 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHINE: Sequential Hierarchical Integration Network for EEG and MEG
Feb 27, 2026How natural speech is represented in the brain constitutes a major challenge for cognitive neuroscience, with cortical envelope-following responses playing a central role in speech decoding. This paper presents our approach to the Speech Detection task in the LibriBrain Competition 2025, utilizing over 50 hours of magnetoencephalography (MEG) signals from a single participant listening to LibriVox audiobooks. We introduce the proposed Sequential Hierarchical Integration Network for EEG and MEG (SHINE) to reconstruct the binary speech-silence sequences from MEG signals. In the Extended Track, we further incorporated auxiliary reconstructions of speech envelopes and Mel spectrograms to enhance training. Ensemble methods combining SHINE with baselines (BrainMagic, AWavNet, ConvConcatNet) achieved F1-macro scores of 0.9155 (Standard Track) and 0.9184 (Extended Track) on the leaderboard test set.
Using Ear-EEG to Decode Auditory Attention in Multiple-speaker Environment
Sep 13, 2024



Auditory Attention Decoding (AAD) can help to determine the identity of the attended speaker during an auditory selective attention task, by analyzing and processing measurements of electroencephalography (EEG) data. Most studies on AAD are based on scalp-EEG signals in two-speaker scenarios, which are far from real application. Ear-EEG has recently gained significant attention due to its motion tolerance and invisibility during data acquisition, making it easy to incorporate with other devices for applications. In this work, participants selectively attended to one of the four spatially separated speakers' speech in an anechoic room. The EEG data were concurrently collected from a scalp-EEG system and an ear-EEG system (cEEGrids). Temporal response functions (TRFs) and stimulus reconstruction (SR) were utilized using ear-EEG data. Results showed that the attended speech TRFs were stronger than each unattended speech and decoding accuracy was 41.3\% in the 60s (chance level of 25\%). To further investigate the impact of electrode placement and quantity, SR was utilized in both scalp-EEG and ear-EEG, revealing that while the number of electrodes had a minor effect, their positioning had a significant influence on the decoding accuracy. One kind of auditory spatial attention detection (ASAD) method, STAnet, was testified with this ear-EEG database, resulting in 93.1% in 1-second decoding window. The implementation code and database for our work are available on GitHub: https://github.com/zhl486/Ear_EEG_code.git and Zenodo: https://zenodo.org/records/10803261.
Beware of Overestimated Decoding Performance Arising from Temporal Autocorrelations in Electroencephalogram Signals
May 27, 2024



Researchers have reported high decoding accuracy (>95%) using non-invasive Electroencephalogram (EEG) signals for brain-computer interface (BCI) decoding tasks like image decoding, emotion recognition, auditory spatial attention detection, etc. Since these EEG data were usually collected with well-designed paradigms in labs, the reliability and robustness of the corresponding decoding methods were doubted by some researchers, and they argued that such decoding accuracy was overestimated due to the inherent temporal autocorrelation of EEG signals. However, the coupling between the stimulus-driven neural responses and the EEG temporal autocorrelations makes it difficult to confirm whether this overestimation exists in truth. Furthermore, the underlying pitfalls behind overestimated decoding accuracy have not been fully explained due to a lack of appropriate formulation. In this work, we formulate the pitfall in various EEG decoding tasks in a unified framework. EEG data were recorded from watermelons to remove stimulus-driven neural responses. Labels were assigned to continuous EEG according to the experimental design for EEG recording of several typical datasets, and then the decoding methods were conducted. The results showed the label can be successfully decoded as long as continuous EEG data with the same label were split into training and test sets. Further analysis indicated that high accuracy of various BCI decoding tasks could be achieved by associating labels with EEG intrinsic temporal autocorrelation features. These results underscore the importance of choosing the right experimental designs and data splits in BCI decoding tasks to prevent inflated accuracies due to EEG temporal autocorrelation.
Self-supervised speech representation and contextual text embedding for match-mismatch classification with EEG recording
Feb 01, 2024

