 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Hierarchical Prototypes as the Verbalizer for Implicit Discourse Relation Recognition
Nov 22, 2024Implicit discourse relation recognition involves determining relationships that hold between spans of text that are not linked by an explicit discourse connective. In recent years, the pre-train, prompt, and predict paradigm has emerged as a promising approach for tackling this task. However, previous work solely relied on manual verbalizers for implicit discourse relation recognition, which suffer from issues of ambiguity and even incorrectness. To overcome these limitations, we leverage the prototypes that capture certain class-level semantic features and the hierarchical label structure for different classes as the verbalizer. We show that our method improves on competitive baselines. Besides, our proposed approach can be extended to enable zero-shot cross-lingual learning, facilitating the recognition of discourse relations in languages with scarce resources. These advancement validate the practicality and versatility of our approach in addressing the issues of implicit discourse relation recognition across different languages.
Multi-Label Classification for Implicit Discourse Relation Recognition
Jun 06, 2024Discourse relations play a pivotal role in establishing coherence within textual content, uniting sentences and clauses into a cohesive narrative. The Penn Discourse Treebank (PDTB) stands as one of the most extensively utilized datasets in this domain. In PDTB-3, the annotators can assign multiple labels to an example, when they believe that multiple relations are present. Prior research in discourse relation recognition has treated these instances as separate examples during training, and only one example needs to have its label predicted correctly for the instance to be judged as correct. However, this approach is inadequate, as it fails to account for the interdependence of labels in real-world contexts and to distinguish between cases where only one sense relation holds and cases where multiple relations hold simultaneously. In our work, we address this challenge by exploring various multi-label classification frameworks to handle implicit discourse relation recognition. We show that multi-label classification methods don't depress performance for single-label prediction. Additionally, we give comprehensive analysis of results and data. Our work contributes to advancing the understanding and application of discourse relations and provide a foundation for the future study
Superlatives in Context: Explicit and Implicit Domain Restrictions for Superlative Frames
May 31, 2024Superlatives are used to single out elements with a maximal/minimal property. Semantically, superlatives perform a set comparison: something (or some things) has the min/max property out of a set. As such, superlatives provide an ideal phenomenon for studying implicit phenomena and discourse restrictions. While this comparison set is often not explicitly defined, its (implicit) restrictions can be inferred from the discourse context the expression appears in. In this work we provide an extensive computational study on the semantics of superlatives. We propose a unified account of superlative semantics which allows us to derive a broad-coverage annotation schema. Using this unified schema we annotated a multi-domain dataset of superlatives and their semantic interpretations. We specifically focus on interpreting implicit or ambiguous superlative expressions, by analyzing how the discourse context restricts the set of interpretations. In a set of experiments we then analyze how well models perform at variations of predicting superlative semantics, with and without context. We show that the fine-grained semantics of superlatives in context can be challenging for contemporary models, including GPT-4.
Findings of the WMT 2023 Shared Task on Discourse-Level Literary Translation: A Fresh Orb in the Cosmos of LLMs
Nov 06, 2023Translating literary works has perennially stood as an elusive dream in machine translation (MT), a journey steeped in intricate challenges. To foster progress in this domain, we hold a new shared task at WMT 2023, the first edition of the Discourse-Level Literary Translation. First, we (Tencent AI Lab and China Literature Ltd.) release a copyrighted and document-level Chinese-English web novel corpus. Furthermore, we put forth an industry-endorsed criteria to guide human evaluation process. This year, we totally received 14 submissions from 7 academia and industry teams. We employ both automatic and human evaluations to measure the performance of the submitted systems. The official ranking of the systems is based on the overall human judgments. In addition, our extensive analysis reveals a series of interesting findings on literary and discourse-aware MT. We release data, system outputs, and leaderboard at http://www2.statmt.org/wmt23/literary-translation-task.html.
A Joint Matrix Factorization Analysis of Multilingual Representations
Oct 24, 2023We present an analysis tool based on joint matrix factorization for comparing latent representations of multilingual and monolingual models. An alternative to probing, this tool allows us to analyze multiple sets of representations in a joint manner. Using this tool, we study to what extent and how morphosyntactic features are reflected in the representations learned by multilingual pre-trained models. We conduct a large-scale empirical study of over 33 languages and 17 morphosyntactic categories. Our findings demonstrate variations in the encoding of morphosyntactic information across upper and lower layers, with category-specific differences influenced by language properties. Hierarchical clustering of the factorization outputs yields a tree structure that is related to phylogenetic trees manually crafted by linguists. Moreover, we find the factorization outputs exhibit strong associations with performance observed across different cross-lingual tasks. We release our code to facilitate future research.
