 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINT: Multi-modal Chain of Thought in Unified Generative Models for Enhanced Image Generation
Mar 03, 2025Unified generative models have demonstrated extraordinary performance in both text and image generation. However, they tend to underperform when generating intricate images with various interwoven conditions, which is hard to solely rely on straightforward text-to-image generation. In response to this challenge, we introduce MINT, an innovative unified generative model, empowered with native multimodal chain of thought (MCoT) for enhanced image generation for the first time. Firstly, we design Mixture of Transformer Experts (MTXpert), an expert-parallel structure that effectively supports both natural language generation (NLG) and visual capabilities, while avoiding potential modality conflicts that could hinder the full potential of each modality. Building on this, we propose an innovative MCoT training paradigm, a step-by-step approach to multimodal thinking, reasoning, and reflection specifically designed to enhance image generation. This paradigm equips MINT with nuanced, element-wise decoupled alignment and a comprehensive understanding of textual and visual components. Furthermore, it fosters advanced multimodal reasoning and self-reflection, enabling the construction of images that are firmly grounded in the logical relationships between these elements. Notably, MINT has been validated to exhibit superior performance across multiple benchmarks for text-to-image (T2I) and image-to-text (I2T) tasks.
Causal Adjacency Learning for Spatiotemporal Prediction Over Graphs
Nov 25, 2024



Spatiotemporal prediction over graphs (STPG) is crucial for transportation systems. In existing STPG models, an adjacency matrix is an important component that captures the relations among nodes over graphs. However, most studies calculate the adjacency matrix by directly memorizing the data, such as distance- and correlation-based matrices. These adjacency matrices do not consider potential pattern shift for the test data, and may result in suboptimal performance if the test data has a different distribution from the training one. This issue is known as the Out-of-Distribution generalization problem. To address this issue, in this paper we propose a Causal Adjacency Learning (CAL) method to discover causal relations over graphs. The learned causal adjacency matrix is evaluated on a downstream spatiotemporal prediction task using real-world graph data. Results demonstrate that our proposed adjacency matrix can capture the causal relations, and using our learned adjacency matrix can enhance prediction performance on the OOD test data, even though causal learning is not conducted in the downstream task.
Semantic reconstruction of continuous language from MEG signals
Sep 14, 2023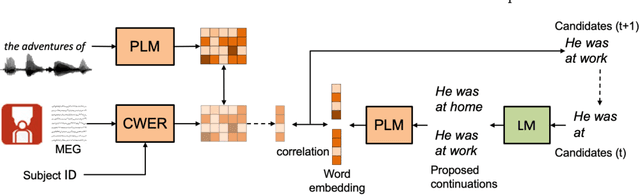
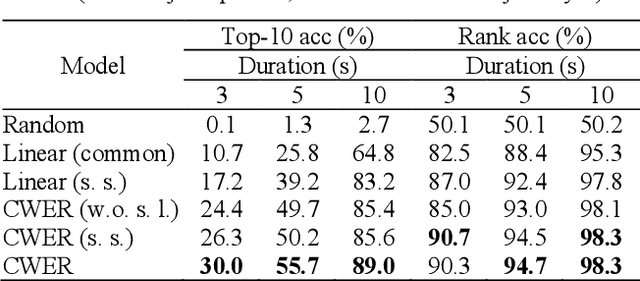
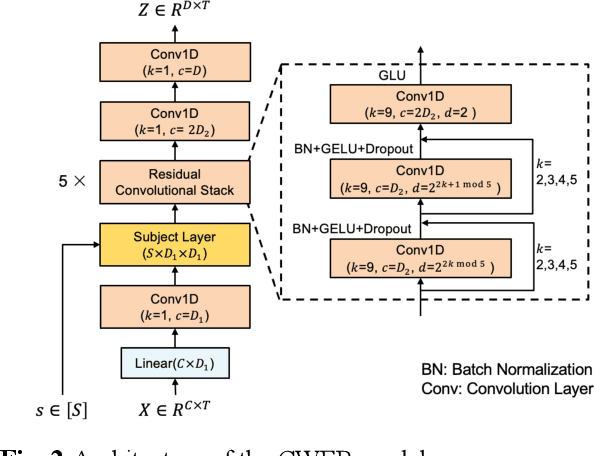
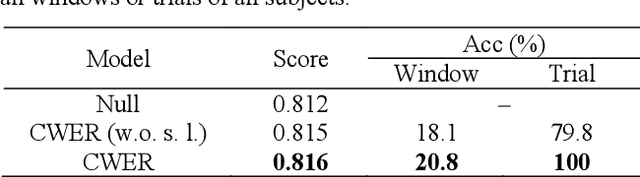
Decoding language from neural signals holds considerable theoretical and practical importance. Previous research has indicated the feasibility of decoding text or speech from invasive neural signals. However, when using non-invasive neural signals, significant challenges are encountered due to their low quality. In this study, we proposed a data-driven approach for decoding semantic of language from Magnetoencephalography (MEG) signals recorded while subjects were listening to continuous speech. First, a multi-subject decoding model was trained