 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedAQ: Communication-Efficient Federated Edge Learning via Joint Uplink and Downlink Adaptive Quantization
Paper and Code
Jun 26, 2024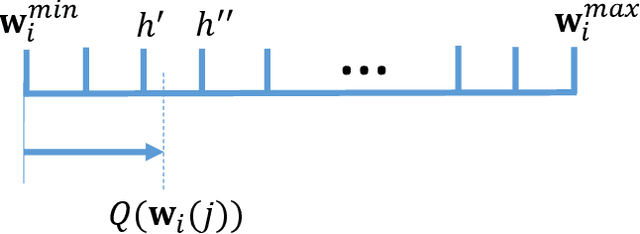

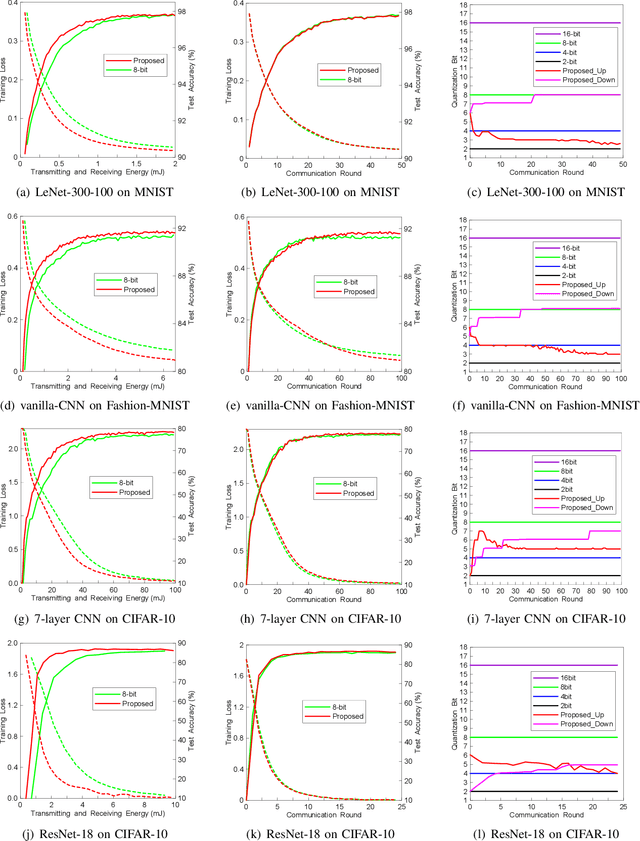

Federated learning (FL) is a powerful machine learning paradigm which leverages the data as well as the computational resources of clients, while protecting clients' data privacy. However, the substantial model size and frequent aggregation between the server and clients result in significant communication overhead, making it challenging to deploy FL in resource-limited wireless networks. In this work, we aim to mitigate the communication overhead by using quantization. Previous research on quantization has primarily focused on the uplink communication, employing either fixed-bit quantization or adaptive quantization methods. In this work, we introduce a holistic approach by joint uplink and downlink adaptive quantization to reduce the communication overhead. In particular, we optimize the learning convergence by determining the optimal uplink and downlink quantization bit-length, with a communication energy constraint. Theoretical analysis shows that the optimal quantization levels depend on the range of model gradients or weights. Based on this insight, we propose a decreasing-trend quantization for the uplink and an increasing-trend quantization for the downlink, which aligns with the change of the model parameters during the training process. Experimental results show that, the proposed joint uplink and downlink adaptive quantization strategy can save up to 66.7% energy compared with the existing schemes.