Relating speech to EEG holds considerable importance but is challenging. In this study, a deep convolutional network was employed to extract spatiotemporal features from EEG data. Self-supervised speech representation and contextual text embedding were used as speech features. Contrastive learning was used to relate EEG features to speech features. The experimental results demonstrate the benefits of using self-supervised speech representation and contextual text embedding. Through feature fusion and model ensemble, an accuracy of 60.29% was achieved, and the performance was ranked as No.2 in Task 1 of the Auditory EEG Challenge (ICASSP 2024). The code to implement our work is available on Github: https://github.com/bobwangPKU/EEG-Stimulus-Match-Mismatch.
ConvConcatNet: a deep convolutional neural network to reconstruct mel spectrogram from the EEG
Jan 10, 2024To investigate the processing of speech in the brain, simple linear models are commonly used to establish a relationship between brain signals and speech features. However, these linear models are ill-equipped to model a highly dynamic and complex non-linear system like the brain. Although non-linear methods with neural networks have been developed recently, reconstructing unseen stimuli from unseen subjects' EEG is still a highly challenging task. This work presents a novel method, ConvConcatNet, to reconstruct mel-specgrams from EEG, in which the deep convolution neural network and extensive concatenation operation were combined. With our ConvConcatNet model, the Pearson correlation between the reconstructed and the target mel-spectrogram can achieve 0.0420, which was ranked as No.1 in the Task 2 of the Auditory EEG Challenge. The codes and models to implement our work will be available on Github: https://github.com/xuxiran/ConvConcatNet
Semantic reconstruction of continuous language from MEG signals
Sep 14, 2023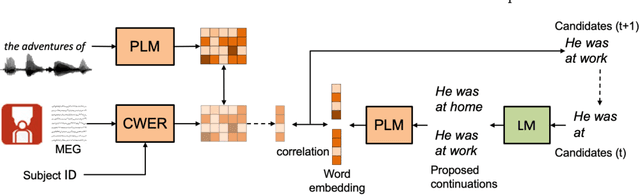
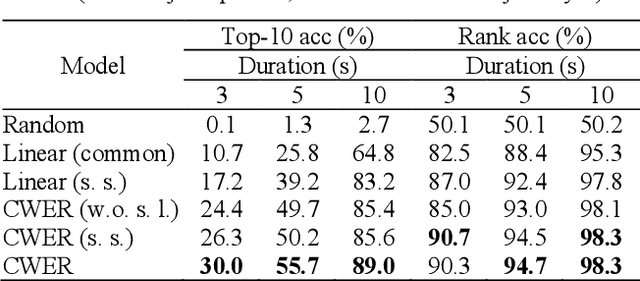
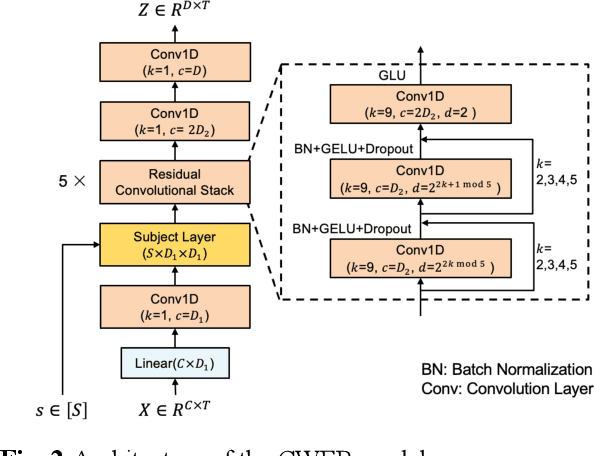
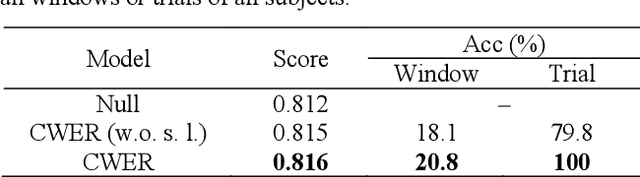
Decoding language from neural signals holds considerable theoretical and practical importance. Previous research has indicated the feasibility of decoding text or speech from invasive neural signals. However, when using non-invasive neural signals, significant challenges are encountered due to their low quality. In this study, we proposed a data-driven approach for decoding semantic of language from Magnetoencephalography (MEG) signals recorded while subjects were listening to continuous speech. First, a multi-subject decoding model was trained using contrastive learning to reconstruct continuous word embeddings from MEG data. Subsequently, a beam search algorithm was adopted to generate text sequences based on the reconstructed word embeddings. Given a candidate sentence in the beam, a language model was used to predict the subsequent words. The word embeddings of the subsequent words were correlated with the reconstructed word embedding. These correlations were then used as a measure of the probability for the next word. The results showed that the proposed continuous word embedding model can effectively leverage both subject-specific and subject-shared information. Additionally, the decoded text exhibited significant similarity to the target text, with an average BERTScore of 0.816, a score comparable to that in the previous fMRI study.
A DenseNet-based method for decoding auditory spatial attention with EEG
Sep 14, 2023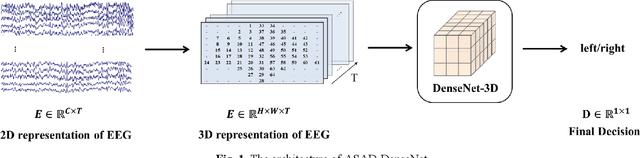
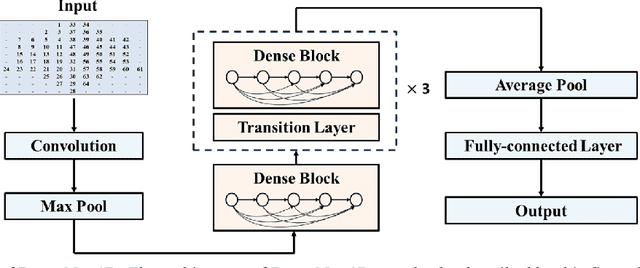
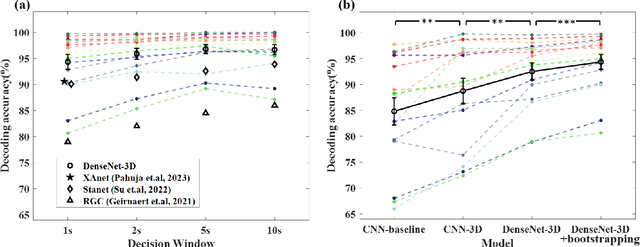
Auditory spatial attention detection (ASAD) aims to decode the attended spatial location with EEG in a multiple-speaker setting. ASAD methods are inspired by the brain lateralization of cortical neural responses during the processing of auditory spatial attention, and show promising performance for the task of auditory attention decoding (AAD) with neural recordings. In the previous ASAD methods, the spatial distribution of EEG electrodes is not fully exploited, which may limit the performance of these methods. In the present work, by transforming the original EEG channels into a two-dimensional (2D) spatial topological map, the EEG data is transformed into a three-dimensional (3D) arrangement containing spatial-temporal information. And then a 3D deep convolutional neural network (DenseNet-3D) is used to extract temporal and spatial features of the neural representation for the attended locations. The results show that the proposed method achieves higher decoding accuracy than the state-of-the-art (SOTA) method (94.4% compared to XANet's 90.6%) with 1-second decision window for the widely used KULeuven (KUL) dataset, and the code to implement our work is available on Github: https://github.com/xuxiran/ASAD_DenseNet