 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHINE: Sequential Hierarchical Integration Network for EEG and MEG
Feb 27, 2026How natural speech is represented in the brain constitutes a major challenge for cognitive neuroscience, with cortical envelope-following responses playing a central role in speech decoding. This paper presents our approach to the Speech Detection task in the LibriBrain Competition 2025, utilizing over 50 hours of magnetoencephalography (MEG) signals from a single participant listening to LibriVox audiobooks. We introduce the proposed Sequential Hierarchical Integration Network for EEG and MEG (SHINE) to reconstruct the binary speech-silence sequences from MEG signals. In the Extended Track, we further incorporated auxiliary reconstructions of speech envelopes and Mel spectrograms to enhance training. Ensemble methods combining SHINE with baselines (BrainMagic, AWavNet, ConvConcatNet) achieved F1-macro scores of 0.9155 (Standard Track) and 0.9184 (Extended Track) on the leaderboard test set.
The World is Not Mono: Enabling Spatial Understanding in Large Audio-Language Models
Jan 06, 2026Existing large audio-language models perceive the world as "mono" -- a single stream of audio that ignores the critical spatial dimension ("where") required for universal acoustic scene analysis. To bridge this gap, we first introduce a hierarchical framework for Auditory Scene Analysis (ASA). Guided by this framework, we introduce a system that enables models like Qwen2-Audio to understand and reason about the complex acoustic world. Our framework achieves this through three core contributions: First, we build a large-scale, synthesized binaural audio dataset to provide the rich spatial cues. Second, we design a hybrid feature projector, which leverages parallel semantic and spatial encoders to extract decoupled representations. These distinct streams are integrated via a dense fusion mechanism, ensuring the model receives a holistic view of the acoustic scene. Finally, we employ a progressive training curriculum, advancing from supervised fine-tuning (SFT) to reinforcement learning via Group Relative Policy Optimization (GRPO), to explicitly evolve the model's capabilities towards reasoning. On our comprehensive benchmark, the model demonstrates comparatively strong capability for spatial understanding. By enabling this spatial perception, our work provides a clear pathway for leveraging the powerful reasoning abilities of large models towards holistic acoustic scene analysis, advancing from "mono" semantic recognition to spatial intelligence.
Automotive sound field reproduction using deep optimization with spatial domain constraint
Sep 11, 2025Sound field reproduction with undistorted sound quality and precise spatial localization is desirable for automotive audio systems. However, the complexity of automotive cabin acoustic environment often necessitates a trade-off between sound quality and spatial accuracy. To overcome this limitation, we propose Spatial Power Map Net (SPMnet), a learning-based sound field reproduction method that improves both sound quality and spatial localization in complex environments. We introduce a spatial power map (SPM) constraint, which characterizes the angular energy distribution of the reproduced field using beamforming. This constraint guides energy toward the intended direction to enhance spatial localization, and is integrated into a multi-channel equalization framework to also improve sound quality under reverberant conditions. To address the resulting non-convexity, deep optimization that use neural networks to solve optimization problems is employed for filter design. Both in situ objective and subjective evaluations confirm that our method enhances sound quality and improves spatial localization within the automotive cabin. Furthermore, we analyze the influence of different audio materials and the arrival angles of the virtual sound source in the reproduced sound field, investigating the potential underlying factors affecting these results.
DPGP: A Hybrid 2D-3D Dual Path Potential Ghost Probe Zone Prediction Framework for Safe Autonomous Driving
Apr 23, 2025



Modern robots must coexist with humans in dense urban environments. A key challenge is the ghost probe problem, where pedestrians or objects unexpectedly rush into traffic paths. This issue affects both autonomous vehicles and human drivers. Existing works propose vehicle-to-everything (V2X) strategies and non-line-of-sight (NLOS) imaging for ghost probe zone detection. However, most require high computational power or specialized hardware, limiting real-world feasibility. Additionally, many methods do not explicitly address this issue. To tackle this, we propose DPGP, a hybrid 2D-3D fusion framework for ghost probe zone prediction using only a monocular camera during training and inference. With unsupervised depth prediction, we observe ghost probe zones align with depth discontinuities, but different depth representations offer varying robustness. To exploit this, we fuse multiple feature embeddings to improve prediction. To validate our approach, we created a 12K-image dataset annotated with ghost probe zones, carefully sourced and cross-checked for accuracy. Experimental results show our framework outperforms existing methods while remaining cost-effective. To our knowledge, this is the first work extending ghost probe zone prediction beyond vehicles, addressing diverse non-vehicle objects. We will open-source our code and dataset for community benefit.
