 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCER: Dual-Stage Compression and Energy-Based Reconstruction
Feb 03, 2026Multimodal fusion faces two robustness challenges: noisy inputs degrade representation quality, and missing modalities cause prediction failures. We propose DCER, a unified framework addressing both challenges through dual-stage compression and energy-based reconstruction. The compression stage operates at two levels: within-modality frequency transforms (wavelet for audio, DCT for video) remove noise while preserving task-relevant patterns, and cross-modality bottleneck tokens force genuine integration rather than modality-specific shortcuts. For missing modalities, energy-based reconstruction recovers representations via gradient descent on a learned energy function, with the final energy providing intrinsic uncertainty quantification (\r{ho} > 0.72 correlation with prediction error). Experiments on CMU-MOSI, CMU-MOSEI, and CH-SIMS demonstrate state-of-the-art performance across all benchmarks, with a U-shaped robustness pattern favoring multimodal fusion at both complete and high-missing conditions. The code will be available on Github.
FORESTLLM: Large Language Models Make Random Forest Great on Few-shot Tabular Learning
Jan 16, 2026Tabular data high-stakes critical decision-making in domains such as finance, healthcare, and scientific discovery. Yet, learning effectively from tabular data in few-shot settings, where labeled examples are scarce, remains a fundamental challenge. Traditional tree-based methods often falter in these regimes due to their reliance on statistical purity metrics, which become unstable and prone to overfitting with limited supervision. At the same time, direct applications of large language models (LLMs) often overlook its inherent structure, leading to suboptimal performance. To overcome these limitations, we propose FORESTLLM, a novel framework that unifies the structural inductive biases of decision forests with the semantic reasoning capabilities of LLMs. Crucially, FORESTLLM leverages the LLM only during training, treating it as an offline model designer that encodes rich, contextual knowledge into a lightweight, interpretable forest model, eliminating the need for LLM inference at test time. Our method is two-fold. First, we introduce a semantic splitting criterion in which the LLM evaluates candidate partitions based on their coherence over both labeled and unlabeled data, enabling the induction of more robust and generalizable tree structures under few-shot supervision. Second, we propose a one-time in-context inference mechanism for leaf node stabilization, where the LLM distills the decision path and its supporting examples into a concise, deterministic prediction, replacing noisy empirical estimates with semantically informed outputs. Across a diverse suite of few-shot classification and regression benchmarks, FORESTLLM achieves state-of-the-art performance.
LitVISTA: A Benchmark for Narrative Orchestration in Literary Text
Jan 10, 2026Computational narrative analysis aims to capture rhythm, tension, and emotional dynamics in literary texts. Existing large language models can generate long stories but overly focus on causal coherence, neglecting the complex story arcs and orchestration inherent in human narratives. This creates a structural misalignment between model- and human-generated narratives. We propose VISTA Space, a high-dimensional representational framework for narrative orchestration that unifies human and model narrative perspectives. We further introduce LitVISTA, a structurally annotated benchmark grounded in literary texts, enabling systematic evaluation of models' narrative orchestration capabilities. We conduct oracle evaluations on a diverse selection of frontier LLMs, including GPT, Claude, Grok, and Gemini. Results reveal systematic deficiencies: existing models fail to construct a unified global narrative view, struggling to jointly capture narrative function and structure. Furthermore, even advanced thinking modes yield only limited gains for such literary narrative understanding.
