 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe World is Not Mono: Enabling Spatial Understanding in Large Audio-Language Models
Jan 06, 2026Existing large audio-language models perceive the world as "mono" -- a single stream of audio that ignores the critical spatial dimension ("where") required for universal acoustic scene analysis. To bridge this gap, we first introduce a hierarchical framework for Auditory Scene Analysis (ASA). Guided by this framework, we introduce a system that enables models like Qwen2-Audio to understand and reason about the complex acoustic world. Our framework achieves this through three core contributions: First, we build a large-scale, synthesized binaural audio dataset to provide the rich spatial cues. Second, we design a hybrid feature projector, which leverages parallel semantic and spatial encoders to extract decoupled representations. These distinct streams are integrated via a dense fusion mechanism, ensuring the model receives a holistic view of the acoustic scene. Finally, we employ a progressive training curriculum, advancing from supervised fine-tuning (SFT) to reinforcement learning via Group Relative Policy Optimization (GRPO), to explicitly evolve the model's capabilities towards reasoning. On our comprehensive benchmark, the model demonstrates comparatively strong capability for spatial understanding. By enabling this spatial perception, our work provides a clear pathway for leveraging the powerful reasoning abilities of large models towards holistic acoustic scene analysis, advancing from "mono" semantic recognition to spatial intelligence.
Automotive sound field reproduction using deep optimization with spatial domain constraint