Facilitating Contrastive Learning of Discourse Relational Senses by Exploiting the Hierarchy of Sense Relations
Jan 06, 2023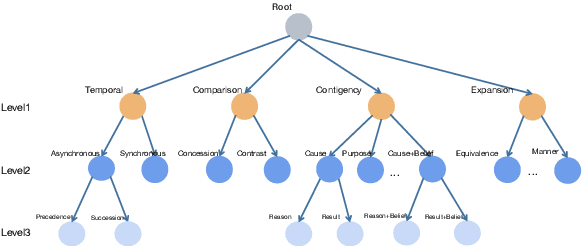
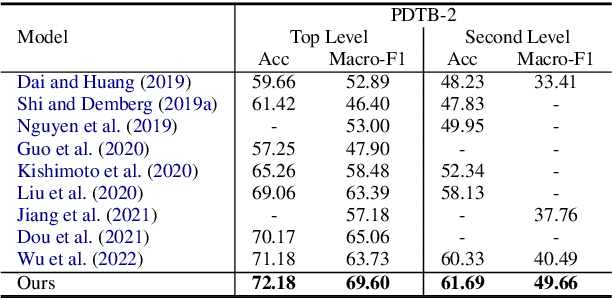
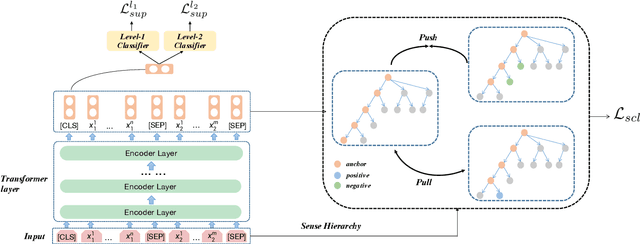
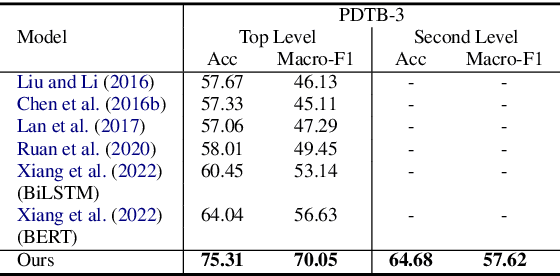
Implicit discourse relation recognition is a challenging task that involves identifying the sense or senses that hold between two adjacent spans of text, in the absence of an explicit connective between them. In both PDTB-2 and PDTB-3, discourse relational senses are organized into a three-level hierarchy ranging from four broad top-level senses, to more specific senses below them. Most previous work on implicit discourse relation recognition have used the sense hierarchy simply to indicate what sense labels were available. Here we do more -- incorporating the sense hierarchy into the recognition process itself and using it to select the negative examples used in contrastive learning. With no additional effort, the approach achieves state-of-the-art performance on the task.