Using Ear-EEG to Decode Auditory Attention in Multiple-speaker Environment
Sep 13, 2024



Auditory Attention Decoding (AAD) can help to determine the identity of the attended speaker during an auditory selective attention task, by analyzing and processing measurements of electroencephalography (EEG) data. Most studies on AAD are based on scalp-EEG signals in two-speaker scenarios, which are far from real application. Ear-EEG has recently gained significant attention due to its motion tolerance and invisibility during data acquisition, making it easy to incorporate with other devices for applications. In this work, participants selectively attended to one of the four spatially separated speakers' speech in an anechoic room. The EEG data were concurrently collected from a scalp-EEG system and an ear-EEG system (cEEGrids). Temporal response functions (TRFs) and stimulus reconstruction (SR) were utilized using ear-EEG data. Results showed that the attended speech TRFs were stronger than each unattended speech and decoding accuracy was 41.3\% in the 60s (chance level of 25\%). To further investigate the impact of electrode placement and quantity, SR was utilized in both scalp-EEG and ear-EEG, revealing that while the number of electrodes had a minor effect, their positioning had a significant influence on the decoding accuracy. One kind of auditory spatial attention detection (ASAD) method, STAnet, was testified with this ear-EEG database, resulting in 93.1% in 1-second decoding window. The implementation code and database for our work are available on GitHub: https://github.com/zhl486/Ear_EEG_code.git and Zenodo: https://zenodo.org/records/10803261.
DENSE: Dynamic Embedding Causal Target Speech Extraction
Sep 10, 2024



Target speech extraction (TSE) focuses on extracting the speech of a specific target speaker from a mixture of signals. Existing TSE models typically utilize static embeddings as conditions for extracting the target speaker's voice. However, the static embeddings often fail to capture the contextual information of the extracted speech signal, which may limit the model's performance. We propose a novel dynamic embedding causal target speech extraction model to address this limitation. Our approach incorporates an autoregressive mechanism to generate context-dependent embeddings based on the extracted speech, enabling real-time, frame-level extraction. Experimental results demonstrate that the proposed model enhances short-time objective intelligibility (STOI) and signal-to-distortion ratio (SDR), offering a promising solution for target speech extraction in challenging scenarios.
Cross-attention Inspired Selective State Space Models for Target Sound Extraction
Sep 10, 2024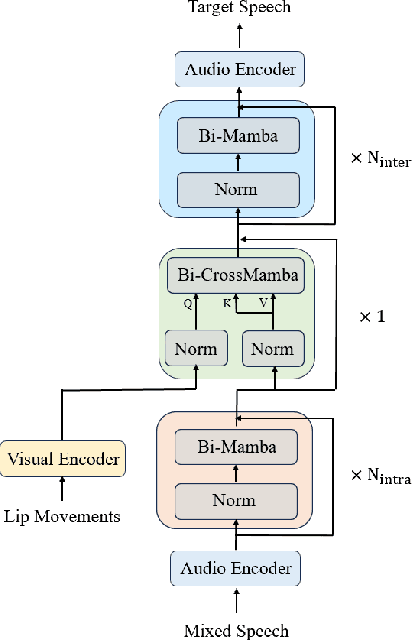
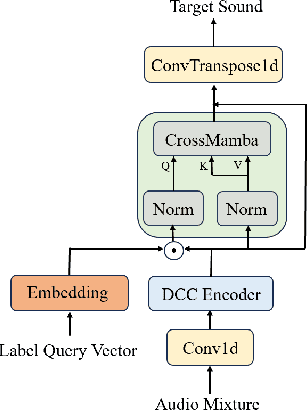
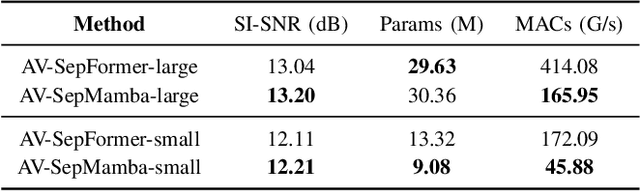
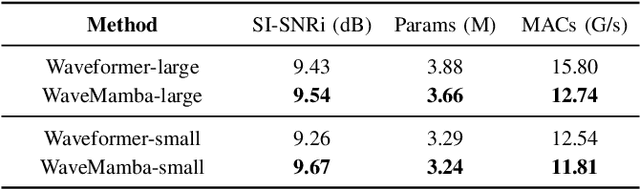
The Transformer model, particularly its cross-attention module, is widely used for feature fusion in target sound extraction which extracts the signal of interest based on given clues. Despite its effectiveness, this approach suffers from low computational efficiency. Recent advancements in state space models, notably the latest work Mamba, have shown comparable performance to Transformer-based methods while significantly reducing computational complexity in various tasks. However, Mamba's applicability in target sound extraction is limited due to its inability to capture dependencies between different sequences as the cross-attention does. In this paper, we propose CrossMamba for target sound extraction, which leverages the hidden attention mechanism of Mamba to compute dependencies between the given clues and the audio mixture. The calculation of Mamba can be divided to the query, key and value. We utilize the clue to generate the query and the audio mixture to derive the key and value, adhering to the principle of the cross-attention mechanism in Transformers. Experimental results from two representative target sound extraction methods validate the efficacy of the proposed CrossMamba.
