 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIC-BART-SSA: Controllable Image Captioning with Structured Semantic Augmentation
Jul 16, 2024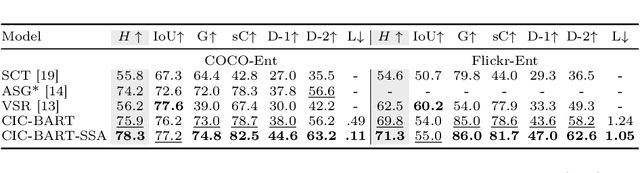
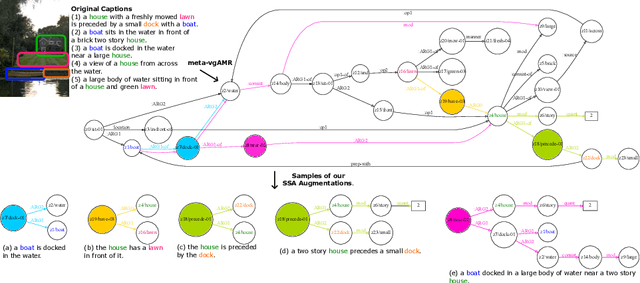


Controllable Image Captioning (CIC) aims at generating natural language descriptions for an image, conditioned on information provided by end users, e.g., regions, entities or events of interest. However, available image--language datasets mainly contain captions that describe the entirety of an image, making them ineffective for training CIC models that can potentially attend to any subset of regions or relationships. To tackle this challenge, we propose a novel, fully automatic method to sample additional focused and visually grounded captions using a unified structured semantic representation built on top of the existing set of captions associated with an image. We leverage Abstract Meaning Representation (AMR), a cross-lingual graph-based semantic formalism, to encode all possible spatio-semantic relations between entities, beyond the typical spatial-relations-only focus of current methods. We use this Structured Semantic Augmentation (SSA) framework to augment existing image--caption datasets with the grounded controlled captions, increasing their spatial and semantic diversity and focal coverage. We then develop a new model, CIC-BART-SSA, specifically tailored for the CIC task, that sources its control signals from SSA-diversified datasets. We empirically show that, compared to SOTA CIC models, CIC-BART-SSA generates captions that are superior in diversity and text quality, are competitive in controllability, and, importantly, minimize the gap between broad and highly focused controlled captioning performance by efficiently generalizing to the challenging highly focused scenarios. Code is available at https://github.com/SamsungLabs/CIC-BART-SSA.
Revisiting text decomposition methods for NLI-based factuality scoring of summaries
Nov 30, 2022



Scoring the factuality of a generated summary involves measuring the degree to which a target text contains factual information using the input document as support. Given the similarities in the problem formulation, previous work has shown that Natural Language Inference models can be effectively repurposed to perform this task. As these models are trained to score entailment at a sentence level, several recent studies have shown that decomposing either the input document or the summary into sentences helps with factuality scoring. But is fine-grained decomposition always a winning strategy? In this paper we systematically compare different granularities of decomposition -- from document to sub-sentence level, and we show that the answer is no. Our results show that incorporating additional context can yield improvement, but that this does not necessarily apply to all datasets. We also show that small changes to previously proposed entailment-based scoring methods can result in better performance, highlighting the need for caution in model and methodology selection for downstream tasks.
Visual Semantic Parsing: From Images to Abstract Meaning Representation
Oct 27, 2022The success of scene graphs for visual scene understanding has brought attention to the benefits of abstracting a visual input (e.g., image) into a structured representation, where entities (people and objects) are nodes connected by edges specifying their relations. Building these representations, however, requires expensive manual annotation in the form of images paired with their scene graphs or frames. These formalisms remain limited in the nature of entities and relations they can capture. In this paper, we propose to leverage a widely-used meaning representation in the field of natural language processing, the Abstract Meaning Representation (AMR), to address these shortcomings. Compared to scene graphs, which largely emphasize spatial relationships, our visual AMR graphs are more linguistically informed, with a focus on higher-level semantic concepts extrapolated from visual input. Moreover, they allow us to generate meta-AMR graphs to unify information contained in multiple image descriptions under one representation. Through extensive experimentation and analysis, we demonstrate that we can re-purpose an existing text-to-AMR parser to parse images into AMRs. Our findings point to important future research directions for improved scene understanding.