Sep 11, 2025Sound field reproduction with undistorted sound quality and precise spatial localization is desirable for automotive audio systems. However, the complexity of automotive cabin acoustic environment often necessitates a trade-off between sound quality and spatial accuracy. To overcome this limitation, we propose Spatial Power Map Net (SPMnet), a learning-based sound field reproduction method that improves both sound quality and spatial localization in complex environments. We introduce a spatial power map (SPM) constraint, which characterizes the angular energy distribution of the reproduced field using beamforming. This constraint guides energy toward the intended direction to enhance spatial localization, and is integrated into a multi-channel equalization framework to also improve sound quality under reverberant conditions. To address the resulting non-convexity, deep optimization that use neural networks to solve optimization problems is employed for filter design. Both in situ objective and subjective evaluations confirm that our method enhances sound quality and improves spatial localization within the automotive cabin. Furthermore, we analyze the influence of different audio materials and the arrival angles of the virtual sound source in the reproduced sound field, investigating the potential underlying factors affecting these results.
Cross-attention Inspired Selective State Space Models for Target Sound Extraction
Sep 10, 2024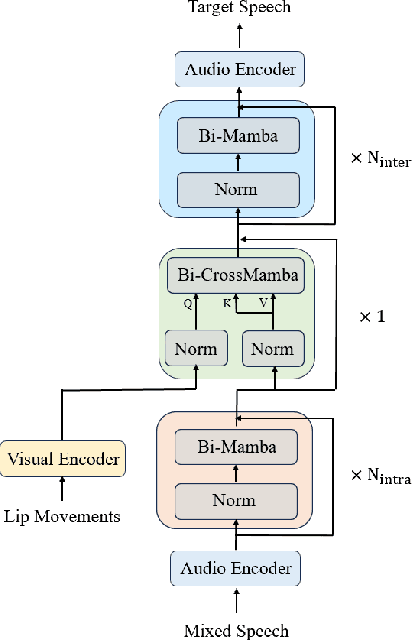
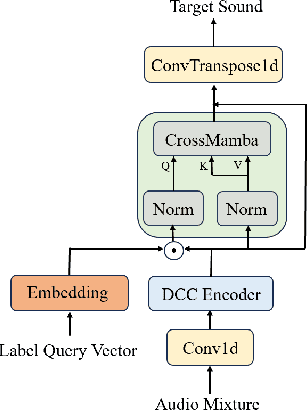
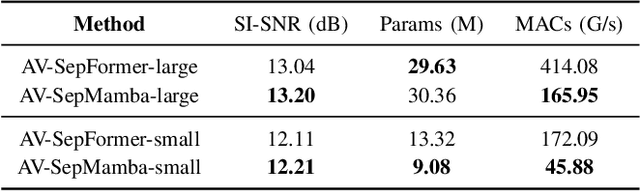
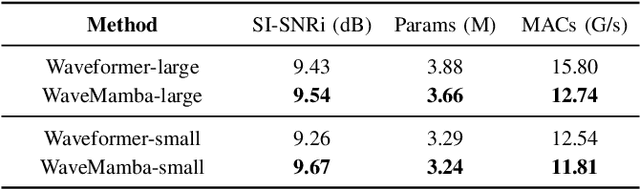
The Transformer model, particularly its cross-attention module, is widely used for feature fusion in target sound extraction which extracts the signal of interest based on given clues. Despite its effectiveness, this approach suffers from low computational efficiency. Recent advancements in state space models, notably the latest work Mamba, have shown comparable performance to Transformer-based methods while significantly reducing computational complexity in various tasks. However, Mamba's applicability in target sound extraction is limited due to its inability to capture dependencies between different sequences as the cross-attention does. In this paper, we