 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging simulation and reality in subsurface radar-based sensing: physics-guided hierarchical domain adaptation with deep adversarial learning
Dec 19, 2025Accurate estimation of subsurface material properties, such as soil moisture, is critical for wildfire risk assessment and precision agriculture. Ground-penetrating radar (GPR) is a non-destructive geophysical technique widely used to characterize subsurface conditions. Data-driven parameter estimation methods typically require large amounts of labeled training data, which is expensive to obtain from real-world GPR scans under diverse subsurface conditions. A physics-based GPR model using the finite-difference time-domain (FDTD) method can be employed to generate large synthetic datasets through simulations across varying material parameters, which are then utilized to train data-driven models. A key limitation, however, is that simulated data (source domain) and real-world data (target domain) often follow different distributions, which can cause data-driven models trained on simulations to underperform in real-world scenarios. To address this challenge, this study proposes a novel physics-guided hierarchical domain adaptation framework with deep adversarial learning for robust subsurface material property estimation from GPR signals. The proposed framework is systematically evaluated through the laboratory tests for single- and two-layer materials, as well as the field tests for single- and two-layer materials, and is benchmarked against state-of-the-art methods, including the one-dimensional convolutional neural network (1D CNN) and domain adversarial neural network (DANN). The results demonstrate that the proposed framework achieves higher correlation coefficients R and lower Bias between the predicted and measured parameter values, along with smaller standard deviations in the estimations, thereby validating their effectiveness in bridging the domain gap between simulated and real-world radar signals and enabling efficient subsurface material property retrieval.
TalkCuts: A Large-Scale Dataset for Multi-Shot Human Speech Video Generation
Oct 08, 2025In this work, we present TalkCuts, a large-scale dataset designed to facilitate the study of multi-shot human speech video generation. Unlike existing datasets that focus on single-shot, static viewpoints, TalkCuts offers 164k clips totaling over 500 hours of high-quality human speech videos with diverse camera shots, including close-up, half-body, and full-body views. The dataset includes detailed textual descriptions, 2D keypoints and 3D SMPL-X motion annotations, covering over 10k identities, enabling multimodal learning and evaluation. As a first attempt to showcase the value of the dataset, we present Orator, an LLM-guided multi-modal generation framework as a simple baseline, where the language model functions as a multi-faceted director, orchestrating detailed specifications for camera transitions, speaker gesticulations, and vocal modulation. This architecture enables the synthesis of coherent long-form videos through our integrated multi-modal video generation module. Extensive experiments in both pose-guided and audio-driven settings show that training on TalkCuts significantly enhances the cinematographic coherence and visual appeal of generated multi-shot speech videos. We believe TalkCuts provides a strong foundation for future work in controllable, multi-shot speech video generation and broader multimodal learning.
EnergyPatchTST: Multi-scale Time Series Transformers with Uncertainty Estimation for Energy Forecasting
Aug 07, 2025Accurate and reliable energy time series prediction is of great significance for power generation planning and allocation. At present, deep learning time series prediction has become the mainstream method. However, the multi-scale time dynamics and the irregularity of real data lead to the limitations of the existing methods. Therefore, we propose EnergyPatchTST, which is an extension of the Patch Time Series Transformer specially designed for energy forecasting. The main innovations of our method are as follows: (1) multi-scale feature extraction mechanism to capture patterns with different time resolutions; (2) probability prediction framework to estimate uncertainty through Monte Carlo elimination; (3) integration path of future known variables (such as temperature and wind conditions); And (4) Pre-training and Fine-tuning examples to enhance the performance of limited energy data sets. A series of experiments on common energy data sets show that EnergyPatchTST is superior to other commonly used methods, the prediction error is reduced by 7-12%, and reliable uncertainty estimation is provided, which provides an important reference for time series prediction in the energy field.
