 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Multi-Modal Edge Inference via Uncertainty-Aware Distributed Learning
Jan 21, 2026Semantic communication is emerging as a key enabler for distributed edge intelligence due to its capability to convey task-relevant meaning. However, achieving communication-efficient training and robust inference over wireless links remains challenging. This challenge is further exacerbated for multi-modal edge inference (MMEI) by two factors: 1) prohibitive communication overhead for distributed learning over bandwidth-limited wireless links, due to the \emph{multi-modal} nature of the system; and 2) limited robustness under varying channels and noisy multi-modal inputs. In this paper, we propose a three-stage communication-aware distributed learning framework to improve training and inference efficiency while maintaining robustness over wireless channels. In Stage~I, devices perform local multi-modal self-supervised learning to obtain shared and modality-specific encoders without device--server exchange, thereby reducing the communication cost. In Stage~II, distributed fine-tuning with centralized evidential fusion calibrates per-modality uncertainty and reliably aggregates features distorted by noise or channel fading. In Stage~III, an uncertainty-guided feedback mechanism selectively requests additional features for uncertain samples, optimizing the communication--accuracy tradeoff in the distributed setting. Experiments on RGB--depth indoor scene classification show that the proposed framework attains higher accuracy with far fewer training communication rounds and remains robust to modality degradation or channel variation, outperforming existing self-supervised and fully supervised baselines.
Near-Field Communication with Massive Movable Antennas: An Electrostatic Equilibrium Perspective
Dec 25, 2025Recent advancements in large-scale position-reconfigurable antennas have opened up new dimensions to effectively utilize the spatial degrees of freedom (DoFs) of wireless channels. However, the deployment of existing antenna placement schemes is primarily hindered by their limited scalability and frequently overlooked near-field effects in large-scale antenna systems. In this paper, we propose a novel antenna placement approach tailored for near-field massive multiple-input multiple-output systems, which effectively exploits the spatial DoFs to enhance spectral efficiency. For that purpose, we first reformulate the antenna placement problem in the angular domain, resulting in a weighted Fekete problem. We then derive the optimality condition and reveal that the {optimal} antenna placement is in principle an electrostatic equilibrium problem. To further reduce the computational complexity of numerical optimization, we propose an ordinary differential equation (ODE)-based framework to efficiently solve the equilibrium problem. In particular, the optimal antenna positions are characterized by the roots of the polynomial solutions to specific ODEs in the normalized angular domain. By simply adopting a two-step eigenvalue decomposition (EVD) approach, the optimal antenna positions can be efficiently obtained. Furthermore, we perform an asymptotic analysis when the antenna size tends to infinity, which yields a closed-form solution. Simulation results demonstrate that the proposed scheme efficiently harnesses the spatial DoFs of near-field channels with prominent gains in spectral efficiency and maintains robustness against system parameter mismatches. In addition, the derived asymptotic closed-form {solution} closely approaches the theoretical optimum across a wide range of practical scenarios.
ROI-based Deep Image Compression with Implicit Bit Allocation
Nov 12, 2025Region of Interest (ROI)-based image compression has rapidly developed due to its ability to maintain high fidelity in important regions while reducing data redundancy. However, existing compression methods primarily apply masks to suppress background information before quantization. This explicit bit allocation strategy, which uses hard gating, significantly impacts the statistical distribution of the entropy model, thereby limiting the coding performance of the compression model. In response, this work proposes an efficient ROI-based deep image compression model with implicit bit allocation. To better utilize ROI masks for implicit bit allocation, this paper proposes a novel Mask-Guided Feature Enhancement (MGFE) module, comprising a Region-Adaptive Attention (RAA) block and a Frequency-Spatial Collaborative Attention (FSCA) block. This module allows for flexible bit allocation across different regions while enhancing global and local features through frequencyspatial domain collaboration. Additionally, we use dual decoders to separately reconstruct foreground and background images, enabling the coding network to optimally balance foreground enhancement and background quality preservation in a datadriven manner. To the best of our knowledge, this is the first work to utilize implicit bit allocation for high-quality regionadaptive coding. Experiments on the COCO2017 dataset show that our implicit-based image compression method significantly outperforms explicit bit allocation approaches in rate-distortion performance, achieving optimal results while maintaining satisfactory visual quality in the reconstructed background regions.