propose CrossMamba for target sound extraction, which leverages the hidden attention mechanism of Mamba to compute dependencies between the given clues and the audio mixture. The calculation of Mamba can be divided to the query, key and value. We utilize the clue to generate the query and the audio mixture to derive the key and value, adhering to the principle of the cross-attention mechanism in Transformers. Experimental results from two representative target sound extraction methods validate the efficacy of the proposed CrossMamba.
Leveraging Moving Sound Source Trajectories for Universal Sound Separation
Sep 07, 2024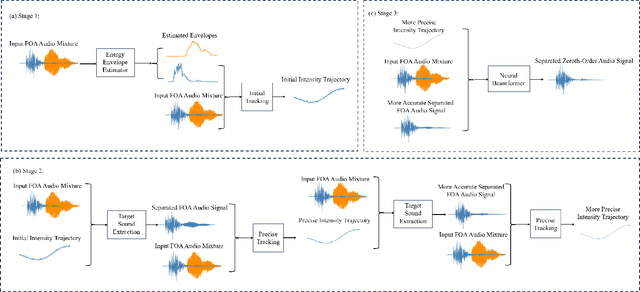
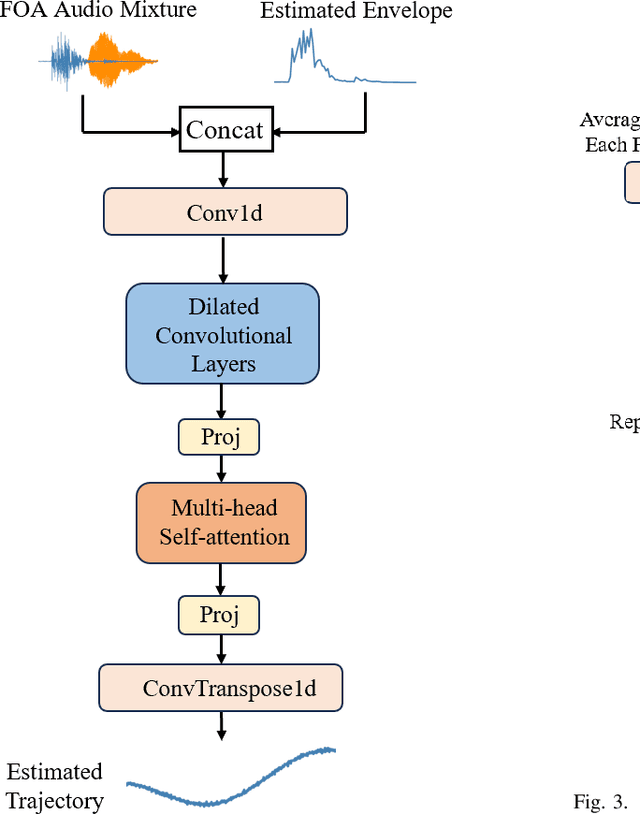
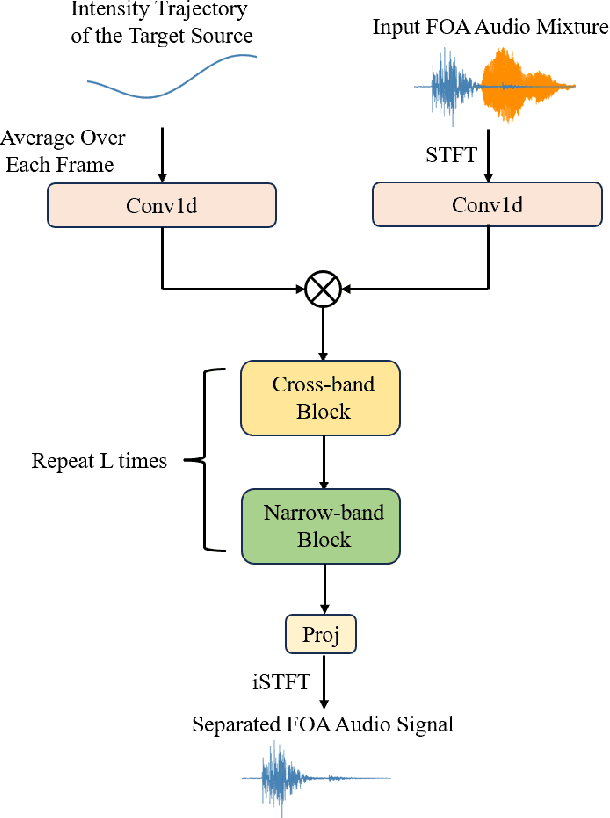
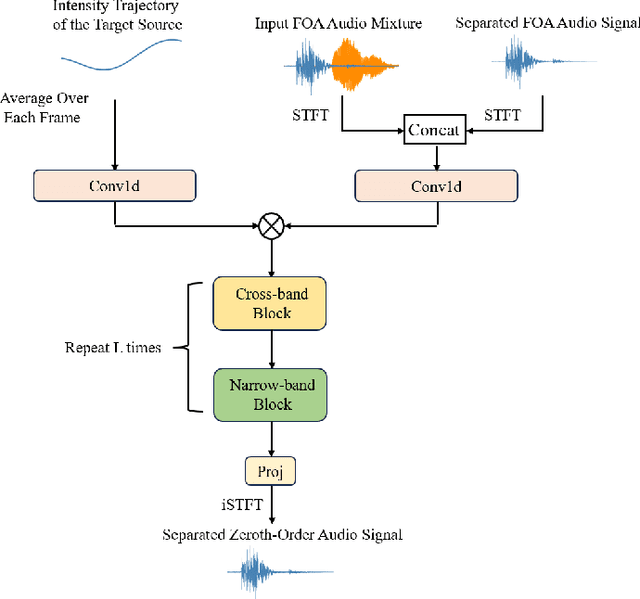
Existing methods utilizing spatial information for sound source separation require prior knowledge of the direction of arrival (DOA) of the source or utilize estimated but imprecise localization results, which impairs the separation performance, especially when the sound sources are moving. In fact, sound source localization and separation are interconnected problems, that is, sound source localization facilitates sound separation while sound separation contributes to more precise source localization. This paper proposes a method utilizing the mutual facilitation mechanism between sound source localization and separation for moving sources. Initially, sound separation is conducted using rough preliminary sound source tracking results. Sound source tracking is then performed on the separated signals thus the tracking results can become more precise. The precise trajectory can further enhances the separation performance. This mutual facilitation process can be performed over several iterations. Simulation experiments conducted under reverberation conditions and with moving sound sources demonstrate that the proposed method can achieve more accurate separation based on more precise tracking results.
