 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning for Data Market: Shapley-UCB for Seller Selection and Incentives
Oct 10, 2024In recent years, research on the data trading market has been continuously deepened. In the transaction process, there is an information asymmetry process between agents and sellers. For sellers, direct data delivery faces the risk of privacy leakage. At the same time, sellers are not willing to provide data. A reasonable compensation method is needed to encourage sellers to provide data resources. For agents, the quality of data provided by sellers needs to be examined and evaluated. Otherwise, agents may consume too much cost and resources by recruiting sellers with poor data quality. Therefore, it is necessary to build a complete delivery process for the interaction between sellers and agents in the trading market so that the needs of sellers and agents can be met. The federated learning architecture is widely used in the data market due to its good privacy protection. Therefore, in this work, in response to the above challenges, we propose a transaction framework based on the federated learning architecture, and design a seller selection algorithm and incentive compensation mechanism. Specifically, we use gradient similarity and Shapley algorithm to fairly and accurately evaluate the contribution of sellers, and use the modified UCB algorithm to select sellers. After the training, fair compensation is made according to the seller's participation in the training. In view of the above work, we designed reasonable experiments for demonstration and obtained results, proving the rationality and effectiveness of the framework.
Machine Unlearning in Contrastive Learning
May 12, 2024Machine unlearning is a complex process that necessitates the model to diminish the influence of the training data while keeping the loss of accuracy to a minimum. Despite the numerous studies on machine unlearning in recent years, the majority of them have primarily focused on supervised learning models, leaving research on contrastive learning models relatively underexplored. With the conviction that self-supervised learning harbors a promising potential, surpassing or rivaling that of supervised learning, we set out to investigate methods for machine unlearning centered around contrastive learning models. In this study, we introduce a novel gradient constraint-based approach for training the model to effectively achieve machine unlearning. Our method only necessitates a minimal number of training epochs and the identification of the data slated for unlearning. Remarkably, our approach demonstrates proficient performance not only on contrastive learning models but also on supervised learning models, showcasing its versatility and adaptability in various learning paradigms.
Data Trading Combination Auction Mechanism based on the Exponential Mechanism
May 12, 2024With the widespread application of machine learning technology in recent years, the demand for training data has increased significantly, leading to the emergence of research areas such as data trading. The work in this field is still in the developmental stage. Different buyers have varying degrees of demand for various types of data, and auctions play a role in such scenarios due to their authenticity and fairness. Recent related work has proposed combination auction mechanisms for different domains. However, such mechanisms have not addressed the privacy concerns of buyers. In this paper, we design a \textit{Data Trading Combination Auction Mechanism based on the exponential mechanism} (DCAE) to protect buyers' bidding privacy from being leaked. We apply the exponential mechanism to select the final settlement price for the auction and generate a probability distribution based on the relationship between the price and the revenue. In the experimental aspect, we consider the selection of different mechanisms under two scenarios, and the experimental results show that this method can ensure high auction revenue and protect buyers' privacy from being violated.
Machine unlearning via GAN
Nov 22, 2021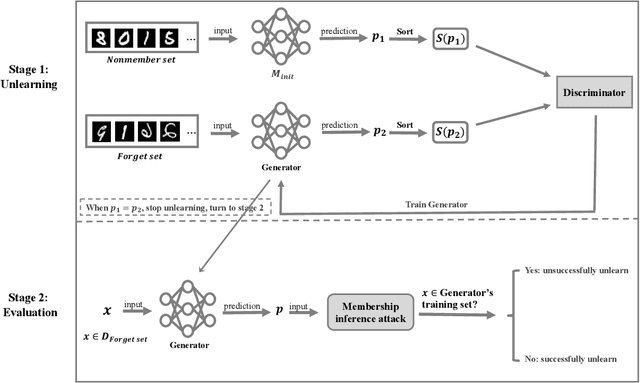

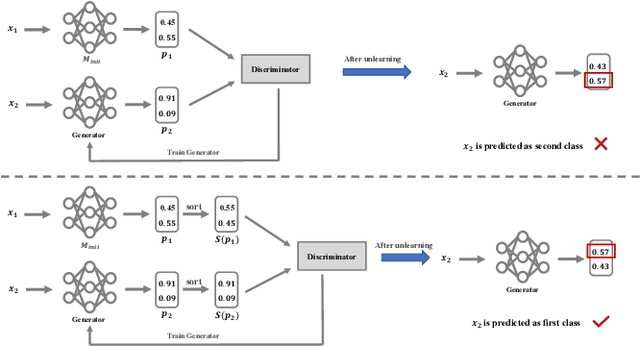
Machine learning models, especially deep models, may unintentionally remember information about their training data. Malicious attackers can thus pilfer some property about training data by attacking the model via membership inference attack or model inversion attack. Some regulations, such as the EU's GDPR, have enacted "The Right to Be Forgotten" to protect users' data privacy, enhancing individuals' sovereignty over their data. Therefore, removing training data information from a trained model has become a critical issue. In this paper, we present a GAN-based algorithm to delete data in deep models, which significantly improves deleting speed compared to retraining from scratch, especially in complicated scenarios. We have experimented on five commonly used datasets, and the experimental results show the efficiency of our method.
