 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDS-CIM: Digital Stochastic Computing-In-Memory Featuring Accurate OR-Accumulation via Sample Region Remapping for Edge AI Models
Jan 10, 2026Stochastic computing (SC) offers hardware simplicity but suffers from low throughput, while high-throughput Digital Computing-in-Memory (DCIM) is bottlenecked by costly adder logic for matrix-vector multiplication (MVM). To address this trade-off, this paper introduces a digital stochastic CIM (DS-CIM) architecture that achieves both high accuracy and efficiency. We implement signed multiply-accumulation (MAC) in a compact, unsigned OR-based circuit by modifying the data representation. Throughput is enhanced by replicating this low-cost circuit 64 times with only a 1x area increase. Our core strategy, a shared Pseudo Random Number Generator (PRNG) with 2D partitioning, enables single-cycle mutually exclusive activation to eliminate OR-gate collisions. We also resolve the 1s saturation issue via stochastic process analysis and data remapping, significantly improving accuracy and resilience to input sparsity. Our high-accuracy DS-CIM1 variant achieves 94.45% accuracy for INT8 ResNet18 on CIFAR-10 with a root-mean-squared error (RMSE) of just 0.74%. Meanwhile, our high-efficiency DS-CIM2 variant attains an energy efficiency of 3566.1 TOPS/W and an area efficiency of 363.7 TOPS/mm^2, while maintaining a low RMSE of 3.81%. The DS-CIM capability with larger models is further demonstrated through experiments with INT8 ResNet50 on ImageNet and the FP8 LLaMA-7B model.
A 28nm 0.22 μJ/token memory-compute-intensity-aware CNN-Transformer accelerator with hybrid-attention-based layer-fusion and cascaded pruning for semanticsegmentation
Dec 19, 2025This work presents a 28nm 13.93mm2 CNN-Transformer accelerator for semantic segmentation, achieving 3.86-to-10.91x energy reduction over previous designs. It features a hybrid attention unit, layer-fusion scheduler, and cascaded feature-map pruner, with peak energy efficiency of 52.90TOPS/W (INT8).
* 3 pages,7 pages, 2025 IEEE International Solid-State Circuits Conference (ISSCC)
FedLAM: Low-latency Wireless Federated Learning via Layer-wise Adaptive Modulation
Oct 09, 2025In wireless federated learning (FL), the clients need to transmit the high-dimensional deep neural network (DNN) parameters through bandwidth-limited channels, which causes the communication latency issue. In this paper, we propose a layer-wise adaptive modulation scheme to save the communication latency. Unlike existing works which assign the same modulation level for all DNN layers, we consider the layers' importance which provides more freedom to save the latency. The proposed scheme can automatically decide the optimal modulation levels for different DNN layers. Experimental results show that the proposed scheme can save up to 73.9% of communication latency compared with the existing schemes.
Partial Knowledge Distillation for Alleviating the Inherent Inter-Class Discrepancy in Federated Learning
Nov 23, 2024



Substantial efforts have been devoted to alleviating the impact of the long-tailed class distribution in federated learning. In this work, we observe an interesting phenomenon that weak classes consistently exist even for class-balanced learning. These weak classes, different from the minority classes in the previous works, are inherent to data and remain fairly consistent for various network structures and learning paradigms. The inherent inter-class accuracy discrepancy can reach over 36.9% for federated learning on the FashionMNIST and CIFAR-10 datasets, even when the class distribution is balanced both globally and locally. In this study, we empirically analyze the potential reason for this phenomenon. Furthermore, a class-specific partial knowledge distillation method is proposed to improve the model's classification accuracy for weak classes. In this approach, knowledge transfer is initiated upon the occurrence of specific misclassifications within certain weak classes. Experimental results show that the accuracy of weak classes can be improved by 10.7%, reducing the inherent interclass discrepancy effectively.
