 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamese Machine Unlearning with Knowledge Vaporization and Concentration
Paper and Code
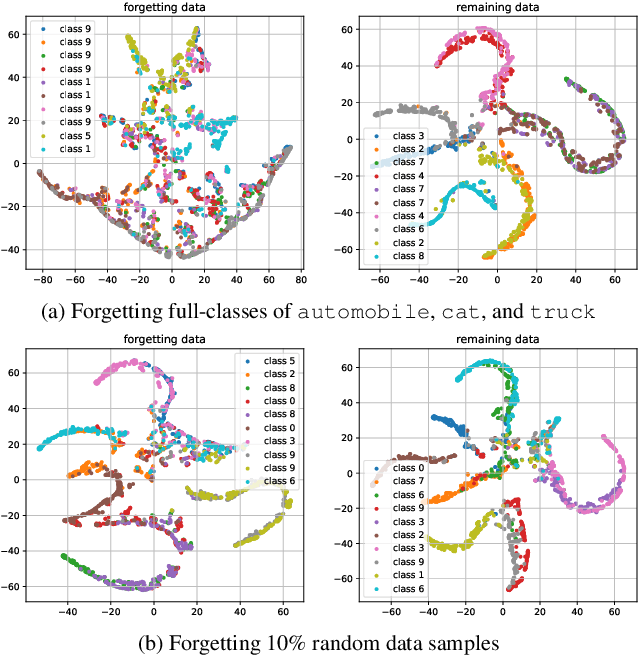
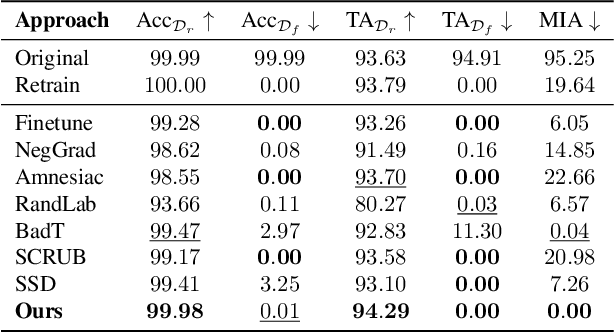
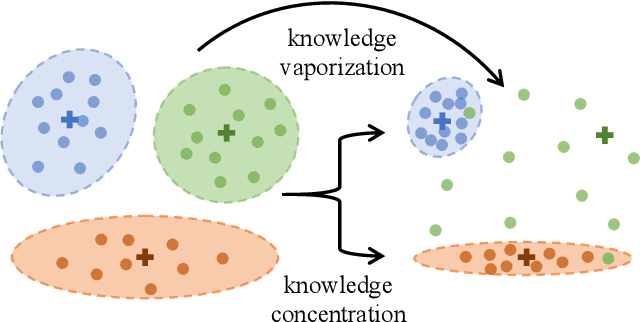
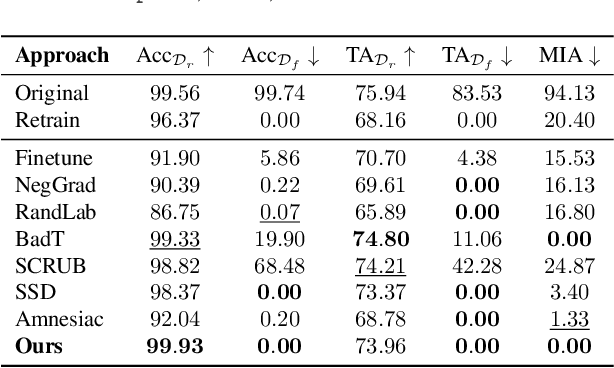
In response to the practical demands of the ``right to be forgotten" and the removal of undesired data, machine unlearning emerges as an essential technique to remove the learned knowledge of a fraction of data points from trained models. However, existing methods suffer from limitations such as insufficient methodological support, high computational complexity, and significant memory demands. In this work, we propose the concepts of knowledge vaporization and concentration to selectively erase learned knowledge from specific data points while maintaining representations for the remaining data. Utilizing the Siamese networks, we exemplify the proposed concepts and develop an efficient method for machine unlearning. Our proposed Siamese unlearning method does not require additional memory overhead and full access to the remaining dataset. Extensive experiments conducted across multiple unlearning scenarios showcase the superiority of Siamese unlearning over baseline methods, illustrating its ability to effectively remove knowledge from forgetting data, enhance model utility on remaining data, and reduce susceptibility to membership inference attacks.