* Accepted for publication at the International Conference on Intelligent Computing (ICIC 2025). 12 pages. The final authenticated version is published in the Lecture Notes in Computer Science (LNCS) series, vol 15860, and is available online. This is the author's version of the work submitted for peer review
Edge Large AI Models: Collaborative Deployment and IoT Applications
May 06, 2025



Large artificial intelligence models (LAMs) emulate human-like problem-solving capabilities across diverse domains, modalities, and tasks. By leveraging the communication and computation resources of geographically distributed edge devices, edge LAMs enable real-time intelligent services at the network edge. Unlike conventional edge AI, which relies on small or moderate-sized models for direct feature-to-prediction mappings, edge LAMs leverage the intricate coordination of modular components to enable context-aware generative tasks and multi-modal inference. We shall propose a collaborative deployment framework for edge LAM by characterizing the LAM intelligent capabilities and limited edge network resources. Specifically, we propose a collaborative training framework over heterogeneous edge networks that adaptively decomposes LAMs according to computation resources, data modalities, and training objectives, reducing communication and computation overheads during the fine-tuning process. Furthermore, we introduce a microservice-based inference framework that virtualizes the functional modules of edge LAMs according to their architectural characteristics, thereby improving resource utilization and reducing inference latency. The developed edge LAM will provide actionable solutions to enable diversified Internet-of-Things (IoT) applications, facilitated by constructing mappings from diverse sensor data to token representations and fine-tuning based on domain knowledge.
Edge Large AI Models: Revolutionizing 6G Networks
May 01, 2025Large artificial intelligence models (LAMs) possess human-like abilities to solve a wide range of real-world problems, exemplifying the potential of experts in various domains and modalities. By leveraging the communication and computation capabilities of geographically dispersed edge devices, edge LAM emerges as an enabling technology to empower the delivery of various real-time intelligent services in 6G. Unlike traditional edge artificial intelligence (AI) that primarily supports a single task using small models, edge LAM is featured by the need of the decomposition and distributed deployment of large models, and the ability to support highly generalized and diverse tasks. However, due to limited communication, computation, and storage resources over wireless networks, the vast number of trainable neurons and the substantial communication overhead pose a formidable hurdle to the practical deployment of edge LAMs. In this paper, we investigate the opportunities and challenges of edge LAMs from the perspectives of model decomposition and resource management. Specifically, we propose collaborative fine-tuning and full-parameter training frameworks, alongside a microservice-assisted inference architecture, to enhance the deployment of edge LAM over wireless networks. Additionally, we investigate the application of edge LAM in air-interface designs, focusing on channel prediction and beamforming. These innovative frameworks and applications offer valuable insights and solutions for advancing 6G technology.
Mutual Information-Empowered Task-Oriented Communication: Principles, Applications and Challenges
Mar 26, 2025



Mutual information (MI)-based guidelines have recently proven to be effective for designing task-oriented communication systems, where the ultimate goal is to extract and transmit task-relevant information for downstream task. This paper provides a comprehensive overview of MI-empowered task-oriented communication, highlighting how MI-based methods can serve as a unifying design framework in various task-oriented communication scenarios. We begin with the roadmap of MI for designing task-oriented communication systems, and then introduce the roles and applications of MI to guide feature encoding, transmission optimization, and efficient training with two case studies. We further elaborate the limitations and challenges of MI-based methods. Finally, we identify several open issues in MI-based task-oriented communication to inspire future research.
Federated Low-Rank Adaptation with Differential Privacy over Wireless Networks
Nov 12, 2024Fine-tuning large pre-trained foundation models (FMs) on distributed edge devices presents considerable computational and privacy challenges. Federated fine-tuning (FedFT) mitigates some privacy issues by facilitating collaborative model training without the need to share raw data. To lessen the computational burden on resource-limited devices, combining low-rank adaptation (LoRA) with federated learning enables parameter-efficient fine-tuning. Additionally, the split FedFT architecture partitions an FM between edge devices and a central server, reducing the necessity for complete model deployment on individual devices. However, the risk of privacy eavesdropping attacks in FedFT remains a concern, particularly in sensitive areas such as healthcare and finance. In this paper, we propose a split FedFT framework with differential privacy (DP) over wireless networks, where the inherent wireless channel noise in the uplink transmission is utilized to achieve DP guarantees without adding an extra artificial noise. We shall investigate the impact of the wireless noise on convergence performance of the proposed framework. We will also show that by updating only one of the low-rank matrices in the split FedFT with DP, the proposed method can mitigate the noise amplification effect. Simulation results will demonstrate that the proposed framework achieves higher accuracy under strict privacy budgets compared to baseline methods.