FedAQ: Communication-Efficient Federated Edge Learning via Joint Uplink and Downlink Adaptive Quantization
Jun 26, 2024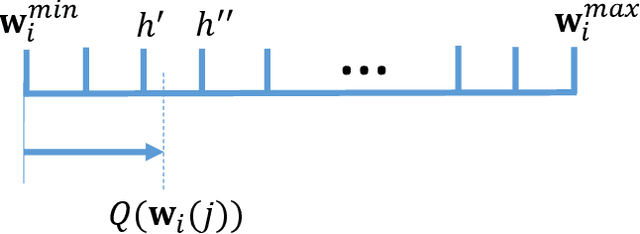

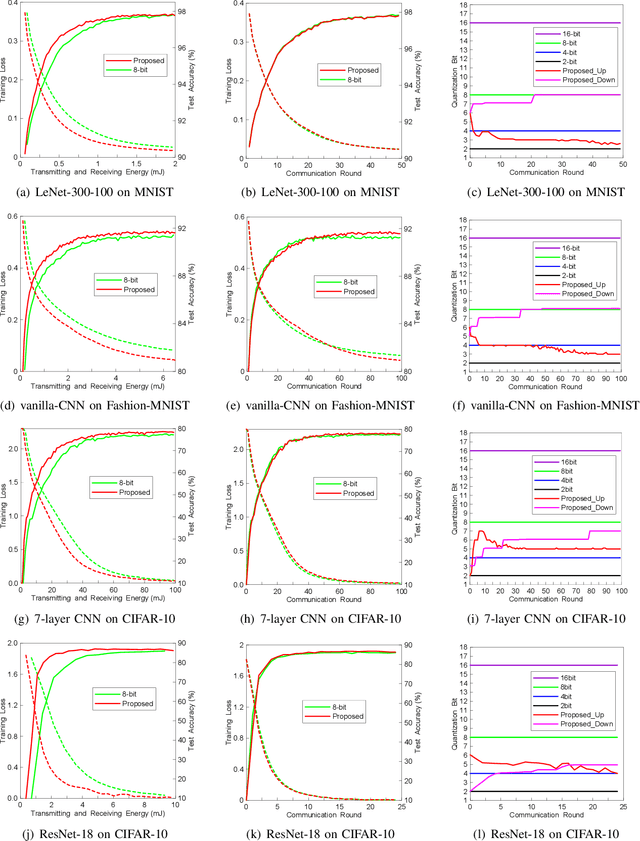

Federated learning (FL) is a powerful machine learning paradigm which leverages the data as well as the computational resources of clients, while protecting clients' data privacy. However, the substantial model size and frequent aggregation between the server and clients result in significant communication overhead, making it challenging to deploy FL in resource-limited wireless networks. In this work, we aim to mitigate the communication overhead by using quantization. Previous research on quantization has primarily focused on the uplink communication, employing either fixed-bit quantization or adaptive quantization methods. In this work, we introduce a holistic approach by joint uplink and downlink adaptive quantization to reduce the communication overhead. In particular, we optimize the learning convergence by determining the optimal uplink and downlink quantization bit-length, with a communication energy constraint. Theoretical analysis shows that the optimal quantization levels depend on the range of model gradients or weights. Based on this insight, we propose a decreasing-trend quantization for the uplink and an increasing-trend quantization for the downlink, which aligns with the change of the model parameters during the training process. Experimental results show that, the proposed joint uplink and downlink adaptive quantization strategy can save up to 66.7% energy compared with the existing schemes.
