 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting text decomposition methods for NLI-based factuality scoring of summaries
Nov 30, 2022



Scoring the factuality of a generated summary involves measuring the degree to which a target text contains factual information using the input document as support. Given the similarities in the problem formulation, previous work has shown that Natural Language Inference models can be effectively repurposed to perform this task. As these models are trained to score entailment at a sentence level, several recent studies have shown that decomposing either the input document or the summary into sentences helps with factuality scoring. But is fine-grained decomposition always a winning strategy? In this paper we systematically compare different granularities of decomposition -- from document to sub-sentence level, and we show that the answer is no. Our results show that incorporating additional context can yield improvement, but that this does not necessarily apply to all datasets. We also show that small changes to previously proposed entailment-based scoring methods can result in better performance, highlighting the need for caution in model and methodology selection for downstream tasks.
Leveraging Pretrained Models for Automatic Summarization of Doctor-Patient Conversations
Sep 24, 2021

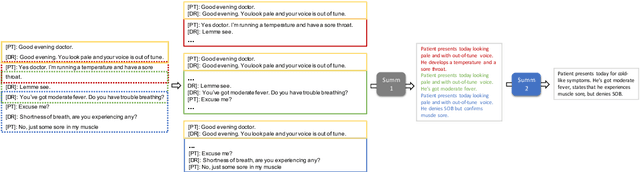
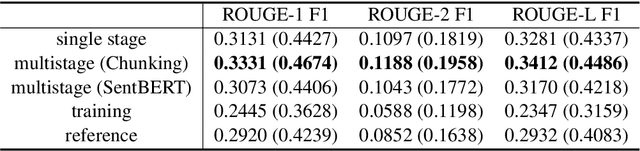
Fine-tuning pretrained models for automatically summarizing doctor-patient conversation transcripts presents many challenges: limited training data, significant domain shift, long and noisy transcripts, and high target summary variability. In this paper, we explore the feasibility of using pretrained transformer models for automatically summarizing doctor-patient conversations directly from transcripts. We show that fluent and adequate summaries can be generated with limited training data by fine-tuning BART on a specially constructed dataset. The resulting models greatly surpass the performance of an average human annotator and the quality of previous published work for the task. We evaluate multiple methods for handling long conversations, comparing them to the obvious baseline of truncating the conversation to fit the pretrained model length limit. We introduce a multistage approach that tackles the task by learning two fine-tuned models: one for summarizing conversation chunks into partial summaries, followed by one for rewriting the collection of partial summaries into a complete summary. Using a carefully chosen fine-tuning dataset, this method is shown to be effective at handling longer conversations, improving the quality of generated summaries. We conduct both an automatic evaluation (through ROUGE and two concept-based metrics focusing on medical findings) and a human evaluation (through qualitative examples from literature, assessing hallucination, generalization, fluency, and general quality of the generated summaries).