Lightweight machine unlearning in neural network
Nov 10, 2021
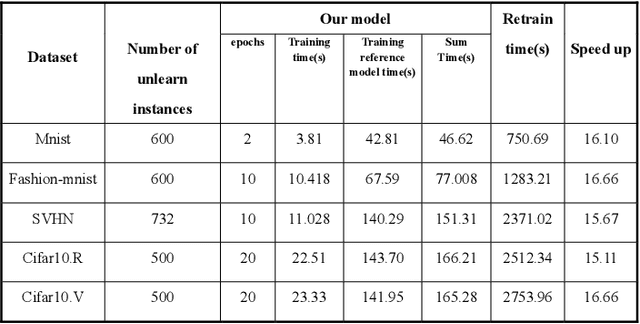
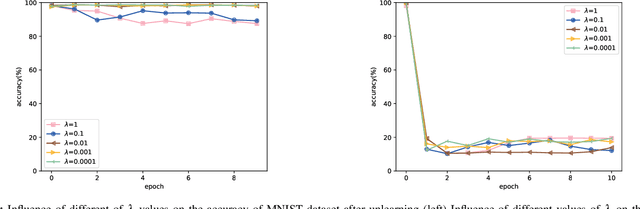
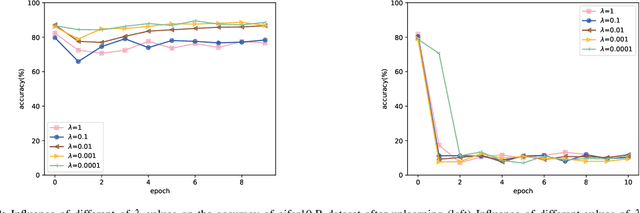
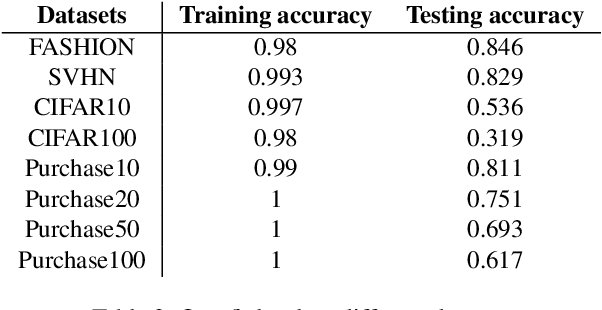
In recent years, machine learning neural network has penetrated deeply into people's life. As the price of convenience, people's private information also has the risk of disclosure. The "right to be forgotten" was introduced in a timely manner, stipulating that individuals have the right to withdraw their consent from personal information processing activities based on their consent. To solve this problem, machine unlearning is proposed, which allows the model to erase all memory of private information. Previous studies, including retraining and incremental learning to update models, often take up extra storage space or are difficult to apply to neural networks. Our method only needs to make a small perturbation of the weight of the target model and make it iterate in the direction of the model trained with the remaining data subset until the contribution of the unlearning data to the model is completely eliminated. In this paper, experiments on five datasets prove the effectiveness of our method for machine unlearning, and our method is 15 times faster than retraining.