Tokens on Demand: Token Condensation as Training-free Test-time Adaptation
Oct 16, 2024In this work, we introduce Token Condensation as Adaptation (TCA), a training-free approach designed to mitigate distribution shifts encountered by vision-language models (VLMs) during test-time inference. TCA bridges distribution gaps at the patch level by condensing image tokens that exhibit low attentiveness to the <cls> token. Recognizing the <cls> token may correspond to universal concepts, TCA identifies and tracks the most reliable <cls> tokens that align specifically with target classes from historical data streams. To achieve this, we propose a context token reservoir (CTR), which retains tokens with the lowest uncertainty as ``anchors" to guide the preservation of class-relevant tokens during inference. These anchors, in turn, act as token-level classifiers to correct VLM predictions and improve visual-text alignment. Utilizing anchors sampled from CTR, TCA condenses tokens through two operations: (1) pruning class-irrelevant tokens that consistently rank low across all attention heads to reach cross-head consensus on their irrelevance, and (2) merging the remaining class-ambiguous tokens into representative centers using coreset selection, maintaining linear computational complexity. As the first method to explore token efficiency in test-time adaptation, TCA consistently demonstrates superior performance across cross-dataset and out-of-distribution adaptation tasks, reducing GFLOPs by 12.2% to 48.9% while achieving accuracy improvements up to 21.4% against the strongest baseline without introducing additional parameters.
Research on Improved U-net Based Remote Sensing Image Segmentation Algorithm
Aug 22, 2024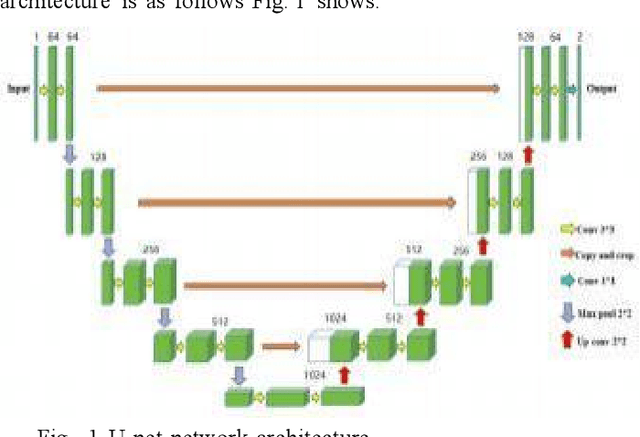
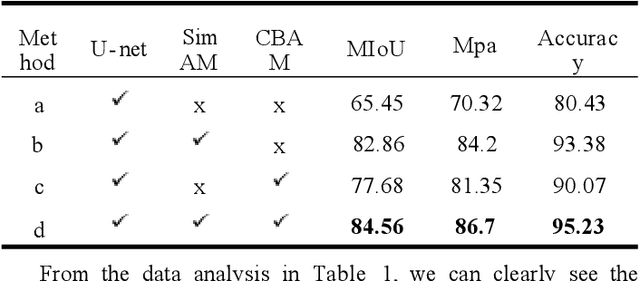
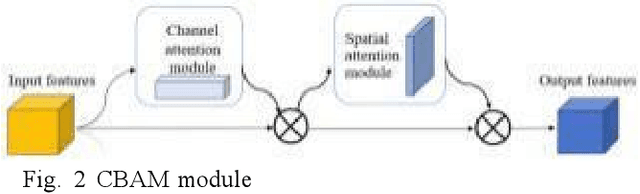
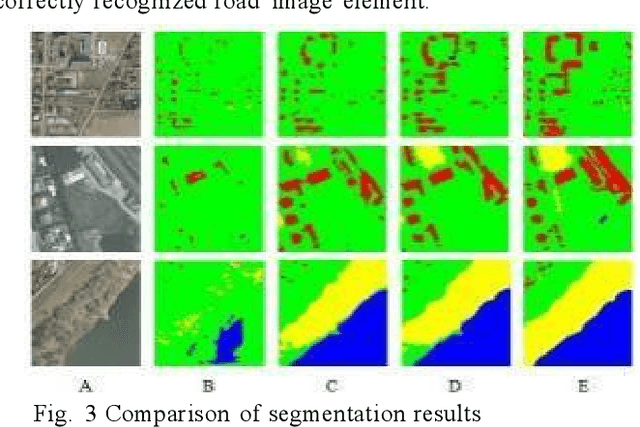
In recent years, although U-Net network has made significant progress in the field of image segmentation, it still faces performance bottlenecks in remote sensing image segmentation. In this paper, we innovatively propose to introduce SimAM and CBAM attention mechanism in U-Net, and the experimental results show that after adding SimAM and CBAM modules alone, the model improves 17.41% and 12.23% in MIoU, and the Mpa and Accuracy are also significantly improved. And after fusing the two,the model performance jumps up to 19.11% in MIoU, and the Mpa and Accuracy are also improved by 16.38% and 14.8% respectively, showing excellent segmentation accuracy and visual effect with strong generalization ability and robustness. This study opens up a new path for remote sensing image segmentation technology and has important reference value for algorithm selection and improvement.
