 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedLAM: Low-latency Wireless Federated Learning via Layer-wise Adaptive Modulation
Oct 09, 2025In wireless federated learning (FL), the clients need to transmit the high-dimensional deep neural network (DNN) parameters through bandwidth-limited channels, which causes the communication latency issue. In this paper, we propose a layer-wise adaptive modulation scheme to save the communication latency. Unlike existing works which assign the same modulation level for all DNN layers, we consider the layers' importance which provides more freedom to save the latency. The proposed scheme can automatically decide the optimal modulation levels for different DNN layers. Experimental results show that the proposed scheme can save up to 73.9% of communication latency compared with the existing schemes.
KVTuner: Sensitivity-Aware Layer-wise Mixed Precision KV Cache Quantization for Efficient and Nearly Lossless LLM Inference
Feb 06, 2025



KV cache quantization can improve Large Language Models (LLMs) inference throughput and latency in long contexts and large batch-size scenarios while preserving LLMs effectiveness. However, current methods have three unsolved issues: overlooking layer-wise sensitivity to KV cache quantization, high overhead of online fine-grained decision-making, and low flexibility to different LLMs and constraints. Therefore, we thoroughly analyze the inherent correlation of layer-wise transformer attention patterns to KV cache quantization errors and study why key cache is more important than value cache for quantization error reduction. We further propose a simple yet effective framework KVTuner to adaptively search for the optimal hardware-friendly layer-wise KV quantization precision pairs for coarse-grained KV cache with multi-objective optimization and directly utilize the offline searched configurations during online inference. To reduce the computational cost of offline calibration, we utilize the intra-layer KV precision pair pruning and inter-layer clustering to reduce the search space. Experimental results show that we can achieve nearly lossless 3.25-bit mixed precision KV cache quantization for LLMs like Llama-3.1-8B-Instruct and 4.0-bit for sensitive models like Qwen2.5-7B-Instruct on mathematical reasoning tasks. The maximum inference throughput can be improved by 38.3% compared with KV8 quantization over various context lengths.
FedAQ: Communication-Efficient Federated Edge Learning via Joint Uplink and Downlink Adaptive Quantization