Semantic Graph Parsing with Recurrent Neural Network DAG Grammars
Oct 20, 2019
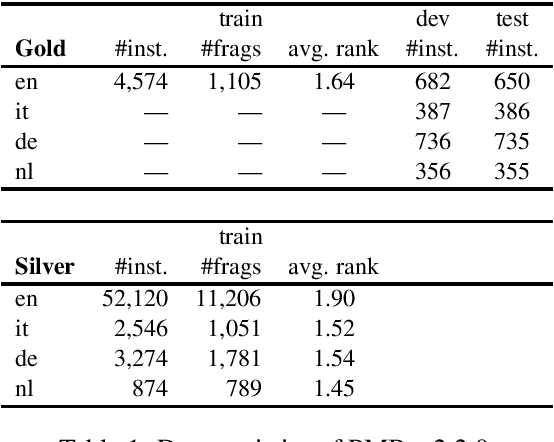
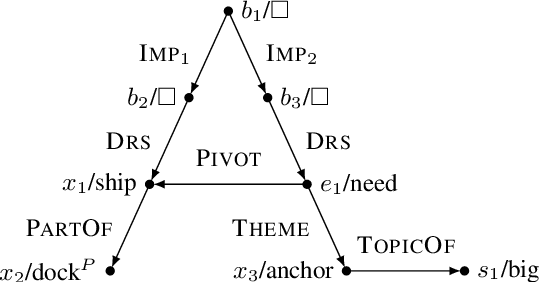

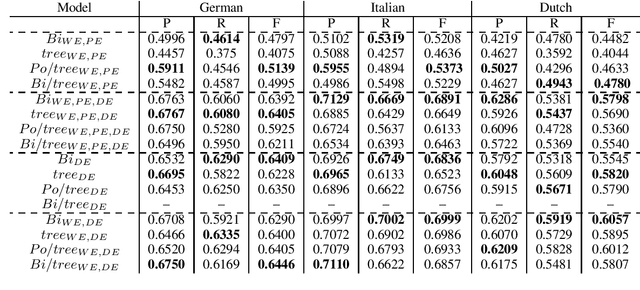
Semantic parses are directed acyclic graphs (DAGs), so semantic parsing should be modeled as graph prediction. But predicting graphs presents difficult technical challenges, so it is simpler and more common to predict the linearized graphs found in semantic parsing datasets using well-understood sequence models. The cost of this simplicity is that the predicted strings may not be well-formed graphs. We present recurrent neural network DAG grammars, a graph-aware sequence model that ensures only well-formed graphs while sidestepping many difficulties in graph prediction. We test our model on the Parallel Meaning Bank---a multilingual semantic graphbank. Our approach yields competitive results in English and establishes the first results for German, Italian and Dutch.
