 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuplexSLA: A Full-Duplex Spoken Language Model with Synchronized Speech, Language, and Action
May 20, 2026Recent advances in spoken dialogue language models have shifted from turn-based to full-duplex designs, where the model continuously listens to the user while generating responses. However, existing duplex backbones still lack a native channel for in-conversation planning and tool calling, leaving real-time agentic behaviour either tied to turn boundaries or relegated to an external cascade. We propose DuplexSLA, a native full-duplex Speech-Language-Action foundation model that decodes assistant audio together with a structured action stream on a shared 160 ms chunk timeline. DuplexSLA is built on a dual-stream three-channel formulation: a continuous user audio channel, a discrete assistant audio channel, and a rate-limited textual action channel, all decoded jointly by a single backbone, so that listening, speaking, planning, and tool calling unfold on one shared clock. Two capabilities define the model: (1) semantic-driven turn-taking control, where interruption, pause, and backchannel are handled inside the same backbone instead of by an external semantic VAD; and (2) in-conversation planning and tool calling, where planning text and structured tool calls are emitted on the action channel without halting assistant audio, so that multi-action and backchannel-triggered tool use are interleaved with ongoing speech. To evaluate these capabilities together, we further construct DuplexSLA-Bench, a duplex benchmark covering pause, interrupt, and backchannel turn-taking together with three styles of in-conversation tool calling. Our project page, interactive demos, and the DuplexSLA-Bench evaluation suite are publicly available at https://github.com/hyzhang24/DuplexSLA.
The Silent Thought: Modeling Internal Cognition in Full-Duplex Spoken Dialogue Models via Latent Reasoning
Mar 18, 2026During conversational interactions, humans subconsciously engage in concurrent thinking while listening to a speaker. Although this internal cognitive processing may not always manifest as explicit linguistic structures, it is instrumental in formulating high-quality responses. Inspired by this cognitive phenomenon, we propose a novel Full-duplex LAtent and Internal Reasoning method named FLAIR that conducts latent thinking simultaneously with speech perception. Unlike conventional "thinking" mechanisms in NLP, which require post-hoc generation, our approach aligns seamlessly with