 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaFocal: Calibration-aware Adaptive Focal Loss
Nov 21, 2022



Much recent work has been devoted to the problem of ensuring that a neural network's confidence scores match the true probability of being correct, i.e. the calibration problem. Of note, it was found that training with focal loss leads to better calibration than cross-entropy while achieving similar level of accuracy \cite{mukhoti2020}. This success stems from focal loss regularizing the entropy of the model's prediction (controlled by the parameter $\gamma$), thereby reining in the model's overconfidence. Further improvement is expected if $\gamma$ is selected independently for each training sample (Sample-Dependent Focal Loss (FLSD-53) \cite{mukhoti2020}). However, FLSD-53 is based on heuristics and does not generalize well. In this paper, we propose a calibration-aware adaptive focal loss called AdaFocal that utilizes the calibration properties of focal (and inverse-focal) loss and adaptively modifies $\gamma_t$ for different groups of samples based on $\gamma_{t-1}$ from the previous step and the knowledge of model's under/over-confidence on the validation set. We evaluate AdaFocal on various image recognition and one NLP task, covering a wide variety of network architectures, to confirm the improvement in calibration while achieving similar levels of accuracy. Additionally, we show that models trained with AdaFocal achieve a significant boost in out-of-distribution detection.
Low-resource Low-footprint Wake-word Detection using Knowledge Distillation
Jul 06, 2022
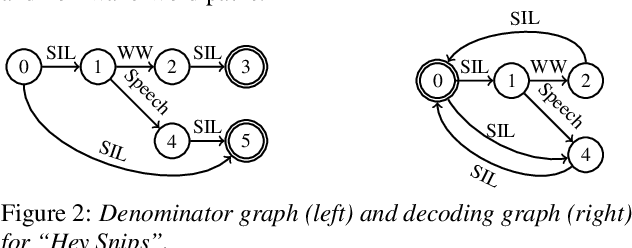
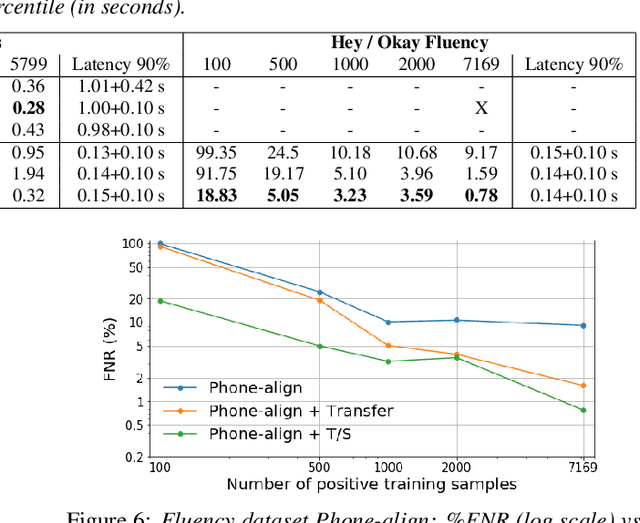
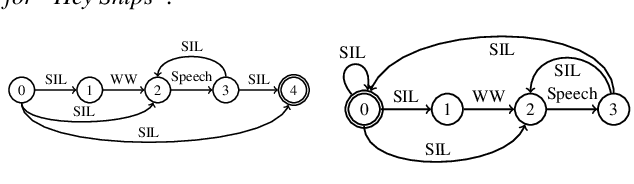
As virtual assistants have become more diverse and specialized, so has the demand for application or brand-specific wake words. However, the wake-word-specific datasets typically used to train wake-word detectors are costly to create. In this paper, we explore two techniques to leverage acoustic modeling data for large-vocabulary speech recognition to improve a purpose-built wake-word detector: transfer learning and knowledge distillation. We also explore how these techniques interact with time-synchronous training targets to improve detection latency. Experiments are presented on the open-source "Hey Snips" dataset and a more challenging in-house far-field dataset. Using phone-synchronous targets and knowledge distillation from a large acoustic model, we are able to improve accuracy across dataset sizes for both datasets while reducing latency.
Leveraging Pretrained Models for Automatic Summarization of Doctor-Patient Conversations
Sep 24, 2021

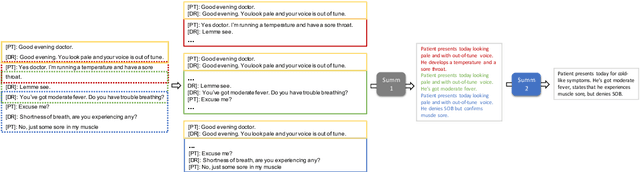
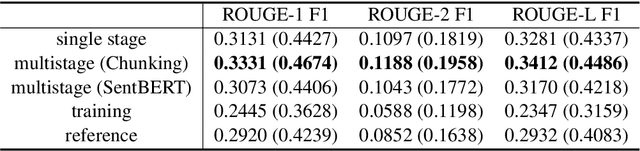
Fine-tuning pretrained models for automatically summarizing doctor-patient conversation transcripts presents many challenges: limited training data, significant domain shift, long and noisy transcripts, and high target summary variability. In this paper, we explore the feasibility of using pretrained transformer models for automatically summarizing doctor-patient conversations directly from transcripts. We show that fluent and adequate summaries can be generated with limited training data by fine-tuning BART on a specially constructed dataset. The resulting models greatly surpass the performance of an average human annotator and the quality of previous published work for the task. We evaluate multiple methods for handling long conversations, comparing them to the obvious baseline of truncating the conversation to fit the pretrained model length limit. We introduce a multistage approach that tackles the task by learning two fine-tuned models: one for summarizing conversation chunks into partial summaries, followed by one for rewriting the collection of partial summaries into a complete summary. Using a carefully chosen fine-tuning dataset, this method is shown to be effective at handling longer conversations, improving the quality of generated summaries. We conduct both an automatic evaluation (through ROUGE and two concept-based metrics focusing on medical findings) and a human evaluation (through qualitative examples from literature, assessing hallucination, generalization, fluency, and general quality of the generated summaries).
Depression Severity Estimation from Multiple Modalities
Nov 10, 2017



Depression is a major debilitating disorder which can affect people from all ages. With a continuous increase in the number of annual cases of depression, there is a need to develop automatic techniques for the detection of the presence and extent of depression. In this AVEC challenge we explore different modalities (speech, language and visual features extracted from face) to design and develop automatic methods for the detection of depression. In psychology literature, the PHQ-8 questionnaire is well established as a tool for measuring the severity of depression. In this paper we aim to automatically predict the PHQ-8 scores from features extracted from the different modalities. We show that visual features extracted from facial landmarks obtain the best performance in terms of estimating the PHQ-8 results with a mean absolute error (MAE) of 4.66 on the development set. Behavioral characteristics from speech provide an MAE of 4.73. Language features yield a slightly higher MAE of 5.17. When switching to the test set, our Turn Features derived from audio transcriptions achieve the best performance, scoring an MAE of 4.11 (corresponding to an RMSE of 4.94), which makes our system the winner of the AVEC 2017 depression sub-challenge.