonstrate that compared with benchmarks, DeepLSC yields a higher sum-rate while meeting the preset constraints, achieves faster convergence, and is more robust against different settings.
RSSI-Assisted CSI-Based Passenger Counting with Multiple Wi-Fi Receivers
Oct 15, 2024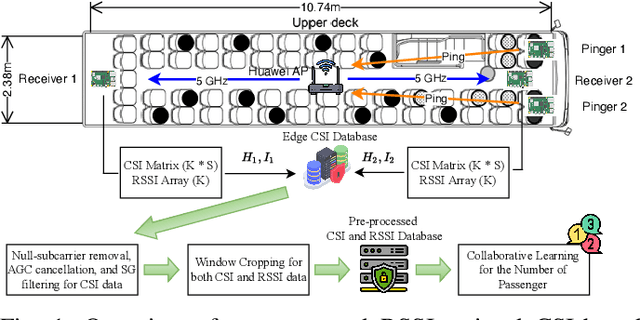
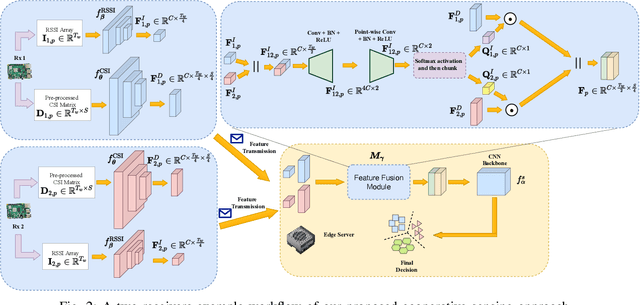
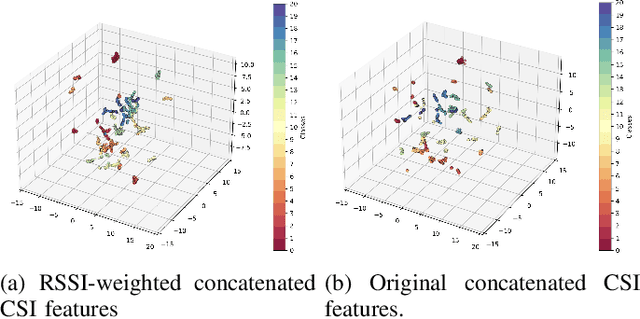
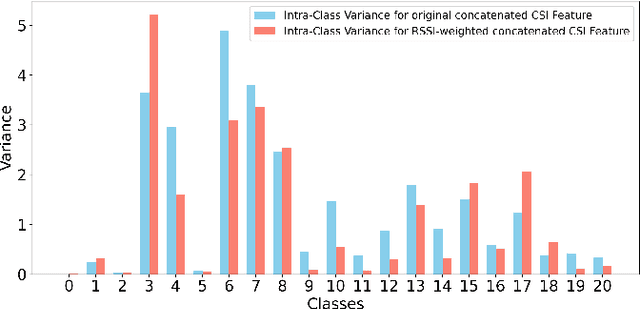
Passenger counting is crucial for public transport vehicle scheduling and traffic capacity evaluation. However, most existing methods are either costly or with low counting accuracy, leading to the recent use of Wi-Fi signals for this purpose. In this paper, we develop an efficient edge computing-based passenger counting system consists of multiple Wi-Fi receivers and an edge server. It leverages channel state information (CSI) and received signal strength indicator (RSSI) to facilitate the collaboration among multiple receivers. Specifically, we design a novel CSI feature fusion module called Adaptive RSSI-weighted CSI Feature Concatenation, which integrates locally extracted CSI and RSSI features from multiple receivers for information fusion at the edge server. Performance of our proposed system is evaluated using a real-world dataset collected from a double-decker bus in Hong Kong, with up to 20 passengers. The experimental results reveal that our system achieves an average accuracy and F1-score of over 94%, surpassing other cooperative sensing baselines by at least 2.27% in accuracy and 2.34% in F1-score.