DNA-SE: Towards Deep Neural-Nets Assisted Semiparametric Estimation
Aug 04, 2024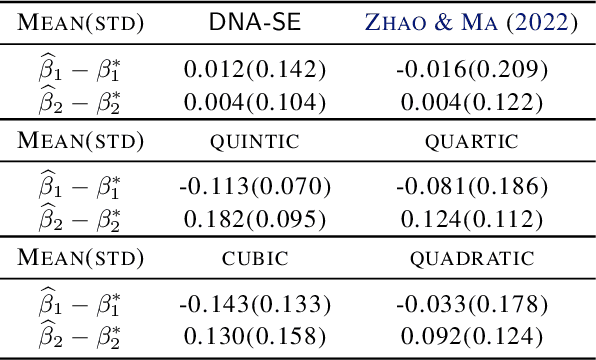
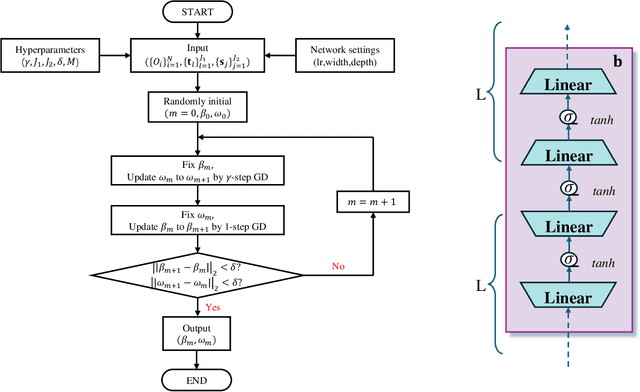

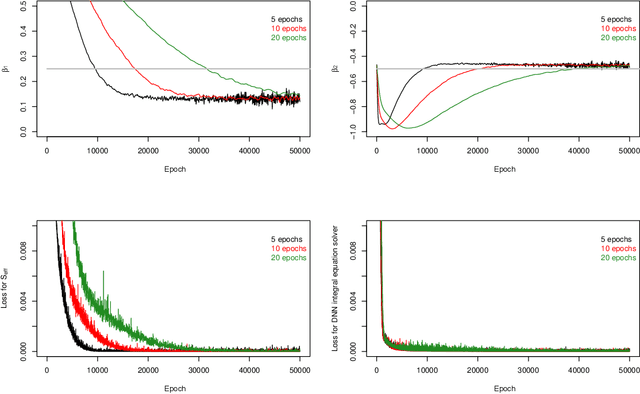
Semiparametric statistics play a pivotal role in a wide range of domains, including but not limited to missing data, causal inference, and transfer learning, to name a few. In many settings, semiparametric theory leads to (nearly) statistically optimal procedures that yet involve numerically solving Fredholm integral equations of the second kind. Traditional numerical methods, such as polynomial or spline approximations, are difficult to scale to multi-dimensional problems. Alternatively, statisticians may choose to approximate the original integral equations by ones with closed-form solutions, resulting in computationally more efficient, but statistically suboptimal or even incorrect procedures. To bridge this gap, we propose a novel framework by formulating the semiparametric estimation problem as a bi-level optimization problem; and then we develop a scalable algorithm called Deep Neural-Nets Assisted Semiparametric Estimation (DNA-SE) by leveraging the universal approximation property of Deep Neural-Nets (DNN) to streamline semiparametric procedures. Through extensive numerical experiments and a real data analysis, we demonstrate the numerical and statistical advantages of $\dnase$ over traditional methods. To the best of our knowledge, we are the first to bring DNN into semiparametric statistics as a numerical solver of integral equations in our proposed general framework.