Jun 26, 2024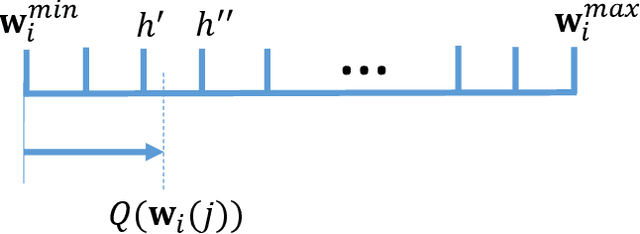

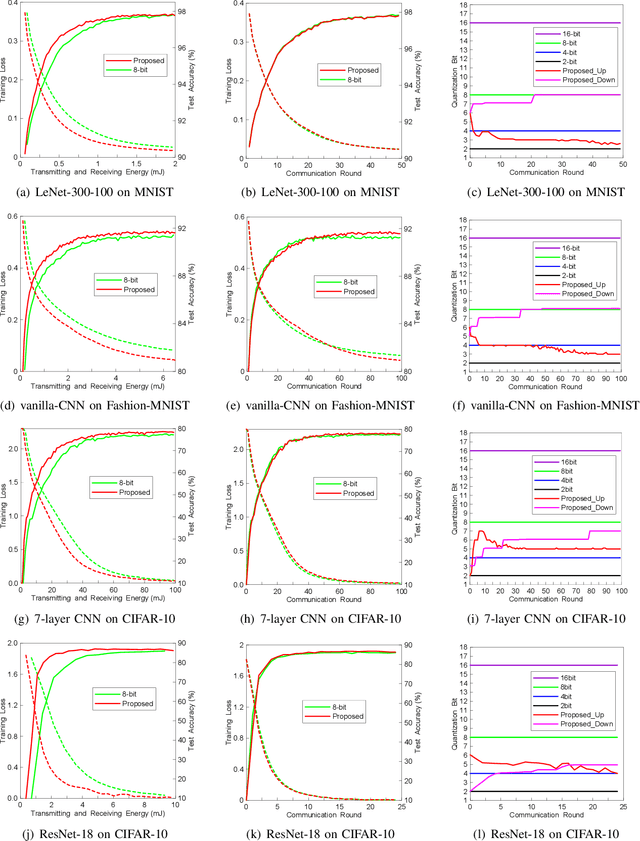

Federated learning (FL) is a powerful machine learning paradigm which leverages the data as well as the computational resources of clients, while protecting clients' data privacy. However, the substantial model size and frequent aggregation between the server and clients result in significant communication overhead, making it challenging to deploy FL in resource-limited wireless networks. In this work, we aim to mitigate the communication overhead by using quantization. Previous research on quantization has primarily focused on the uplink communication, employing either fixed-bit quantization or adaptive quantization methods. In this work, we introduce a holistic approach by joint uplink and downlink adaptive quantization to reduce the communication overhead. In particular, we optimize the learning convergence by determining the optimal uplink and downlink quantization bit-length, with a communication energy constraint. Theoretical analysis shows that the optimal quantization levels depend on the range of model gradients or weights. Based on this insight, we propose a decreasing-trend quantization for the uplink and an increasing-trend quantization for the downlink, which aligns with the change of the model parameters during the training process. Experimental results show that, the proposed joint uplink and downlink adaptive quantization strategy can save up to 66.7% energy compared with the existing schemes.
How Robust is Federated Learning to Communication Error? A Comparison Study Between Uplink and Downlink Channels
Oct 25, 2023
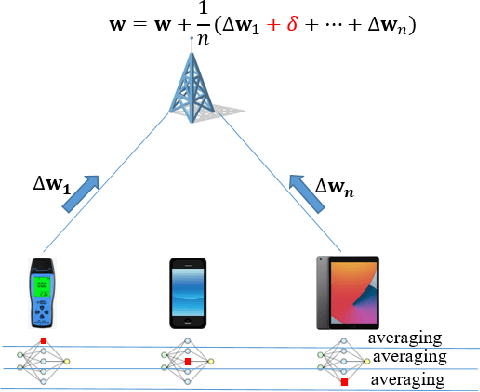
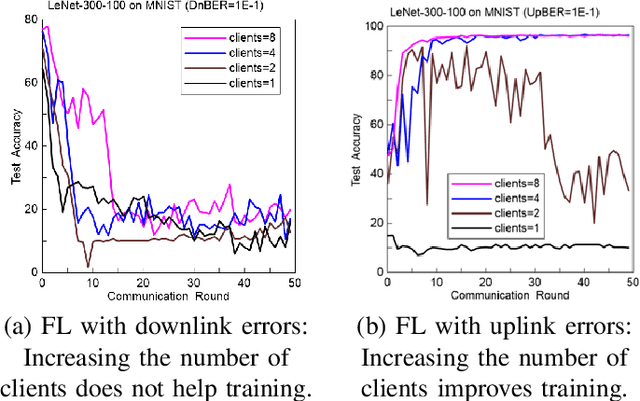
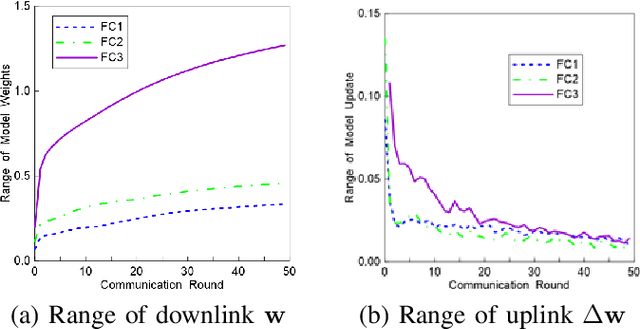
Because of its privacy-preserving capability, federated learning (FL) has attracted significant attention from both academia and industry. However, when being implemented over wireless networks, it is not clear how much communication error can be tolerated by FL. This paper investigates the robustness of FL to the uplink and downlink communication error. Our theoretical analysis reveals that the robustness depends on two critical parameters, namely the number of clients and the numerical range of model parameters. It is also shown that the uplink communication in FL can tolerate a higher bit error rate (BER) than downlink communication, and this difference is quantified by a proposed formula. The findings and theoretical analyses are further validated by extensive experiments.