How Robust is Federated Learning to Communication Error? A Comparison Study Between Uplink and Downlink Channels
Oct 25, 2023
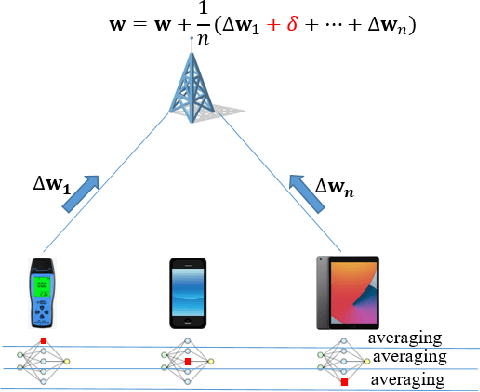
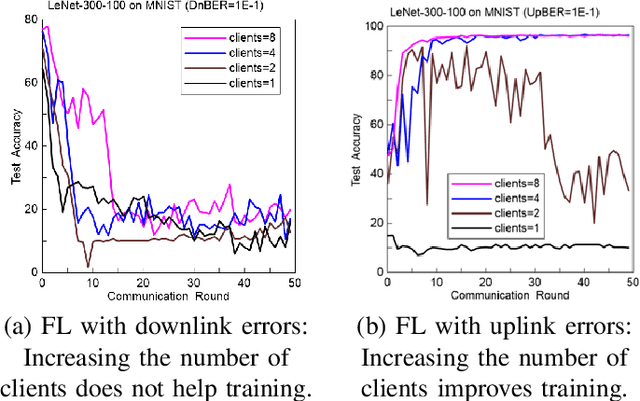
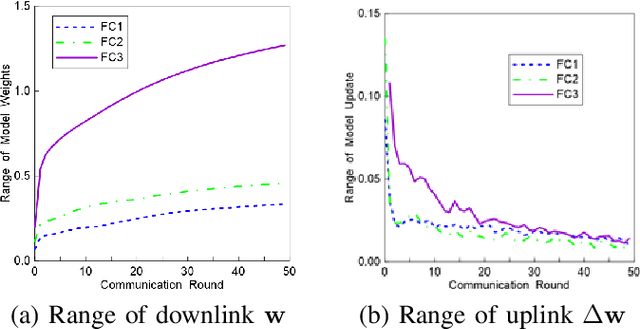
Because of its privacy-preserving capability, federated learning (FL) has attracted significant attention from both academia and industry. However, when being implemented over wireless networks, it is not clear how much communication error can be tolerated by FL. This paper investigates the robustness of FL to the uplink and downlink communication error. Our theoretical analysis reveals that the robustness depends on two critical parameters, namely the number of clients and the numerical range of model parameters. It is also shown that the uplink communication in FL can tolerate a higher bit error rate (BER) than downlink communication, and this difference is quantified by a proposed formula. The findings and theoretical analyses are further validated by extensive experiments.
Step-GRAND: A Low Latency Universal Soft-input Decoder
Jul 27, 2023



GRAND features both soft-input and hard-input variants that are well suited to efficient hardware implementations that can be characterized with achievable average and worst-case decoding latency. This paper introduces step-GRAND, a soft-input variant of GRAND that, in addition to achieving appealing average decoding latency, also reduces the worst-case decoding latency of the corresponding hardware implementation. The hardware implementation results demonstrate that the proposed step-GRAND can decode CA-polar code $(128,105+11)$ with an average information throughput of $47.7$ Gbps at the target FER of $\leq10^{-7}$. Furthermore, the proposed step-GRAND hardware is $10\times$ more area efficient than the previous soft-input ORBGRAND hardware implementation, and its worst-case latency is $\frac{1}{6.8}\times$ that of the previous ORBGRAND hardware.
A 137.5 TOPS/W SRAM Compute-in-Memory Macro with 9-b Memory Cell-Embedded ADCs and Signal Margin Enhancement Techniques for AI Edge Applications
Jul 19, 2023In this paper, we propose a high-precision SRAM-based CIM macro that can perform 4x4-bit MAC operations and yield 9-bit signed output. The inherent discharge branches of SRAM cells are utilized to apply time-modulated MAC and 9-bit ADC readout operations on two bit-line capacitors. The same principle is used for both MAC and A-to-D conversion ensuring high linearity and thus supporting large number of analog MAC accumulations. The memory cell-embedded ADC eliminates the use of separate ADCs and enhances energy and area efficiency. Additionally, two signal margin enhancement techniques, namely the MAC-folding and boosted-clipping schemes, are proposed to further improve the CIM computation accuracy.