TT-Net: Dual-path transformer based sound field translation in the spherical harmonic domain
Oct 30, 2022In the current method for the sound field translation tasks based on spherical harmonic (SH) analysis, the solution based on the additive theorem usually faces the problem of singular values caused by large matrix condition numbers. The influence of different distances and frequencies of the spherical radial function on the stability of the translation matrix will affect the accuracy of the SH coefficients at the selected point. Due to the problems mentioned above, we propose a neural network scheme based on the dual-path transformer. More specifically, the dual-path network is constructed by the self-attention module along the two dimensions of the frequency and order axes. The transform-average-concatenate layer and upscaling layer are introduced in the network, which provides solutions for multiple sampling points and upscaling. Numerical simulation results indicate that both the working frequency range and the distance range of the translation are extended. More accurate higher-order SH coefficients are obtained with the proposed dual-path network.
Room geometry blind inference based on the localization of real sound source and first order reflections
Jul 22, 2022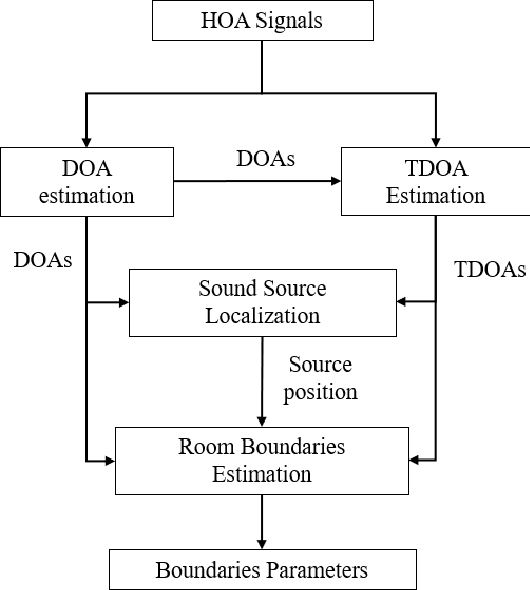
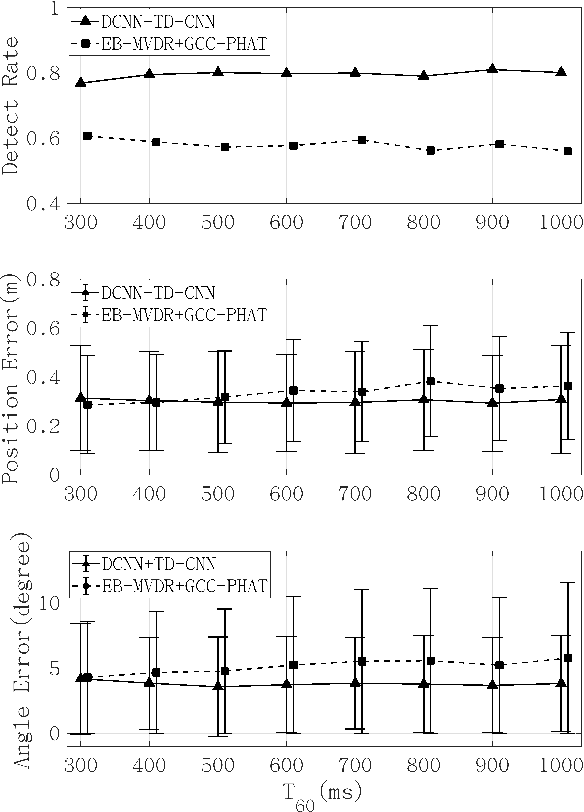

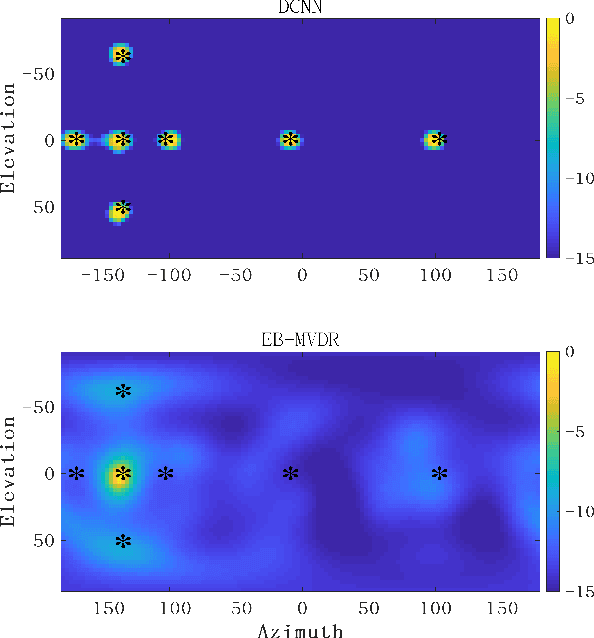
The conventional room geometry blind inference techniques with acoustic signals are conducted based on the prior knowledge of the environment, such as the room impulse response (RIR) or the sound source position, which will limit its application under unknown scenarios. To solve this problem, we have proposed a room geometry reconstruction method in this paper by using the geometric relation between the direct signal and first-order reflections. In addition to the information of the compact microphone array itself, this method does not need any precognition of the environmental parameters. Besides, the