FedDQ: Communication-Efficient Federated Learning with Descending Quantization
Oct 13, 2021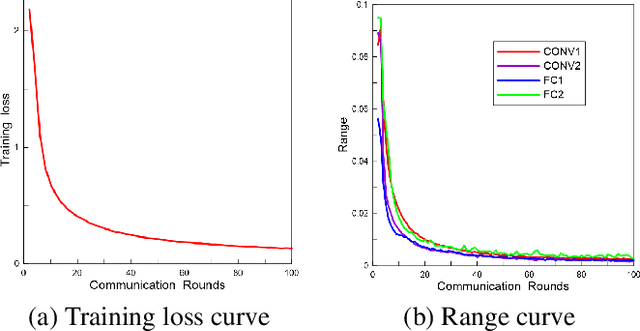

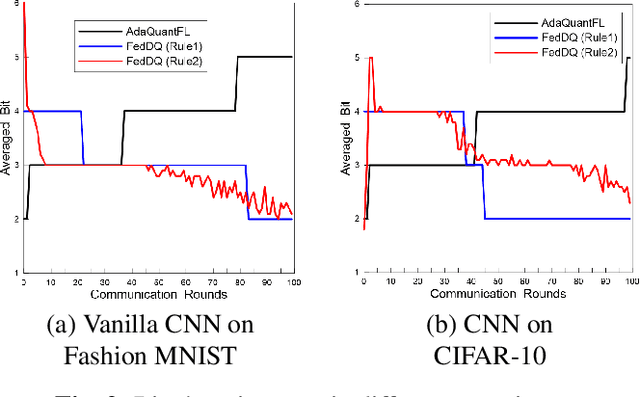
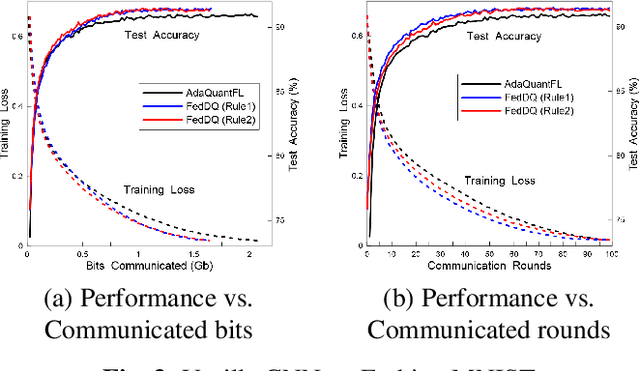
Federated learning (FL) is an emerging privacy-preserving distributed learning scheme. Due to the large model size and frequent model aggregation, FL suffers from critical communication bottleneck. Many techniques have been proposed to reduce the communication volume, including model compression and quantization. Existing adaptive quantization schemes use ascending-trend quantization where the quantizaion level increases with the training stages. In this paper, we formulate the problem as optimizing the training convergence rate for a given communication volume. The result shows that the optimal quantizaiton level can be represented by two factors, i.e., the training loss and the range of model updates, and it is preferable to decrease the quantization level rather than increase. Then, we propose two descending quantization schemes based on the training loss and model range. Experimental results show that proposed schemes not only reduce the communication volume but also help FL converge faster, when compared with current ascending quantization.