Leveraging Moving Sound Source Trajectories for Universal Sound Separation
Sep 07, 2024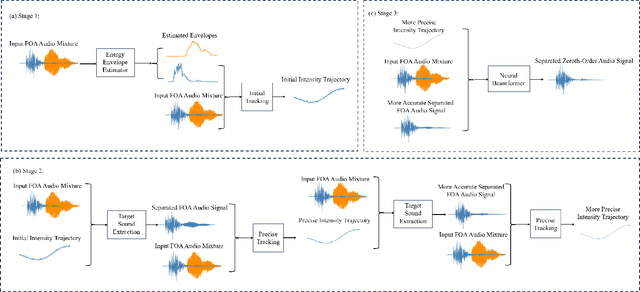
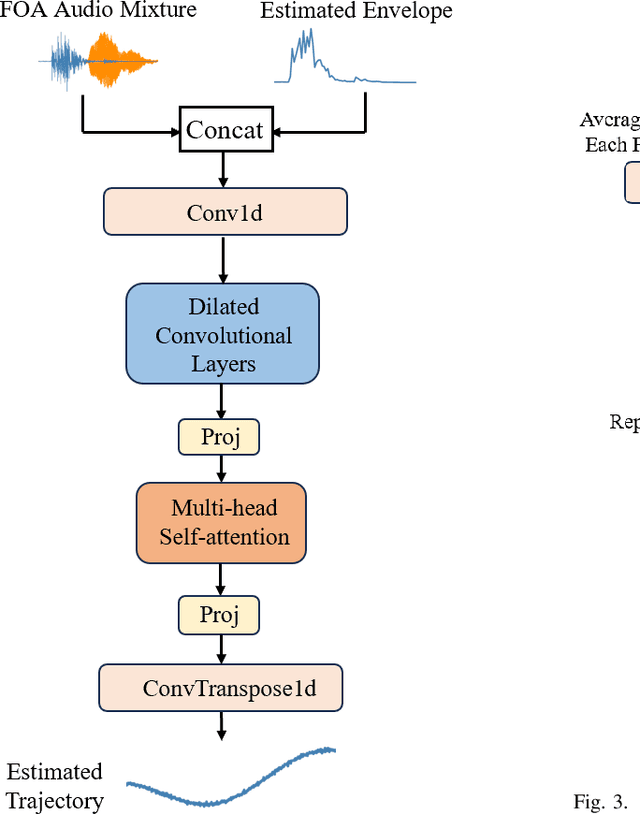
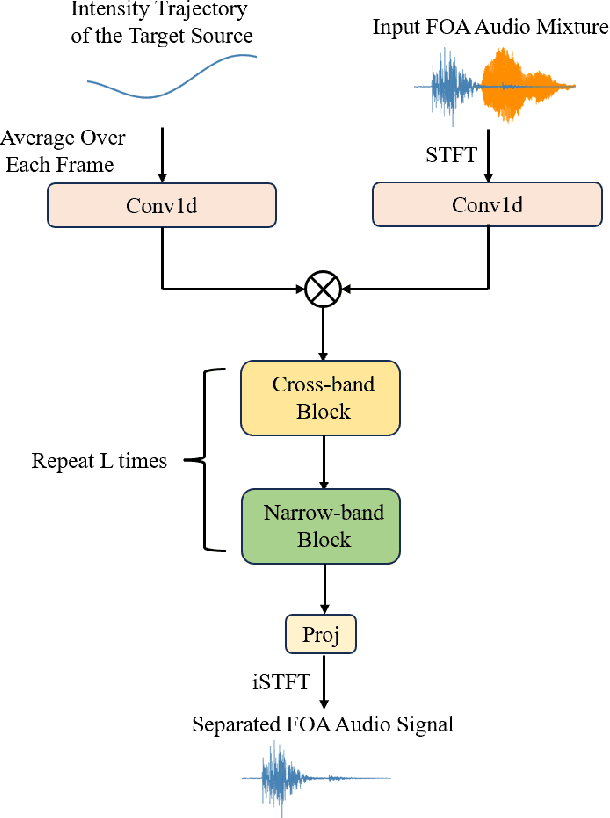
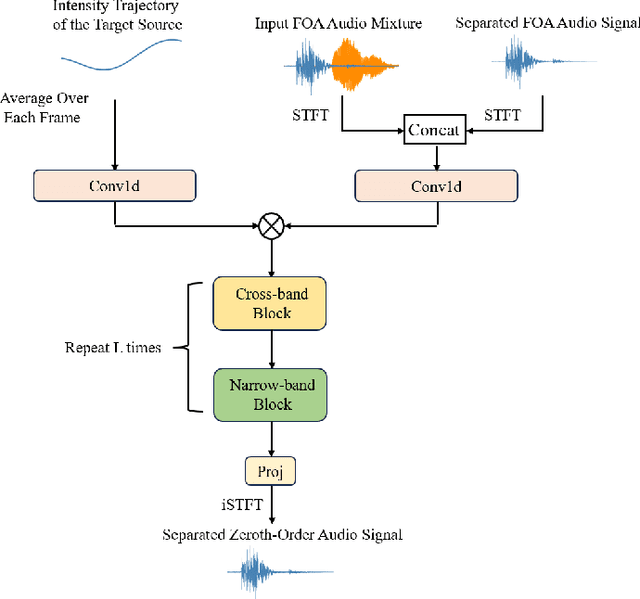
Existing methods utilizing spatial information for sound source separation require prior knowledge of the direction of arrival (DOA) of the source or utilize estimated but imprecise localization results, which impairs the separation performance, especially when the sound sources are moving. In fact, sound source localization and separation are interconnected problems, that is, sound source localization facilitates sound separation while sound separation contributes to more precise source localization. This paper proposes a method utilizing the mutual facilitation mechanism between sound source localization and separation for moving sources. Initially, sound separation is conducted using rough preliminary sound source tracking results. Sound source tracking is then performed on the separated signals thus the tracking results can become more precise. The precise trajectory can further enhances the separation performance. This mutual facilitation process can be performed over several iterations. Simulation experiments conducted under reverberation conditions and with moving sound sources demonstrate that the proposed method can achieve more accurate separation based on more precise tracking results.
TSE-PI: Target Sound Extraction under Reverberant Environments with Pitch Information
Jun 13, 2024



Target sound extraction (TSE) separates the target sound from the mixture signals based on provided clues. However, the performance of existing models significantly degrades under reverberant conditions. Inspired by auditory scene analysis (ASA), this work proposes a TSE model provided with pitch information named TSE-PI. Conditional pitch extraction is achieved through the Feature-wise Linearly Modulated layer with the sound-class label. A modified Waveformer model combined with pitch information, employing a learnable Gammatone filterbank in place of the convolutional encoder, is used for target sound extraction. The inclusion of pitch information is aimed at improving the model's performance. The experimental results on the FSD50K dataset illustrate 2.4 dB improvements of target sound extraction under reverberant environments when incorporating pitch information and Gammatone filterbank.