spoken dialogue systems: during the user's speaking phase, it recursively feeds the latent embedding output from the previous step into the next step, enabling continuous reasoning that strictly adheres to causality without introducing additional latency. To enable this latent reasoning, we design an Evidence Lower Bound-based objective that supports efficient supervised finetuning via teacher forcing, circumventing the need for explicit reasoning annotations. Experiments demonstrate the effectiveness of this think-while-listening design, which achieves competitive results on a range of speech benchmarks. Furthermore, FLAIR robustly handles conversational dynamics and attains competitive performance on full-duplex interaction metrics.
Mind-Paced Speaking: A Dual-Brain Approach to Real-Time Reasoning in Spoken Language Models
Oct 10, 2025Real-time Spoken Language Models (SLMs) struggle to leverage Chain-of-Thought (CoT) reasoning due to the prohibitive latency of generating the entire thought process sequentially. Enabling SLMs to think while speaking, similar to humans, is attracting increasing attention. We present, for the first time, Mind-Paced Speaking (MPS), a brain-inspired framework that enables high-fidelity, real-time reasoning. Similar to how humans utilize distinct brain regions for thinking and responding, we propose a novel dual-brain approach, employing a "Formulation Brain" for high-level reasoning to pace and guide a separate "Articulation Brain" for fluent speech generation. This division of labor eliminates mode-switching, preserving the integrity of the reasoning process. Experiments show that MPS significantly outperforms existing think-while-speaking methods and achieves reasoning performance comparable to models that pre-compute the full CoT before speaking, while drastically reducing latency. Under a zero-latency configuration, the proposed method achieves an accuracy of 92.8% on the mathematical reasoning task Spoken-MQA and attains a score of 82.5 on the speech conversation task URO-Bench. Our work effectively bridges the gap between high-quality reasoning and real-time interaction.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Cross-attention Inspired Selective State Space Models for Target Sound Extraction
Sep 10, 2024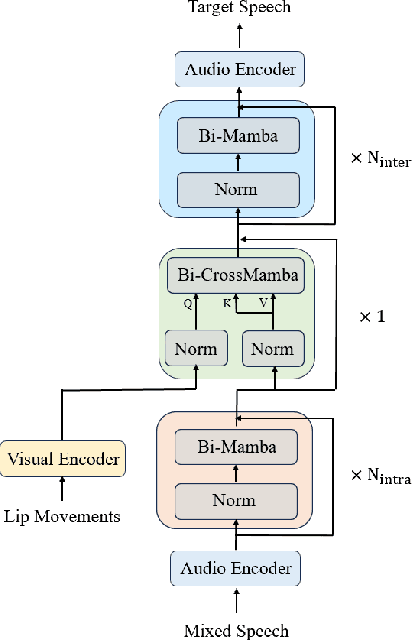
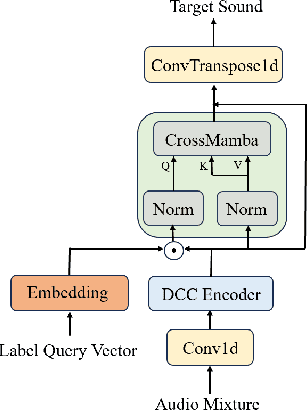
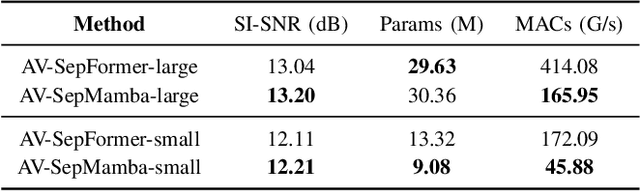
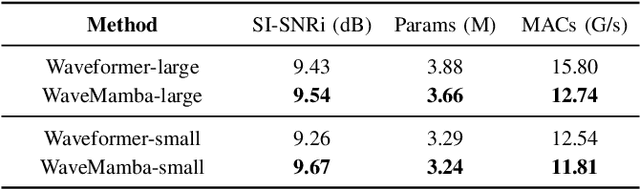