Decentralizing Coherent Joint Transmission Precoding via Fast ADMM with Deterministic Equivalents
Mar 28, 2024



Inter-cell interference (ICI) suppression is critical for multi-cell multi-user networks. In this paper, we investigate advanced precoding techniques for coordinated multi-point (CoMP) with downlink coherent joint transmission, an effective approach for ICI suppression. Different from the centralized precoding schemes that require frequent information exchange among the cooperating base stations, we propose a decentralized scheme to minimize the total power consumption. In particular, based on the covariance matrices of global channel state information, we estimate the ICI bounds via the deterministic equivalents and decouple the original design problem into sub-problems, each of which can be solved in a decentralized manner. To solve the sub-problems at each base station, we develop a low-complexity solver based on the alternating direction method of multipliers (ADMM) in conjunction with the convex-concave procedure (CCCP). Simulation results demonstrate the effectiveness of our proposed decentralized precoding scheme, which achieves performance similar to the optimal centralized precoding scheme. Besides, our proposed ADMM solver can substantially reduce the computational complexity, while maintaining outstanding performance.
Decentralizing Coherent Joint Transmission Precoding via Deterministic Equivalents
Mar 15, 2024
In order to control the inter-cell interference for a multi-cell multi-user multiple-input multiple-output network, we consider the precoder design for coordinated multi-point with downlink coherent joint transmission. To avoid costly information exchange among the cooperating base stations in a centralized precoding scheme, we propose a decentralized one by considering the power minimization problem. By approximating the inter-cell interference using the deterministic equivalents, this problem is decoupled to sub-problems which are solved in a decentralized manner at different base stations. Simulation results demonstrate the effectiveness of our proposed decentralized precoding scheme, where only 2 ~ 7% more transmit power is needed compared with the optimal centralized precoder.
Joint Activity-Delay Detection and Channel Estimation for Asynchronous Massive Random Access: A Free Probability Theory Approach
Feb 28, 2024Grant-free random access (RA) has been recognized as a promising solution to support massive connectivity due to the removal of the uplink grant request procedures. While most endeavours assume perfect synchronization among users and the base station, this paper investigates asynchronous grant-free massive RA, and develop efficient algorithms for joint user activity detection, synchronization delay detection, and channel estimation. Considering the sparsity on user activity, we formulate a sparse signal recovery problem and propose to utilize the framework of orthogonal approximate message passing (OAMP) to deal with the non-independent and identically distributed (i.i.d.) Gaussian pilot matrices caused by the synchronization delays. In particular, an OAMP-based algorithm is developed to fully harness the common sparsity among received pilot signals from multiple base station antennas. To reduce the computational complexity, we further propose a free probability AMP (FPAMP)-based algorithm, which exploits the rectangular free cumulants to make the cost-effective AMP framework compatible to general pilot matrices. Simulation results demonstrate that the two proposed algorithms outperform various baselines, and the FPAMP-based algorithm reduces 40% of the computations while maintaining comparable detection/estimation accuracy with the OAMP-based algorithm.
Approximate Message Passing-Enhanced Graph Neural Network for OTFS Data Detection
Feb 15, 2024



Orthogonal time frequency space (OTFS) modulation has emerged as a promising solution to support high-mobility wireless communications, for which, cost-effective data detectors are critical. Although graph neural network (GNN)-based data detectors can achieve decent detection accuracy at reasonable computation cost, they fail to best harness prior information of transmitted data. To further minimize the data detection error of OTFS systems, this letter develops an AMP-GNN-based detector, leveraging the approximate message passing (AMP) algorithm to iteratively improve the symbol estimates of a GNN. Given the inter-Doppler interference (IDI) symbols incur substantial computational overhead to the constructed GNN, learning-based IDI approximation is implemented to sustain low detection complexity. Simulation results demonstrate a remarkable bit error rate (BER) performance achieved by the proposed AMP-GNN-based detector compared to existing baselines. Meanwhile, the proposed IDI approximation scheme avoids a large amount of computations with negligible BER degradation.