FedLAM: Low-latency Wireless Federated Learning via Layer-wise Adaptive Modulation
Oct 09, 2025In wireless federated learning (FL), the clients need to transmit the high-dimensional deep neural network (DNN) parameters through bandwidth-limited channels, which causes the communication latency issue. In this paper, we propose a layer-wise adaptive modulation scheme to save the communication latency. Unlike existing works which assign the same modulation level for all DNN layers, we consider the layers' importance which provides more freedom to save the latency. The proposed scheme can automatically decide the optimal modulation levels for different DNN layers. Experimental results show that the proposed scheme can save up to 73.9% of communication latency compared with the existing schemes.
Bistatic Target Detection by Exploiting Both Deterministic Pilots and Unknown Random Data Payloads
Aug 26, 2025Integrated sensing and communication (ISAC) plays a crucial role in 6G, to enable innovative applications such as drone surveillance, urban air mobility, and low-altitude logistics. However, the hybrid ISAC signal, which comprises deterministic pilot and random data payload components, poses challenges for target detection due to two reasons: 1) these two components cause coupled shifts in both the mean and variance of the received signal, and 2) the random data payloads are typically unknown to the sensing receiver in the bistatic setting. Unfortunately, these challenges could not be tackled by existing target detection algorithms. In this paper, a generalized likelihood ratio test (GLRT)-based detector is derived, by leveraging the known deterministic pilots and the statistical characteristics of the unknown random data payloads. Due to the analytical intractability of exact performance characterization, we perform an asymptotic analysis for the false alarm probability and detection probability of the proposed detector. The results highlight a critical trade-off: both deterministic and random components improve detection reliability, but the latter also brings statistical uncertainty that hinders detection performance. Simulations validate the theoretical findings and demonstrate the effectiveness of the proposed detector, which highlights the necessity of designing a dedicated detector to fully exploited the signaling resources assigned to random data payloads.
Joint Radiation Power, Antenna Position, and Beamforming Optimization for Pinching-Antenna Systems with Motion Power Consumption
Jul 03, 2025



Pinching-antenna systems (PASS) have been recently proposed to improve the performance of wireless networks by reconfiguring both the large-scale and small-scale channel conditions. However, existing studies ignore the physical constraints of antenna placement and assume fixed antenna radiation power. To fill this research gap, this paper investigates the design of PASS taking into account the motion power consumption of pinching-antennas (PAs) and the impact of adjustable antenna radiation power. To that end, we minimize the average power consumption for a given quality-of-service (QoS) requirement, by jointly optimizing the antenna positions, antenna radiation power ratios, and transmit beamforming. To the best of the authors' knowledge, this is the first work to consider radiation power optimization in PASS, which provides an additional degree of freedom (DoF) for system design. The cases with both continuous and discrete antenna placement are considered, where the main challenge lies in the fact that the antenna positions affect both the magnitude and phase of the channel coefficients of PASS, making system optimization very challenging. To tackle the resulting unique obstacles, an alternating direction method of multipliers (ADMM)-based framework is proposed to solve the problem for continuous antenna movement, while its discrete counterpart is formulated as a mixed integer nonlinear programming (MINLP) problem and solved by the block coordinate descent (BCD) method. Simulation results validate the performance enhancement achieved by incorporating PA movement power assumption and adjustable radiation power into PASS design, while also demonstrating the efficiency of the proposed optimization framework. The benefits of PASS over conventional multiple-input multiple-output (MIMO) systems in mitigating the large-scale path loss and inter-user interference is also revealed.
Fluid Antenna-Assisted MU-MIMO Systems with Decentralized Baseband Processing
May 08, 2025The fluid antenna system (FAS) has emerged as a disruptive technology, offering unprecedented degrees of freedom (DoF) for wireless communication systems. However, optimizing fluid antenna (FA) positions entails significant computational costs, especially when the number of FAs is large. To address this challenge, we introduce a decentralized baseband processing (DBP) architecture to FAS, which partitions the FA array into clusters and enables parallel processing. Based on the DBP architecture, we formulate a weighted sum rate (WSR) maximization problem through joint beamforming and FA position design for FA-assisted multiuser multiple-input multiple-output (MU-MIMO) systems. To solve the WSR maximization problem, we propose a novel decentralized block coordinate ascent (BCA)-based algorithm that leverages matrix fractional programming (FP) and majorization-minimization (MM) methods. The proposed decentralized algorithm achieves low computational, communication, and storage costs, thus unleashing the potential of the DBP architecture. Simulation results show that our proposed algorithm under the DBP architecture reduces computational time by over 70% compared to centralized architectures with negligible WSR performance loss.