A survey of cross-lingual features for zero-shot cross-lingual semantic parsing
Aug 27, 2019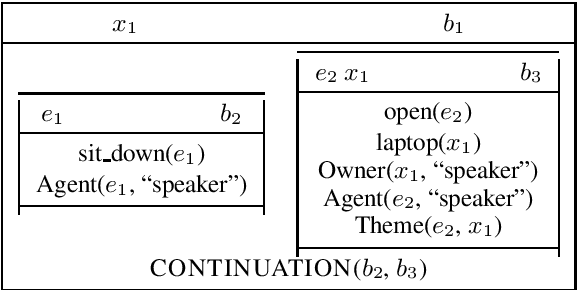
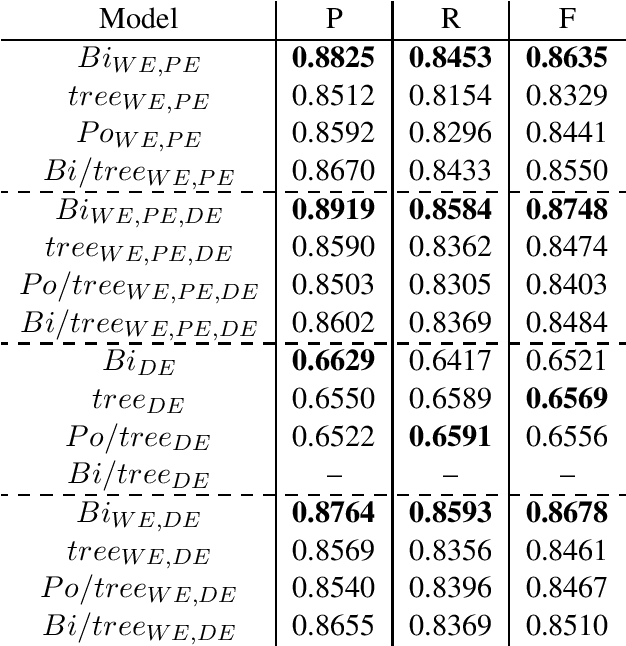
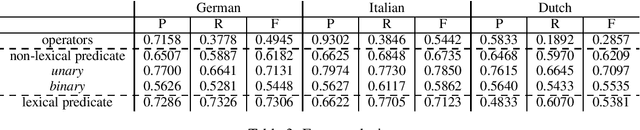
The availability of corpora to train semantic parsers in English has lead to significant advances in the field. Unfortunately, for languages other than English, annotation is scarce and so are developed parsers. We then ask: could a parser trained in English be applied to language that it hasn't been trained on? To answer this question we explore zero-shot cross-lingual semantic parsing where we train an available coarse-to-fine semantic parser (Liu et al., 2018) using cross-lingual word embeddings and universal dependencies in English and test it on Italian, German and Dutch. Results on the Parallel Meaning Bank - a multilingual semantic graphbank, show that Universal Dependency features significantly boost performance when used in conjunction with other lexical features but modelling the UD structure directly when encoding the input does not.
Talking to myself: self-dialogues as data for conversational agents
Sep 19, 2018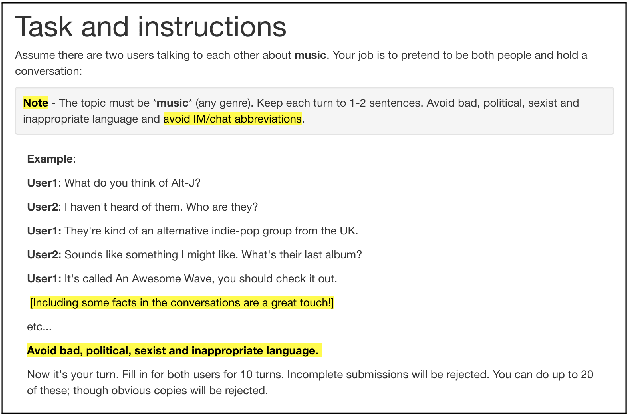
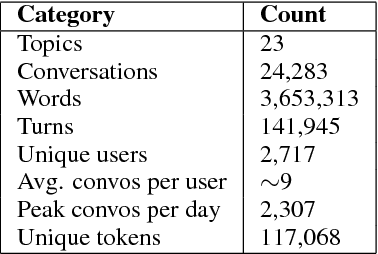
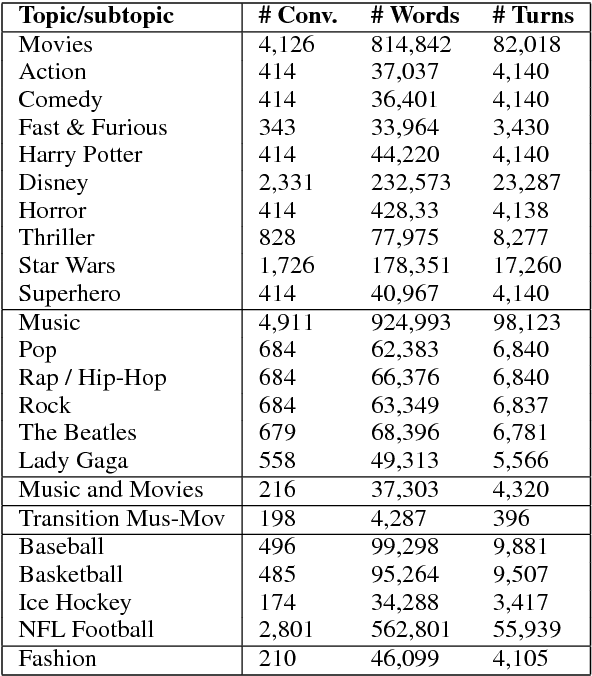
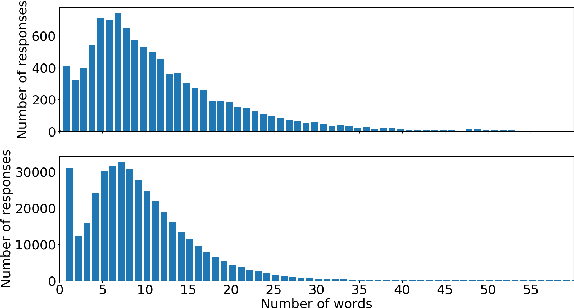
