 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Some Words Worth More than Others?
Paper and Code

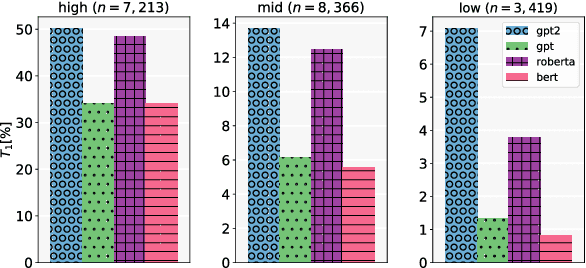
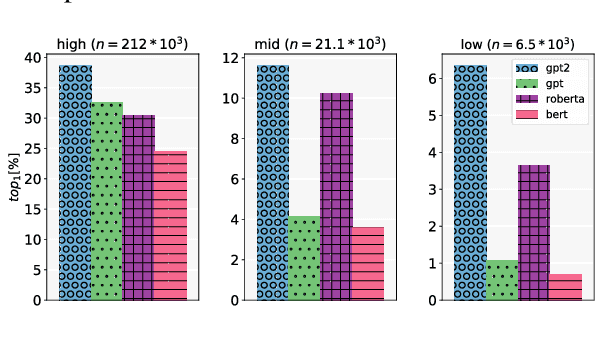

Current evaluation metrics for language modeling and generation rely heavily on the accuracy of predicted (or generated) words as compared to a reference ground truth. While important, token-level accuracy only captures one aspect of a language model's behavior, and ignores linguistic properties of words that may allow some mis-predicted tokens to be useful in practice. Furthermore, statistics directly tied to prediction accuracy (including perplexity) may be confounded by the Zipfian nature of written language, as the majority of the prediction attempts will occur with frequently-occurring types. A model's performance may vary greatly between high- and low-frequency words, which in practice could lead to failure modes such as repetitive and dull generated text being produced by a downstream consumer of a language model. To address this, we propose two new intrinsic evaluation measures within the framework of a simple word prediction task that are designed to give a more holistic picture of a language model's performance. We evaluate several commonly-used large English language models using our proposed metrics, and demonstrate that our approach reveals functional differences in performance between the models that are obscured by more traditional metrics.