Beyond Tokens: Enhancing RTL Quality Estimation via Structural Graph Learning
Aug 26, 2025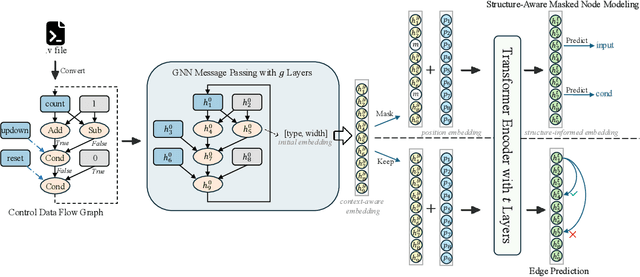
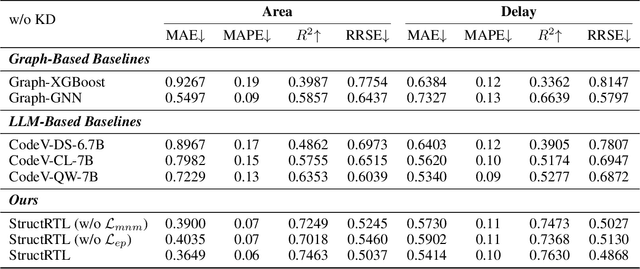
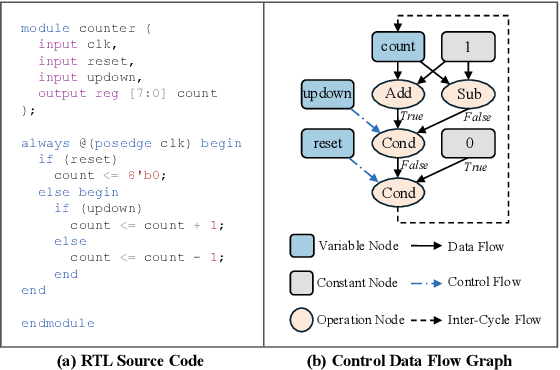
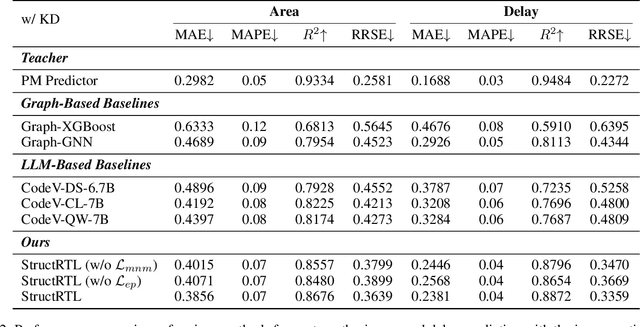
Estimating the quality of register transfer level (RTL) designs is crucial in the electronic design automation (EDA) workflow, as it enables instant feedback on key metrics like area and delay without the need for time-consuming logic synthesis. While recent approaches have leveraged large language models (LLMs) to derive embeddings from RTL code and achieved promising results, they overlook the structural semantics essential for accurate quality estimation. In contrast, the control data flow graph (CDFG) view exposes the design's structural characteristics more explicitly, offering richer cues for representation learning. In this work, we introduce a novel structure-aware graph self-supervised learning framework, StructRTL, for improved RTL design quality estimation. By learning structure-informed representations from CDFGs, our method significantly outperforms prior art on various quality estimation tasks. To further boost performance, we incorporate a knowledge distillation strategy that transfers low-level insights from post-mapping netlists into the CDFG predictor. Experiments show that our approach establishes new state-of-the-art results, demonstrating the effectiveness of combining structural learning with cross-stage supervision.
Quantifying Fairness in LLMs Beyond Tokens: A Semantic and Statistical Perspective
Jun 23, 2025Large Language Models (LLMs) often generate responses with inherent biases, undermining their reliability in real-world applications. Existing evaluation methods often overlook biases in long-form responses and the intrinsic variability of LLM outputs. To address these challenges, we propose FiSCo(Fine-grained Semantic Computation), a novel statistical framework to evaluate group-level fairness in LLMs by detecting subtle semantic differences in long-form responses across demographic groups. Unlike prior work focusing on sentiment or token-level comparisons, FiSCo goes beyond surface-level analysis by operating at the claim level, leveraging entailment checks to assess the consistency of meaning across responses. We decompose model outputs into semantically distinct claims and apply statistical hypothesis testing to compare inter- and intra-group similarities, enabling robust detection of subtle biases. We formalize a new group counterfactual fairness definition and validate FiSCo on both synthetic and human-annotated datasets spanning gender, race, and age. Experiments show that FiSco more reliably identifies nuanced biases while reducing the impact of stochastic LLM variability, outperforming various evaluation metrics.
Overview of the NLPCC 2025 Shared Task: Gender Bias Mitigation Challenge
Jun 14, 2025As natural language processing for gender bias becomes a significant interdisciplinary topic, the prevalent data-driven techniques, such as pre-trained language models, suffer from biased corpus. This case becomes more obvious regarding those languages with less fairness-related computational linguistic resources, such as Chinese. To this end, we propose a Chinese cOrpus foR Gender bIas Probing and Mitigation (CORGI-PM), which contains 32.9k sentences with high-quality labels derived by following an annotation scheme specifically developed for gender bias in the Chinese context. It is worth noting that CORGI-PM contains 5.2k gender-biased sentences along with the corresponding bias-eliminated versions rewritten by human annotators. We pose three challenges as a shared task to automate the mitigation of textual gender bias, which requires the models to detect, classify, and mitigate textual gender bias. In the literature, we present the results and analysis for the teams participating this shared task in NLPCC 2025.