Conversational agents are gaining popularity with the increasing ubiquity of smart devices. However, training agents in a data driven manner is challenging due to a lack of suitable corpora. This paper presents a novel method for gathering topical, unstructured conversational data in an efficient way: self-dialogues through crowd-sourcing. Alongside this paper, we include a corpus of 3.6 million words across 23 topics. We argue the utility of the corpus by comparing self-dialogues with standard two-party conversations as well as data from other corpora.
Evaluating Machine Translation Performance on Chinese Idioms with a Blacklist Method
Feb 20, 2018
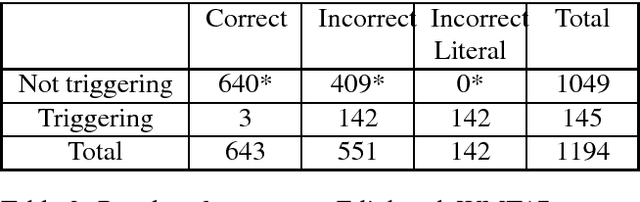

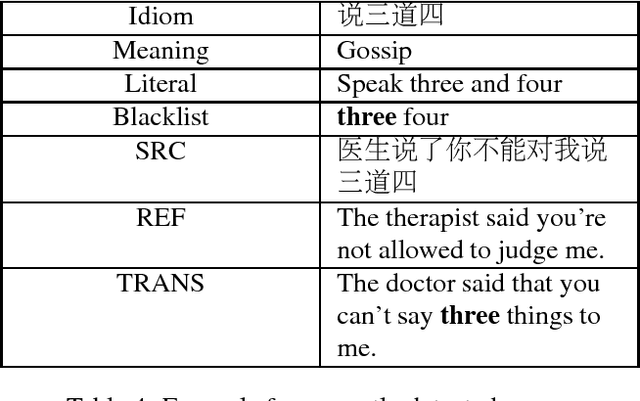
Idiom translation is a challenging problem in machine translation because the meaning of idioms is non-compositional, and a literal (word-by-word) translation is likely to be wrong. In this paper, we focus on evaluating the quality of idiom translation of MT systems. We introduce a new evaluation method based on an idiom-specific blacklist of literal translations, based on the insight that the occurrence of any blacklisted words in the translation output indicates a likely translation error. We introduce a dataset, CIBB (Chinese Idioms Blacklists Bank), and perform an evaluation of a state-of-the-art Chinese-English neural MT system. Our evaluation confirms that a sizable number of idioms in our test set are mistranslated (46.1%), that literal translation error is a common error type, and that our blacklist method is effective at identifying literal translation errors.