Accurate and Fast Channel Estimation for Fluid Antenna Systems with Diffusion Models
May 08, 2025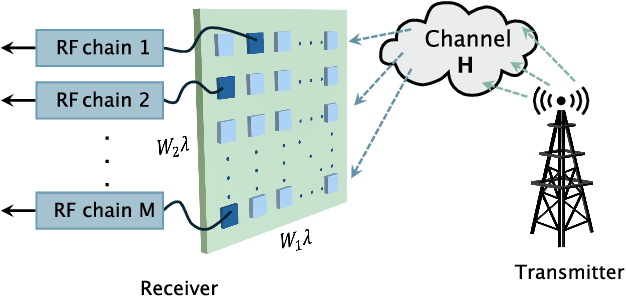
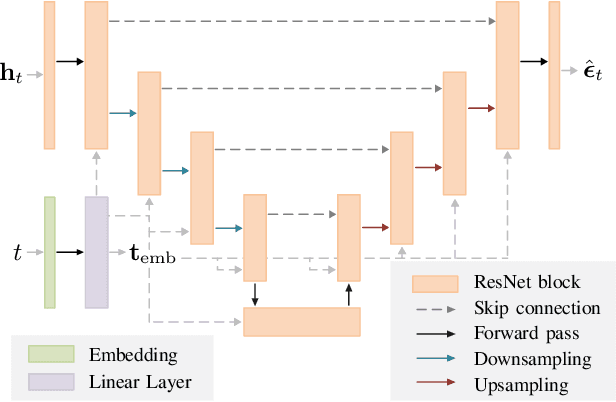
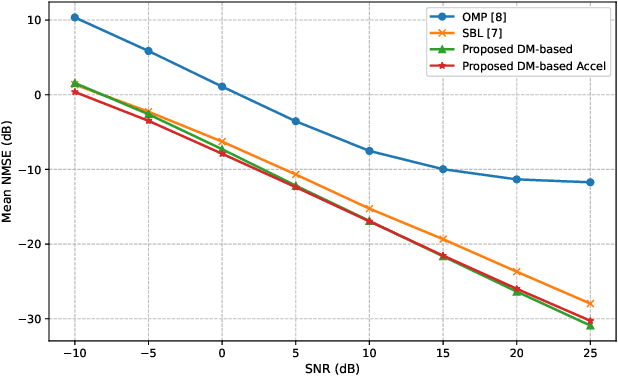

Fluid antenna systems (FAS) offer enhanced spatial diversity for next-generation wireless systems. However, acquiring accurate channel state information (CSI) remains challenging due to the large number of reconfigurable ports and the limited availability of radio-frequency (RF) chains -- particularly in high-dimensional FAS scenarios. To address this challenge, we propose an efficient posterior sampling-based channel estimator that leverages a diffusion model (DM) with a simplified U-Net architecture to capture the spatial correlation structure of two-dimensional FAS channels. The DM is initially trained offline in an unsupervised way and then applied online as a learned implicit prior to reconstruct CSI from partial observations via posterior sampling through a denoising diffusion restoration model (DDRM). To accelerate the online inference, we introduce a skipped sampling strategy that updates only a subset of latent variables during the sampling process, thereby reducing the computational cost with minimal accuracy degradation. Simulation results demonstrate that the proposed approach achieves significantly higher estimation accuracy and over 20x speedup compared to state-of-the-art compressed sensing-based methods, highlighting its potential for practical deployment in high-dimensional FAS.