Annotation Error Detection: Analyzing the Past and Present for a More Coherent Future
Jun 05, 2022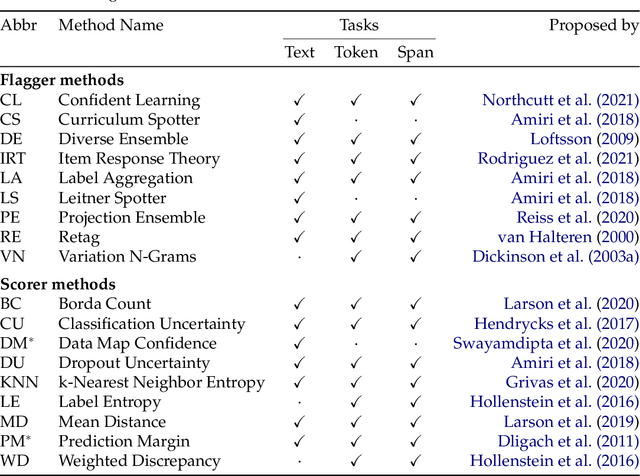
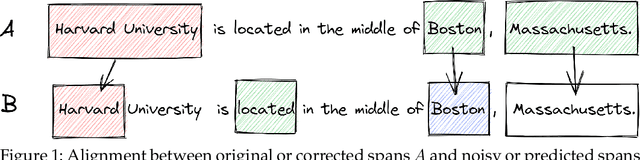
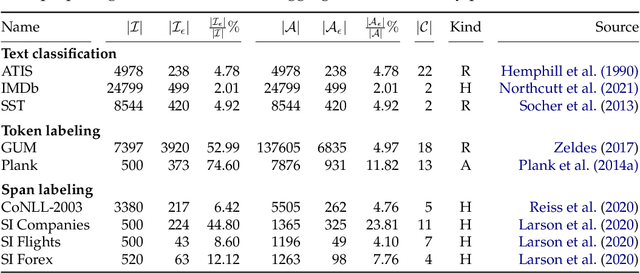
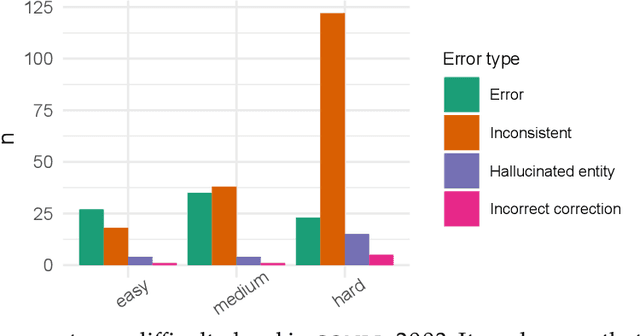
Annotated data is an essential ingredient in natural language processing for training and evaluating machine learning models. It is therefore very desirable for the annotations to be of high quality. Recent work, however, has shown that several popular datasets contain a surprising amount of annotation errors or inconsistencies. To alleviate this issue, many methods for annotation error detection have been devised over the years. While researchers show that their approaches work well on their newly introduced datasets, they rarely compare their methods to previous work or on the same datasets. This raises strong concerns on methods' general performance and makes it difficult to asses their strengths and weaknesses. We therefore reimplement 18 methods for detecting potential annotation errors and evaluate them on 9 English datasets for text classification as well as token and span labeling. In addition, we define a uniform evaluation setup including a new formalization of the annotation error detection task, evaluation protocol and general best practices. To facilitate future research and reproducibility, we release our datasets and implementations in an easy-to-use and open source software package.
Revisiting Shallow Discourse Parsing in the PDTB-3: Handling Intra-sentential Implicits
Apr 01, 2022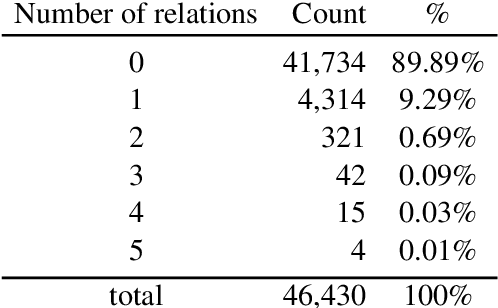
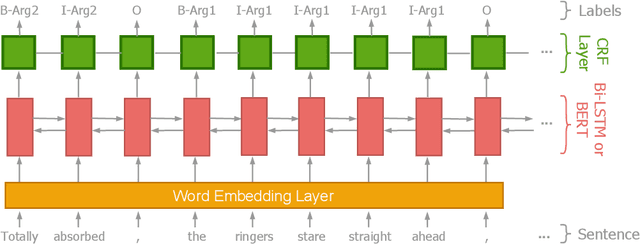
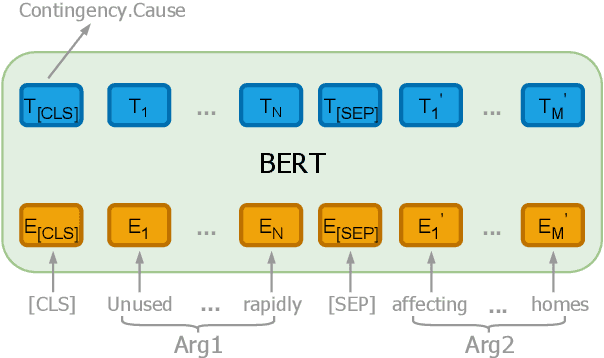
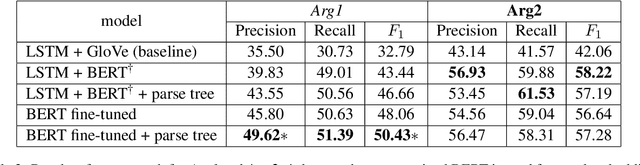
In the PDTB-3, several thousand implicit discourse relations were newly annotated \textit{within} individual sentences, adding to the over 15,000 implicit relations annotated \textit{across} adjacent sentences in the PDTB-2. Given that the position of the arguments to these \textit{intra-sentential implicits} is no longer as well-defined as with \textit{inter-sentential implicits}, a discourse parser must identify both their location and their sense. That is the focus of the current work. The paper provides a comprehensive analysis of our results, showcasing model performance under different scenarios, pointing out limitations and noting future directions.