Edina: Building an Open Domain Socialbot with Self-dialogues
Sep 28, 2017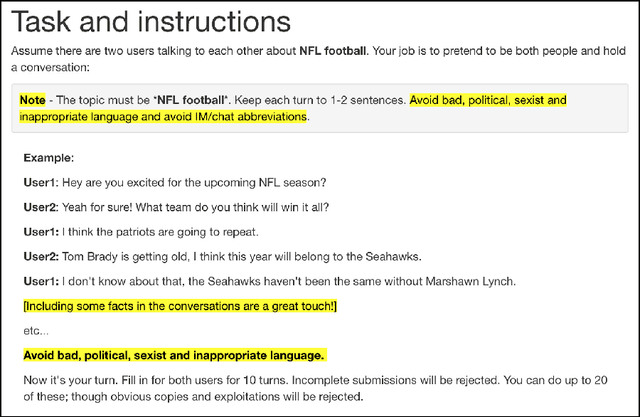
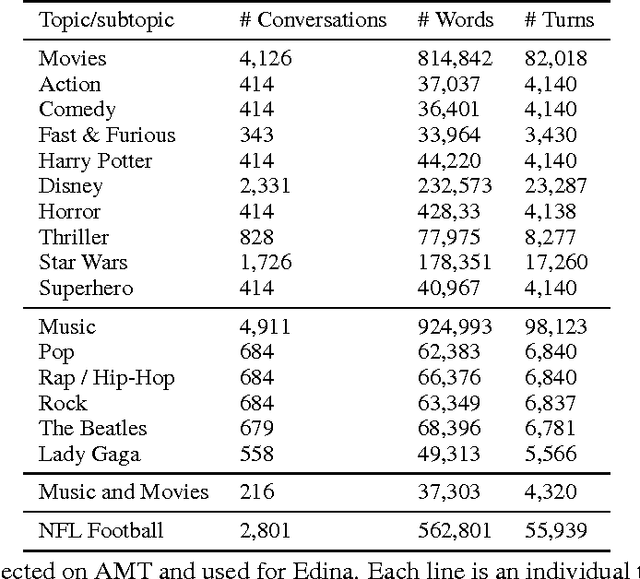
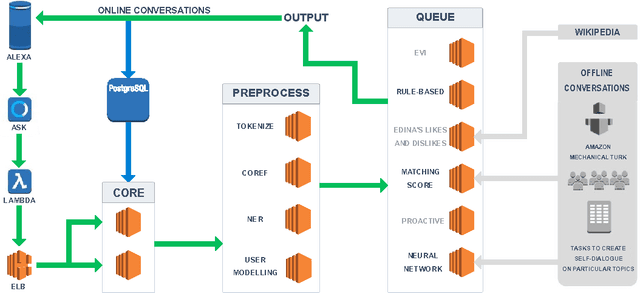

We present Edina, the University of Edinburgh's social bot for the Amazon Alexa Prize competition. Edina is a conversational agent whose responses utilize data harvested from Amazon Mechanical Turk (AMT) through an innovative new technique we call self-dialogues. These are conversations in which a single AMT Worker plays both participants in a dialogue. Such dialogues are surprisingly natural, efficient to collect and reflective of relevant and/or trending topics. These self-dialogues provide training data for a generative neural network as well as a basis for soft rules used by a matching score component. Each match of a soft rule against a user utterance is associated with a confidence score which we show is strongly indicative of reply quality, allowing this component to self-censor and be effectively integrated with other components. Edina's full architecture features a rule-based system backing off to a matching score, backing off to a generative neural network. Our hybrid data-driven methodology thus addresses both coverage limitations of a strictly rule-based approach and the lack of guarantees of a strictly machine-learning approach.