Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalking to myself: self-dialogues as data for conversational agents
Paper and Code
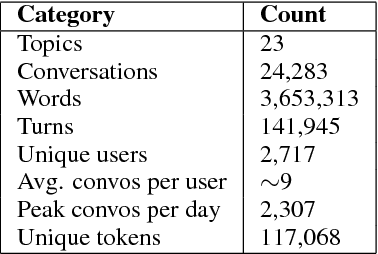
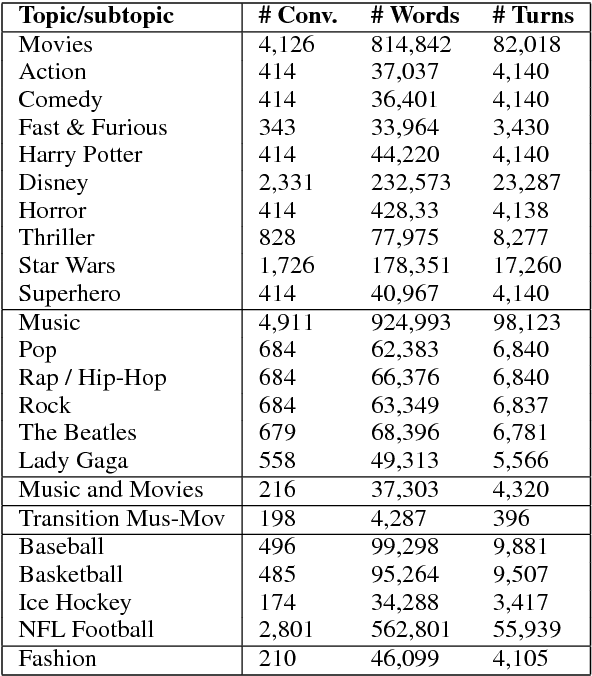
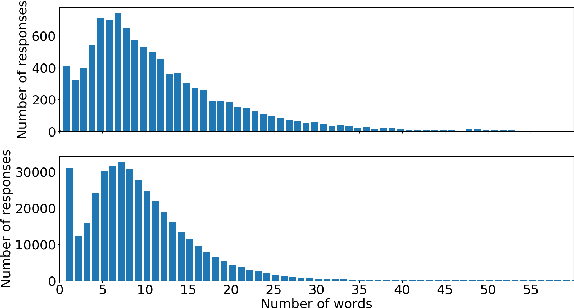
Conversational agents are gaining popularity with the increasing ubiquity of smart devices. However, training agents in a data driven manner is challenging due to a lack of suitable corpora. This paper presents a novel method for gathering topical, unstructured conversational data in an efficient way: self-dialogues through crowd-sourcing. Alongside this paper, we include a corpus of 3.6 million words across 23 topics. We argue the utility of the corpus by comparing self-dialogues with standard two-party conversations as well as data from other corpora.
* 5 pages, 5 pages appendix, 2 figures
View paper on