The Transformer model, particularly its cross-attention module, is widely used for feature fusion in target sound extraction which extracts the signal of interest based on given clues. Despite its effectiveness, this approach suffers from low computational efficiency. Recent advancements in state space models, notably the latest work Mamba, have shown comparable performance to Transformer-based methods while significantly reducing computational complexity in various tasks. However, Mamba's applicability in target sound extraction is limited due to its inability to capture dependencies between different sequences as the cross-attention does. In this paper, we propose CrossMamba for target sound extraction, which leverages the hidden attention mechanism of Mamba to compute dependencies between the given clues and the audio mixture. The calculation of Mamba can be divided to the query, key and value. We utilize the clue to generate the query and the audio mixture to derive the key and value, adhering to the principle of the cross-attention mechanism in Transformers. Experimental results from two representative target sound extraction methods validate the efficacy of the proposed CrossMamba.
Leveraging Moving Sound Source Trajectories for Universal Sound Separation
Sep 07, 2024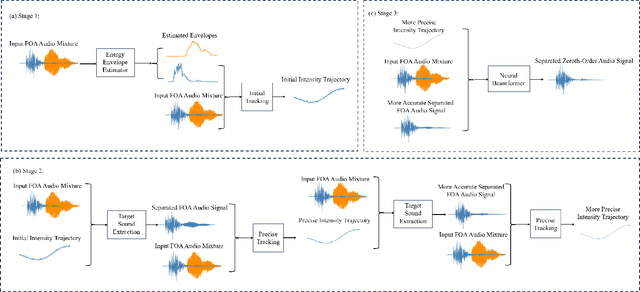
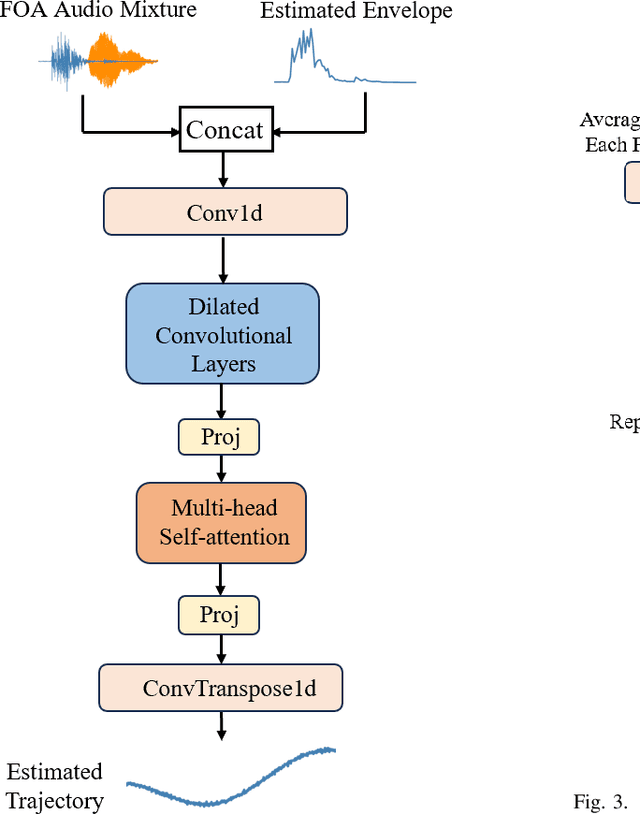
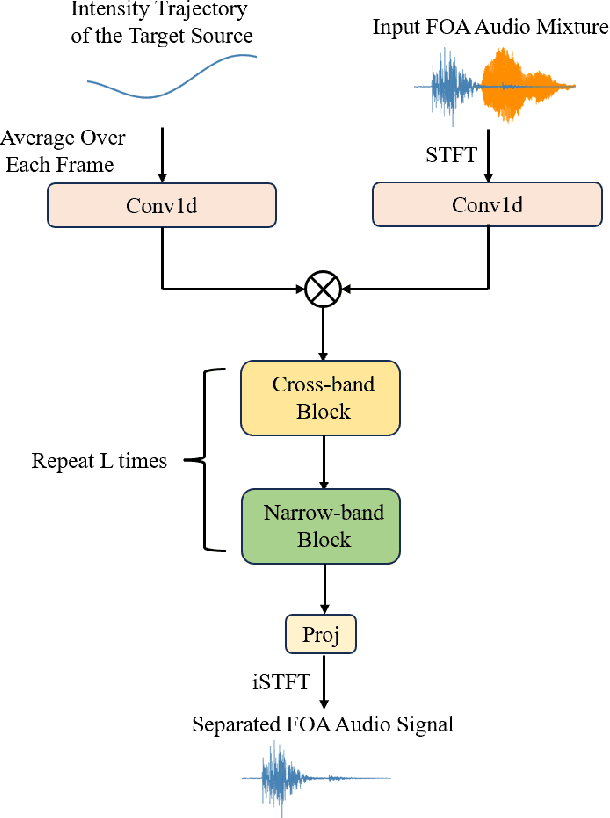
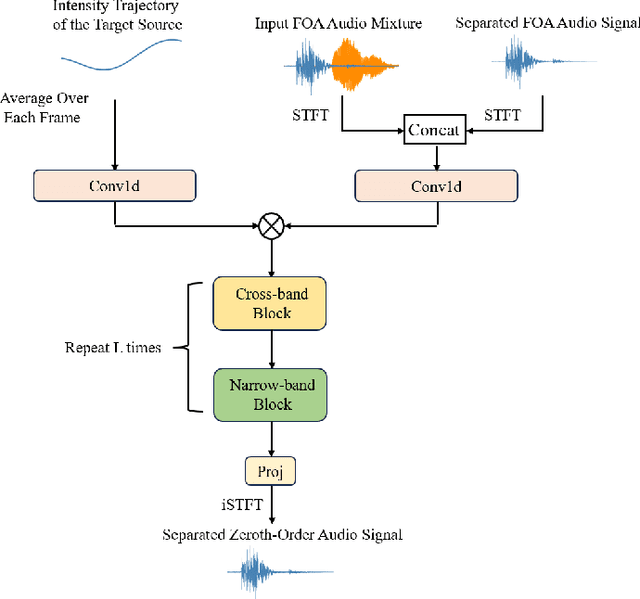
Existing methods utilizing spatial information for sound source separation require prior knowledge of the direction of arrival (DOA) of the source or utilize estimated but imprecise localization results, which impairs the separation performance, especially when the sound sources are moving. In fact, sound source localization and separation are interconnected problems, that is, sound source localization facilitates sound separation while sound separation contributes to more precise source localization. This paper proposes a method utilizing the mutual facilitation mechanism between sound source localization and separation for moving sources. Initially, sound separation is conducted using rough preliminary sound source tracking results. Sound source tracking is then performed on the separated signals thus the tracking results can become more precise. The precise trajectory can further enhances the separation performance. This mutual facilitation process can be performed over several iterations. Simulation experiments conducted under reverberation conditions and with moving sound sources demonstrate that the proposed method can achieve more accurate separation based on more precise tracking results.