Harnessing On-Device Large Language Model: Empirical Results and Implications for AI PC
May 22, 2025The increasing deployment of Large Language Models (LLMs) on edge devices, driven by model advancements and hardware improvements, offers significant privacy benefits. However, these on-device LLMs inherently face performance limitations due to reduced model capacity and necessary compression techniques. To address this, we introduce a systematic methodology -- encompassing model capability, development efficiency, and system resources -- for evaluating on-device LLMs. Our comprehensive evaluation, encompassing models from 0.5B to 14B parameters and seven post-training quantization (PTQ) methods on commodity laptops, yields several critical insights: 1) System-level metrics exhibit near-linear scaling with effective bits-per-weight (BPW). 2) A practical threshold exists around $\sim$3.5 effective BPW, larger models subjected to low-bit quantization consistently outperform smaller models utilizing higher bit-precision. 3) Quantization with low BPW incurs marginal accuracy loss but significant memory savings. 4) Determined by low-level implementation specifics power consumption on CPU, where computation-intensive operations spend more power than memory-intensive ones. These findings offer crucial insights and practical guidelines for the efficient deployment and optimized configuration of LLMs on resource-constrained edge devices. Our codebase is available at https://github.com/simmonssong/LLMOnDevice.
Harnessing Large Language Models Locally: Empirical Results and Implications for AI PC
May 21, 2025The increasing deployment of Large Language Models (LLMs) on edge devices, driven by model advancements and hardware improvements, offers significant privacy benefits. However, these on-device LLMs inherently face performance limitations due to reduced model capacity and necessary compression techniques. To address this, we introduce a systematic methodology -- encompassing model capability, development efficiency, and system resources -- for evaluating on-device LLMs. Our comprehensive evaluation, encompassing models from 0.5B to 14B parameters and seven post-training quantization (PTQ) methods on commodity laptops, yields several critical insights: 1) System-level metrics exhibit near-linear scaling with effective bits-per-weight (BPW). 2) A practical threshold exists around $\sim$3.5 effective BPW, larger models subjected to low-bit quantization consistently outperform smaller models utilizing higher bit-precision. 3) Quantization with low BPW incurs marginal accuracy loss but significant memory savings. 4) Determined by low-level implementation specifics power consumption on CPU, where computation-intensive operations spend more power than memory-intensive ones. These findings offer crucial insights and practical guidelines for the efficient deployment and optimized configuration of LLMs on resource-constrained edge devices. Our codebase is available at https://github.com/simmonssong/LLMOnDevice.
Enhanced Semantic Extraction and Guidance for UGC Image Super Resolution
Apr 14, 2025Due to the disparity between real-world degradations in user-generated content(UGC) images and synthetic degradations, traditional super-resolution methods struggle to generalize effectively, necessitating a more robust approach to model real-world distortions. In this paper, we propose a novel approach to UGC image super-resolution by integrating semantic guidance into a diffusion framework. Our method addresses the inconsistency between degradations in wild and synthetic datasets by separately simulating the degradation processes on the LSDIR dataset and combining them with the official paired training set. Furthermore, we enhance degradation removal and detail generation by incorporating a pretrained semantic extraction model (SAM2) and fine-tuning key hyperparameters for improved perceptual fidelity. Extensive experiments demonstrate the superiority of our approach against state-of-the-art methods. Additionally, the proposed model won second place in the CVPR NTIRE 2025 Short-form UGC Image Super-Resolution Challenge, further validating its effectiveness. The code is available at https://github.c10pom/Moonsofang/NTIRE-2025-SRlab.
SG-Splatting: Accelerating 3D Gaussian Splatting with Spherical Gaussians
Dec 31, 2024



3D Gaussian Splatting is emerging as a state-of-the-art technique in novel view synthesis, recognized for its impressive balance between visual quality, speed, and rendering efficiency. However, reliance on third-degree spherical harmonics for color representation introduces significant storage demands and computational overhead, resulting in a large memory footprint and slower rendering speed. We introduce SG-Splatting with Spherical Gaussians based color representation, a novel approach to enhance rendering speed and quality in novel view synthesis. Our method first represents view-dependent color using Spherical Gaussians, instead of three degree spherical harmonics, which largely reduces the number of parameters used for color representation, and significantly accelerates the rendering process. We then develop an efficient strategy for organizing multiple Spherical Gaussians, optimizing their arrangement to achieve a balanced and accurate scene representation. To further improve rendering quality, we propose a mixed representation that combines Spherical Gaussians with low-degree spherical harmonics, capturing both high- and low-frequency color information effectively. SG-Splatting also has plug-and-play capability, allowing it to be easily integrated into existing systems. This approach improves computational efficiency and overall visual fidelity, making it a practical solution for real-time applications.