Multimodal Deep Learning-Empowered Beam Prediction in Future THz ISAC Systems
May 05, 2025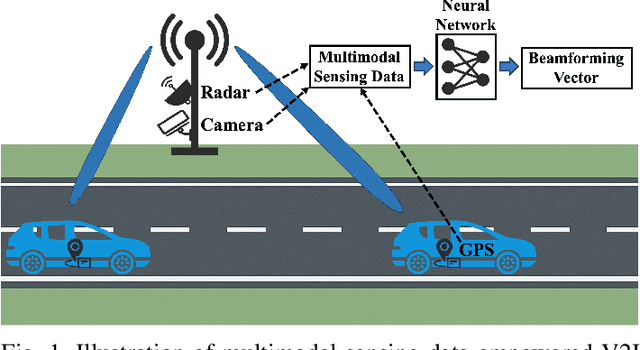
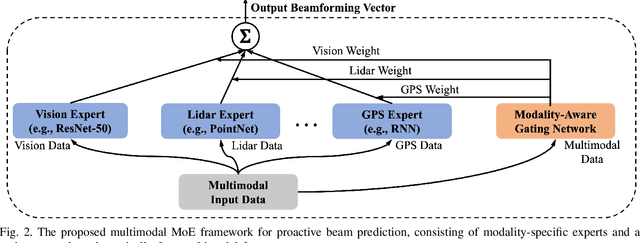
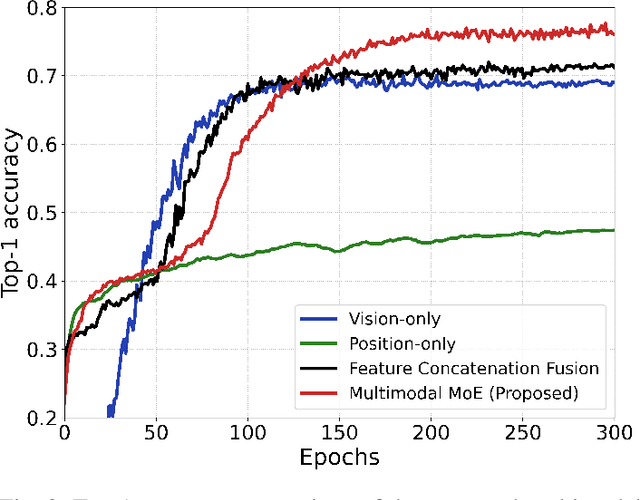
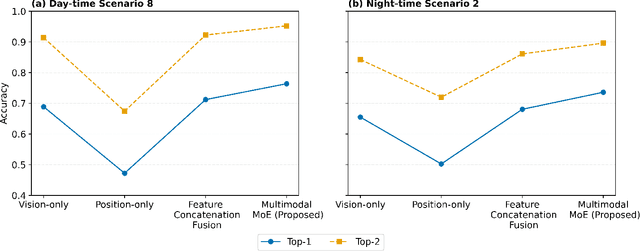
Integrated sensing and communication (ISAC) systems operating at terahertz (THz) bands are envisioned to enable both ultra-high data-rate communication and precise environmental awareness for next-generation wireless networks. However, the narrow width of THz beams makes them prone to misalignment and necessitates frequent beam prediction in dynamic environments. Multimodal sensing, which integrates complementary modalities such as camera images, positional data, and radar measurements, has recently emerged as a promising solution for proactive beam prediction. Nevertheless, existing multimodal approaches typically employ static fusion architectures that cannot adjust to varying modality reliability and contributions, thereby degrading predictive performance and robustness. To address this challenge, we propose a novel and efficient multimodal mixture-of-experts (MoE) deep learning framework for proactive beam prediction in THz ISAC systems. The proposed multimodal MoE framework employs multiple modality-specific expert networks to extract representative features from individual sensing modalities, and dynamically fuses them using adaptive weights generated by a gating network according to the instantaneous reliability of each modality. Simulation results in realistic vehicle-to-infrastructure (V2I) scenarios demonstrate that the proposed MoE framework outperforms traditional static fusion methods and unimodal baselines in terms of prediction accuracy and adaptability, highlighting its potential in practical THz ISAC systems with ultra-massive multiple-input multiple-output (MIMO).
Mutual Information-Empowered Task-Oriented Communication: Principles, Applications and Challenges
Mar 26, 2025



Mutual information (MI)-based guidelines have recently proven to be effective for designing task-oriented communication systems, where the ultimate goal is to extract and transmit task-relevant information for downstream task. This paper provides a comprehensive overview of MI-empowered task-oriented communication, highlighting how MI-based methods can serve as a unifying design framework in various task-oriented communication scenarios. We begin with the roadmap of MI for designing task-oriented communication systems, and then introduce the roles and applications of MI to guide feature encoding, transmission optimization, and efficient training with two case studies. We further elaborate the limitations and challenges of MI-based methods. Finally, we identify several open issues in MI-based task-oriented communication to inspire future research.