Beware of Overestimated Decoding Performance Arising from Temporal Autocorrelations in Electroencephalogram Signals
May 27, 2024



Researchers have reported high decoding accuracy (>95%) using non-invasive Electroencephalogram (EEG) signals for brain-computer interface (BCI) decoding tasks like image decoding, emotion recognition, auditory spatial attention detection, etc. Since these EEG data were usually collected with well-designed paradigms in labs, the reliability and robustness of the corresponding decoding methods were doubted by some researchers, and they argued that such decoding accuracy was overestimated due to the inherent temporal autocorrelation of EEG signals. However, the coupling between the stimulus-driven neural responses and the EEG temporal autocorrelations makes it difficult to confirm whether this overestimation exists in truth. Furthermore, the underlying pitfalls behind overestimated decoding accuracy have not been fully explained due to a lack of appropriate formulation. In this work, we formulate the pitfall in various EEG decoding tasks in a unified framework. EEG data were recorded from watermelons to remove stimulus-driven neural responses. Labels were assigned to continuous EEG according to the experimental design for EEG recording of several typical datasets, and then the decoding methods were conducted. The results showed the label can be successfully decoded as long as continuous EEG data with the same label were split into training and test sets. Further analysis indicated that high accuracy of various BCI decoding tasks could be achieved by associating labels with EEG intrinsic temporal autocorrelation features. These results underscore the importance of choosing the right experimental designs and data splits in BCI decoding tasks to prevent inflated accuracies due to EEG temporal autocorrelation.