Green Edge AI: A Contemporary Survey
Dec 01, 2023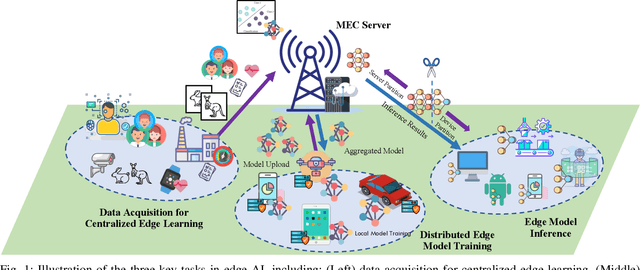
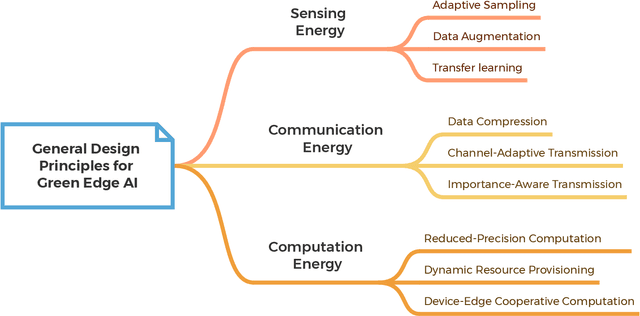
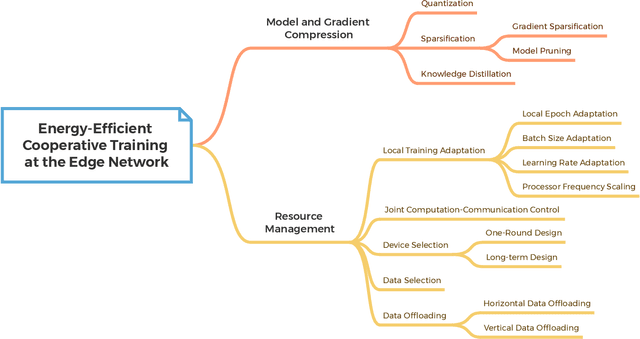
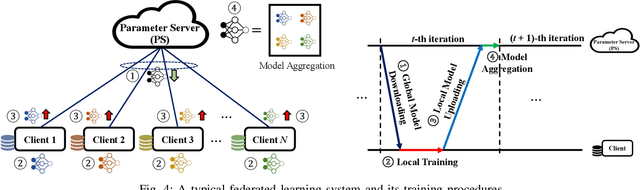
Artificial intelligence (AI) technologies have emerged as pivotal enablers across a multitude of industries, including consumer electronics, healthcare, and manufacturing, largely due to their resurgence over the past decade. The transformative power of AI is primarily derived from the utilization of deep neural networks (DNNs), which require extensive data for training and substantial computational resources for processing. Consequently, DNN models are typically trained and deployed on resource-rich cloud servers. However, due to potential latency issues associated with cloud communications, deep learning (DL) workflows are increasingly being transitioned to wireless edge networks near end-user devices (EUDs). This shift is designed to support latency-sensitive applications and has given rise to a new paradigm of edge AI, which will play a critical role in upcoming 6G networks to support ubiquitous AI applications. Despite its potential, edge AI faces substantial challenges, mostly due to the dichotomy between the resource limitations of wireless edge networks and the resource-intensive nature of DL. Specifically, the acquisition of large-scale data, as well as the training and inference processes of DNNs, can rapidly deplete the battery energy of EUDs. This necessitates an energy-conscious approach to edge AI to ensure both optimal and sustainable performance. In this paper, we present a contemporary survey on green edge AI. We commence by analyzing the principal energy consumption components of edge AI systems to identify the fundamental design principles of green edge AI. Guided by these principles, we then explore energy-efficient design methodologies for the three critical tasks in edge AI systems, including training data acquisition, edge training, and edge inference. Finally, we underscore potential future research directions to further enhance the energy efficiency of edge AI.