FedDQ: Communication-Efficient Federated Learning with Descending Quantization
Oct 13, 2021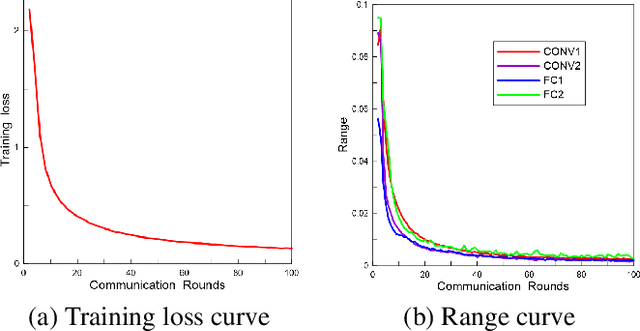

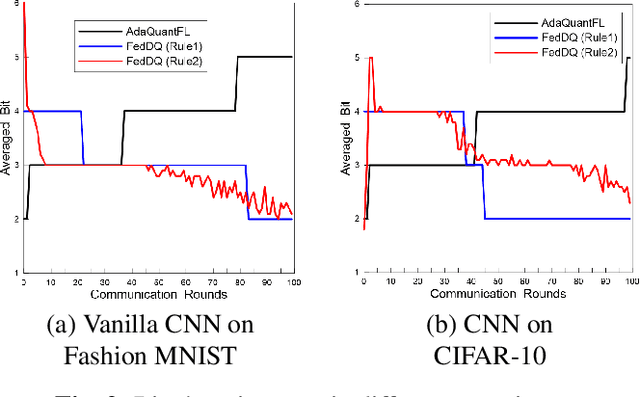
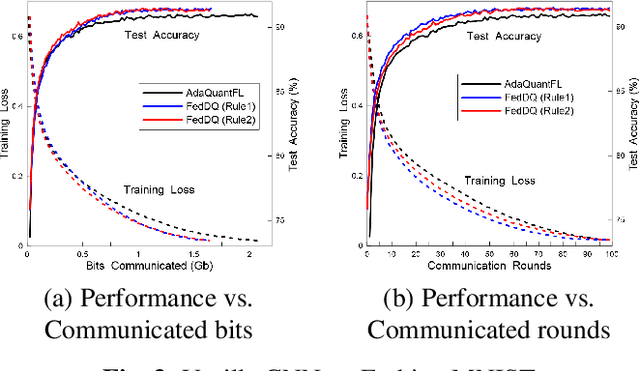
Federated learning (FL) is an emerging privacy-preserving distributed learning scheme. Due to the large model size and frequent model aggregation, FL suffers from critical communication bottleneck. Many techniques have been proposed to reduce the communication volume, including model compression and quantization. Existing adaptive quantization schemes use ascending-trend quantization where the quantizaion level increases with the training stages. In this paper, we formulate the problem as optimizing the training convergence rate for a given communication volume. The result shows that the optimal quantizaiton level can be represented by two factors, i.e., the training loss and the range of model updates, and it is preferable to decrease the quantization level rather than increase. Then, we propose two descending quantization schemes based on the training loss and model range. Experimental results show that proposed schemes not only reduce the communication volume but also help FL converge faster, when compared with current ascending quantization.
Microshift: An Efficient Image Compression Algorithm for Hardware
Apr 20, 2021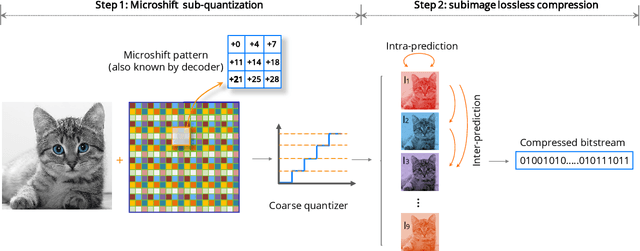
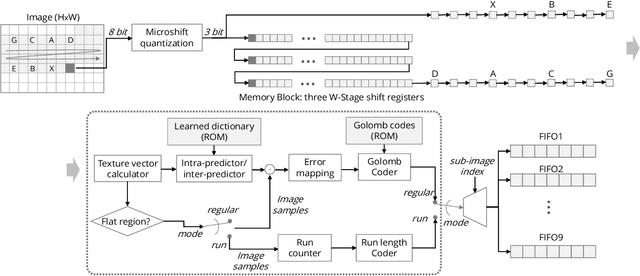


In this paper, we propose an image compression algorithm called Microshift. We employ an algorithm hardware co-design methodology, yielding a hardware-friendly compression approach with low power consumption. In our method, the image is first micro-shifted, then the sub-quantized values are further compressed. Two methods, the FAST and MRF model, are proposed to recover the bit-depth by exploiting the spatial correlation of natural images. Both methods can decompress images progressively. Our compression algorithm compresses images to 1.25 bits per pixel on average with PSNR of 33.16 dB, outperforming other on-chip compression algorithms. Then, we propose a hardware architecture and implement the algorithm on an FPGA and ASIC. The results on the VLSI design further validate the low hardware complexity and high power efficiency, showing our method is promising, particularly for low-power wireless vision sensor networks.