 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedDQ: Communication-Efficient Federated Learning with Descending Quantization
Paper and Code
Oct 13, 2021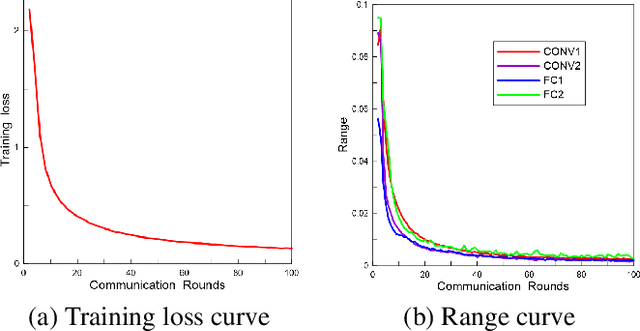

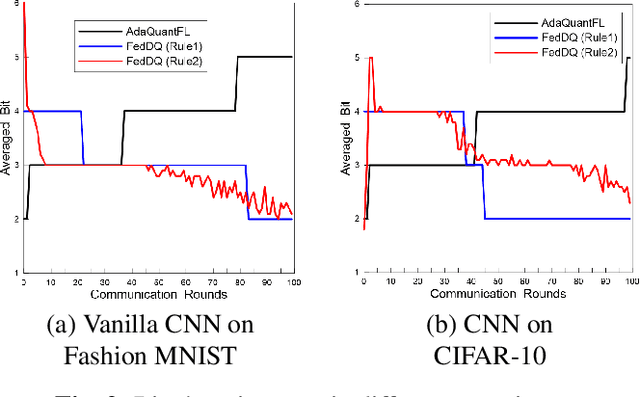
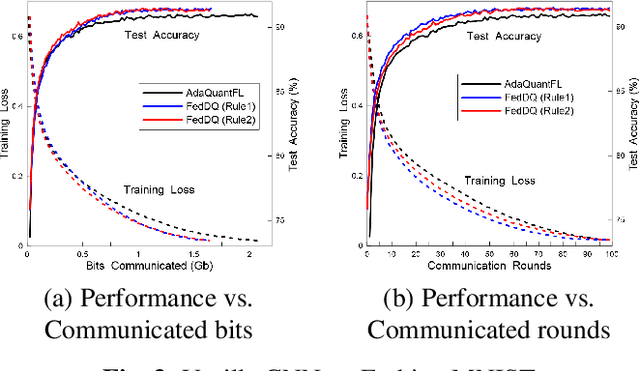
Federated learning (FL) is an emerging privacy-preserving distributed learning scheme. Due to the large model size and frequent model aggregation, FL suffers from critical communication bottleneck. Many techniques have been proposed to reduce the communication volume, including model compression and quantization. Existing adaptive quantization schemes use ascending-trend quantization where the quantizaion level increases with the training stages. In this paper, we formulate the problem as optimizing the training convergence rate for a given communication volume. The result shows that the optimal quantizaiton level can be represented by two factors, i.e., the training loss and the range of model updates, and it is preferable to decrease the quantization level rather than increase. Then, we propose two descending quantization schemes based on the training loss and model range. Experimental results show that proposed schemes not only reduce the communication volume but also help FL converge faster, when compared with current ascending quantization.