Refocusing on Relevance: Personalization in NLG
Sep 10, 2021Many NLG tasks such as summarization, dialogue response, or open domain question answering focus primarily on a source text in order to generate a target response. This standard approach falls short, however, when a user's intent or context of work is not easily recoverable based solely on that source text -- a scenario that we argue is more of the rule than the exception. In this work, we argue that NLG systems in general should place a much higher level of emphasis on making use of additional context, and suggest that relevance (as used in Information Retrieval) be thought of as a crucial tool for designing user-oriented text-generating tasks. We further discuss possible harms and hazards around such personalization, and argue that value-sensitive design represents a crucial path forward through these challenges.
Querent Intent in Multi-Sentence Questions
Oct 18, 2020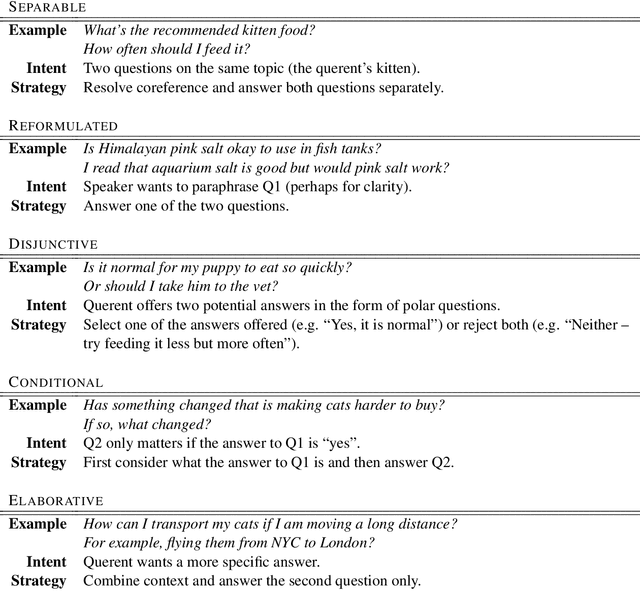
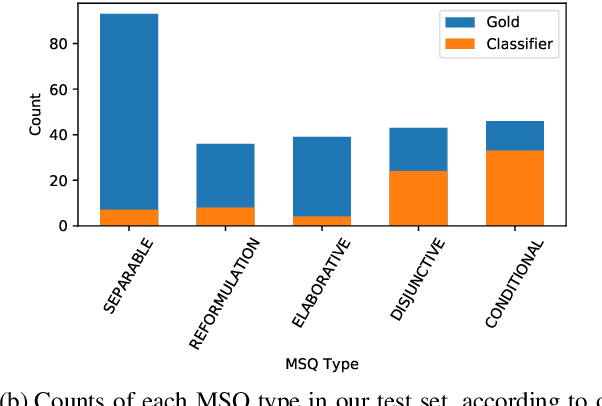

Multi-sentence questions (MSQs) are sequences of questions connected by relations which, unlike sequences of standalone questions, need to be answered as a unit. Following Rhetorical Structure Theory (RST), we recognise that different "question discourse relations" between the subparts of MSQs reflect different speaker intents, and consequently elicit different answering strategies. Correctly identifying these relations is therefore a crucial step in automatically answering MSQs. We identify five different types of MSQs in English, and define five novel relations to describe them. We extract over 162,000 MSQs from Stack Exchange to enable future research. Finally, we implement a high-precision baseline classifier based on surface features.