learning-based DNN models are designed and used to improve the accuracy and integrity of the localization results of the direct source and first-order reflections. The direction of arrival (DOA) and time difference of arrival (TDOA) information of the direct and reflected signals are firstly estimated using the proposed DCNN and TD-CNN models, which have higher sensitivity and accuracy than the conventional methods. Then the position of the sound source is inferred by integrating the DOA, TDOA and array height using the proposed DNN model. After that, the positions of image sources and corresponding boundaries are derived based on the geometric relation. Experimental results of both simulations and real measurements verify the effectiveness and accuracy of the proposed techniques compared with the conventional methods under different reverberant environments.
Direct source and early reflections localization using deep deconvolution network under reverberant environment
Oct 22, 2021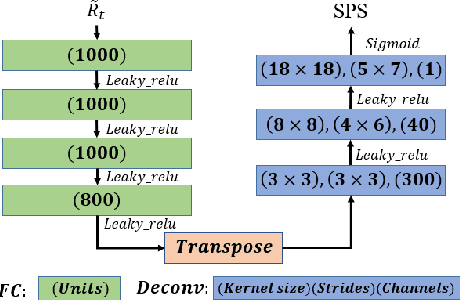


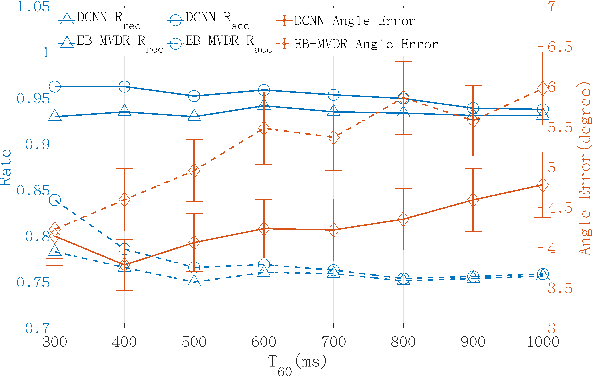
This paper proposes a deconvolution-based network (DCNN) model for DOA estimation of direct source and early reflections under reverberant scenarios. Considering that the first-order reflections of the sound source also contain spatial directivity like the direct source, we treat both of them as the sources in the learning process. We use the covariance matrix of high order Ambisonics (HOA) signals in the time domain as the input feature of the network, which is concise while containing precise spatial information under reverberant scenarios. Besides, we use the deconvolution-based network for the spatial pseudo-spectrum (SPS) reconstruction in the 2D polar space, based on which the spatial relationship between elevation and azimuth can be depicted. We have carried out a series of experiments based on simulated and measured data under different reverberant scenarios, which prove the robustness and accuracy of the proposed DCNN model.