 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of TREC 2025 Biomedical Generative Retrieval (BioGen) Track
Mar 23, 2026Recent advances in large language models (LLMs) have made significant progress across multiple biomedical tasks, including biomedical question answering, lay-language summarization of the biomedical literature, and clinical note summarization. These models have demonstrated strong capabilities in processing and synthesizing complex biomedical information and in generating fluent, human-like responses. Despite these advancements, hallucinations or confabulations remain key challenges when using LLMs in biomedical and other high-stakes domains. Inaccuracies may be particularly harmful in high-risk situations, such as medical question answering, making clinical decisions, or appraising biomedical research. Studies on the evaluation of the LLMs' abilities to ground generated statements in verifiable sources have shown that models perform significantly
A Typology of Synthetic Datasets for Dialogue Processing in Clinical Contexts
May 05, 2025Synthetic data sets are used across linguistic domains and NLP tasks, particularly in scenarios where authentic data is limited (or even non-existent). One such domain is that of clinical (healthcare) contexts, where there exist significant and long-standing challenges (e.g., privacy, anonymization, and data governance) which have led to the development of an increasing number of synthetic datasets. One increasingly important category of clinical dataset is that of clinical dialogues which are especially sensitive and difficult to collect, and as such are commonly synthesized. While such synthetic datasets have been shown to be sufficient in some situations, little theory exists to inform how they may be best used and generalized to new applications. In this paper, we provide an overview of how synthetic datasets are created, evaluated and being used for dialogue related tasks in the medical domain. Additionally, we propose a novel typology for use in classifying types and degrees of data synthesis, to facilitate comparison and evaluation.
Overview of TREC 2024 Biomedical Generative Retrieval (BioGen) Track
Nov 27, 2024



With the advancement of large language models (LLMs), the biomedical domain has seen significant progress and improvement in multiple tasks such as biomedical question answering, lay language summarization of the biomedical literature, clinical note summarization, etc. However, hallucinations or confabulations remain one of the key challenges when using LLMs in the biomedical and other domains. Inaccuracies may be particularly harmful in high-risk situations, such as making clinical decisions or appraising biomedical research. Studies on the evaluation of the LLMs' abilities to ground generated statements in verifiable sources have shown that models perform significantly worse on lay-user generated questions, and often fail to reference relevant sources. This can be problematic when those seeking information want evidence from studies to back up the claims from LLMs[3]. Unsupported statements are a major barrier to using LLMs in any applications that may affect health. Methods for grounding generated statements in reliable sources along with practical evaluation approaches are needed to overcome this barrier. Towards this, in our pilot task organized at TREC 2024, we introduced the task of reference attribution as a means to mitigate the generation of false statements by LLMs answering biomedical questions.
Refocusing on Relevance: Personalization in NLG
Sep 10, 2021Many NLG tasks such as summarization, dialogue response, or open domain question answering focus primarily on a source text in order to generate a target response. This standard approach falls short, however, when a user's intent or context of work is not easily recoverable based solely on that source text -- a scenario that we argue is more of the rule than the exception. In this work, we argue that NLG systems in general should place a much higher level of emphasis on making use of additional context, and suggest that relevance (as used in Information Retrieval) be thought of as a crucial tool for designing user-oriented text-generating tasks. We further discuss possible harms and hazards around such personalization, and argue that value-sensitive design represents a crucial path forward through these challenges.
Searching for Scientific Evidence in a Pandemic: An Overview of TREC-COVID
Apr 19, 2021



We present an overview of the TREC-COVID Challenge, an information retrieval (IR) shared task to evaluate search on scientific literature related to COVID-19. The goals of TREC-COVID include the construction of a pandemic search test collection and the evaluation of IR methods for COVID-19. The challenge was conducted over five rounds from April to July, 2020, with participation from 92 unique teams and 556 individual submissions. A total of 50 topics (sets of related queries) were used in the evaluation, starting at 30 topics for Round 1 and adding 5 new topics per round to target emerging topics at that state of the still-emerging pandemic. This paper provides a comprehensive overview of the structure and results of TREC-COVID. Specifically, the paper provides details on the background, task structure, topic structure, corpus, participation, pooling, assessment, judgments, results, top-performing systems, lessons learned, and benchmark datasets.
Are Some Words Worth More than Others?
Oct 14, 2020
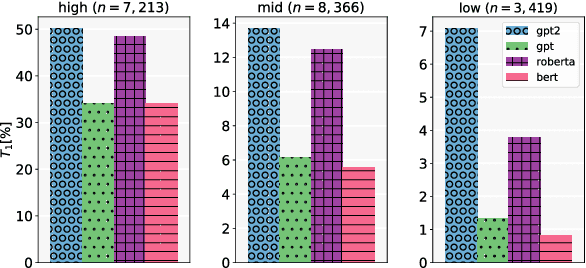
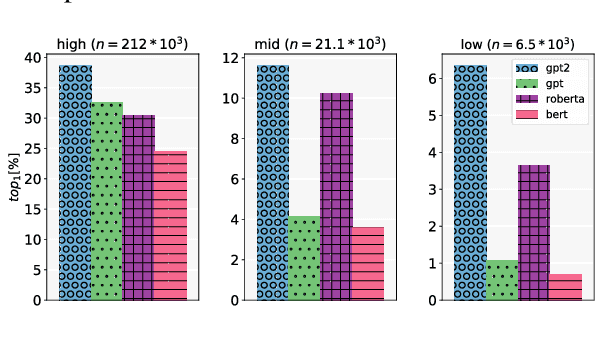

Current evaluation metrics for language modeling and generation rely heavily on the accuracy of predicted (or generated) words as compared to a reference ground truth. While important, token-level accuracy only captures one aspect of a language model's behavior, and ignores linguistic properties of words that may allow some mis-predicted tokens to be useful in practice. Furthermore, statistics directly tied to prediction accuracy (including perplexity) may be confounded by the Zipfian nature of written language, as the majority of the prediction attempts will occur with frequently-occurring types. A model's performance may vary greatly between high- and low-frequency words, which in practice could lead to failure modes such as repetitive and dull generated text being produced by a downstream consumer of a language model. To address this, we propose two new intrinsic evaluation measures within the framework of a simple word prediction task that are designed to give a more holistic picture of a language model's performance. We evaluate several commonly-used large English language models using our proposed metrics, and demonstrate that our approach reveals functional differences in performance between the models that are obscured by more traditional metrics.