using contrastive learning to reconstruct continuous word embeddings from MEG data. Subsequently, a beam search algorithm was adopted to generate text sequences based on the reconstructed word embeddings. Given a candidate sentence in the beam, a language model was used to predict the subsequent words. The word embeddings of the subsequent words were correlated with the reconstructed word embedding. These correlations were then used as a measure of the probability for the next word. The results showed that the proposed continuous word embedding model can effectively leverage both subject-specific and subject-shared information. Additionally, the decoded text exhibited significant similarity to the target text, with an average BERTScore of 0.816, a score comparable to that in the previous fMRI study.
Multi-Modal Machine Learning for Assessing Gaming Skills in Online Streaming: A Case Study with CS:GO
Jul 23, 2023Online streaming is an emerging market that address much attention. Assessing gaming skills from videos is an important task for streaming service providers to discover talented gamers. Service providers require the information to offer customized recommendation and service promotion to their customers. Meanwhile, this is also an important multi-modal machine learning tasks since online streaming combines vision, audio and text modalities. In this study we begin by identifying flaws in the dataset and proceed to clean it manually. Then we propose several variants of latest end-to-end models to learn joint representation of multiple modalities. Through our extensive experimentation, we demonstrate the efficacy of our proposals. Moreover, we identify that our proposed models is prone to identifying users instead of learning meaningful representations. We purpose future work to address the issue in the end.
Leveraging Pretrained Models for Automatic Summarization of Doctor-Patient Conversations
Sep 24, 2021

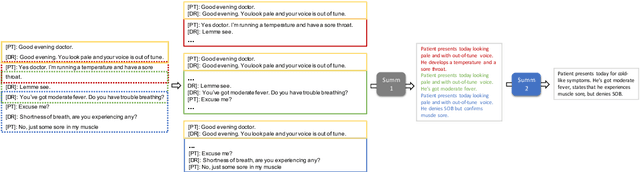
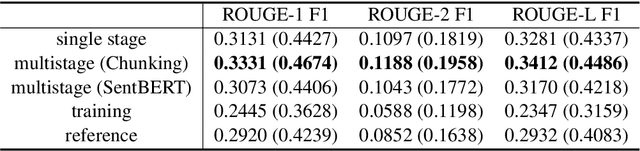
Fine-tuning pretrained models for automatically summarizing doctor-patient conversation transcripts presents many challenges: limited training data, significant domain shift, long and noisy transcripts, and high target summary variability. In this paper, we explore the feasibility of using pretrained transformer models for automatically summarizing doctor-patient conversations directly from transcripts. We show that fluent and adequate summaries can be generated with limited training data by fine-tuning BART on a specially constructed dataset. The resulting models greatly surpass the performance of an average human annotator and the quality of previous published work for the task. We evaluate multiple methods for handling long conversations, comparing them to the obvious baseline of truncating the conversation to fit the pretrained model length limit. We introduce a multistage approach that tackles the task by learning two fine-tuned models: one for summarizing conversation chunks into partial summaries, followed by one for rewriting the collection of partial summaries into a complete summary. Using a carefully chosen fine-tuning dataset, this method is shown to be effective at handling longer conversations, improving the quality of generated summaries. We conduct both an automatic evaluation (through ROUGE and two concept-based metrics focusing on medical findings) and a human evaluation (through qualitative examples from literature, assessing hallucination, generalization, fluency, and general quality of the generated summaries).