 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-attention Inspired Selective State Space Models for Target Sound Extraction
Paper and Code
Sep 10, 2024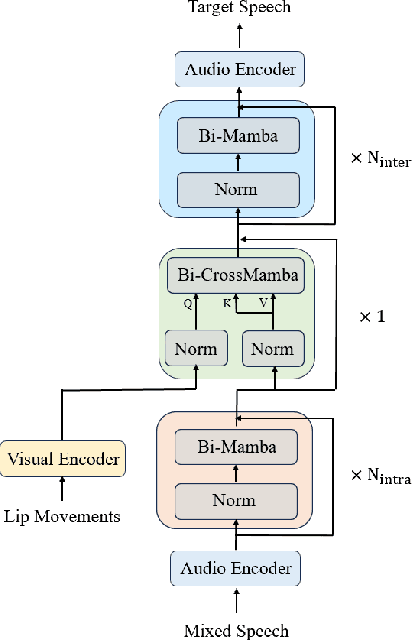
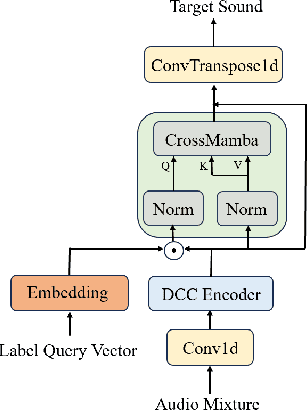
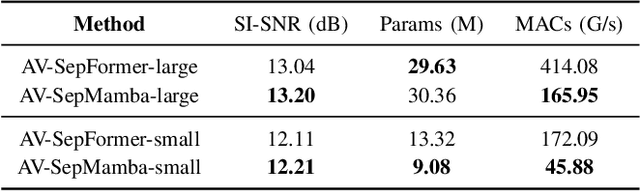
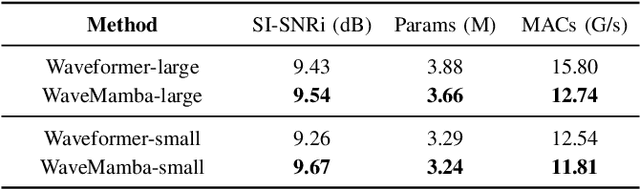
The Transformer model, particularly its cross-attention module, is widely used for feature fusion in target sound extraction which extracts the signal of interest based on given clues. Despite its effectiveness, this approach suffers from low computational efficiency. Recent advancements in state space models, notably the latest work Mamba, have shown comparable performance to Transformer-based methods while significantly reducing computational complexity in various tasks. However, Mamba's applicability in target sound extraction is limited due to its inability to capture dependencies between different sequences as the cross-attention does. In this paper, we propose CrossMamba for target sound extraction, which leverages the hidden attention mechanism of Mamba to compute dependencies between the given clues and the audio mixture. The calculation of Mamba can be divided to the query, key and value. We utilize the clue to generate the query and the audio mixture to derive the key and value, adhering to the principle of the cross-attention mechanism in Transformers. Experimental results from two representative target sound extraction methods validate the efficacy of the proposed CrossMamba.