 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Cultural Nuances in Emotion Perception Across 15 African Languages
Mar 25, 2025Understanding how emotions are expressed across languages is vital for building culturally-aware and inclusive NLP systems. However, emotion expression in African languages is understudied, limiting the development of effective emotion detection tools in these languages. In this work, we present a cross-linguistic analysis of emotion expression in 15 African languages. We examine four key dimensions of emotion representation: text length, sentiment polarity, emotion co-occurrence, and intensity variations. Our findings reveal diverse language-specific patterns in emotional expression -- with Somali texts typically longer, while others like IsiZulu and Algerian Arabic show more concise emotional expression. We observe a higher prevalence of negative sentiment in several Nigerian languages compared to lower negativity in languages like IsiXhosa. Further, emotion co-occurrence analysis demonstrates strong cross-linguistic associations between specific emotion pairs (anger-disgust, sadness-fear), suggesting universal psychological connections. Intensity distributions show multimodal patterns with significant variations between language families; Bantu languages display similar yet distinct profiles, while Afroasiatic languages and Nigerian Pidgin demonstrate wider intensity ranges. These findings highlight the need for language-specific approaches to emotion detection while identifying opportunities for transfer learning across related languages.
Search Plurality
Jan 02, 2025
In light of Phillips' contention regarding the impracticality of Search Neutrality, asserting that non-epistemic factors presently dictate result prioritization, our objective in this study is to confront this constraint by questioning prevailing design practices in search engines. We posit that the concept of prioritization warrants scrutiny, along with the consistent hierarchical ordering that underlies this lack of neutrality. We introduce the term Search Plurality to encapsulate the idea of emphasizing the various means a query can be approached. This is demonstrated in a design that prioritizes the display of categories over specific search items, helping users grasp the breadth of their search. Whether a query allows for multiple interpretations or invites diverse opinions, the presentation of categories highlights the significance of organizing data based on relevance, importance, and relative significance, akin to traditional methods. However, unlike previous approaches, this method enriches our comprehension of the overall information landscape, countering the potential bias introduced by ranked lists.
Analyzing Cultural Representations of Emotions in LLMs through Mixed Emotion Survey
Aug 04, 2024Large Language Models (LLMs) have gained widespread global adoption, showcasing advanced linguistic capabilities across multiple of languages. There is a growing interest in academia to use these models to simulate and study human behaviors. However, it is crucial to acknowledge that an LLM's proficiency in a specific language might not fully encapsulate the norms and values associated with its culture. Concerns have emerged regarding potential biases towards Anglo-centric cultures and values due to the predominance of Western and US-based training data. This study focuses on analyzing the cultural representations of emotions in LLMs, in the specific case of mixed-emotion situations. Our methodology is based on the studies of Miyamoto et al. (2010), which identified distinctive emotional indicators in Japanese and American human responses. We first administer their mixed emotion survey to five different LLMs and analyze their outputs. Second, we experiment with contextual variables to explore variations in responses considering both language and speaker origin. Thirdly, we expand our investigation to encompass additional East Asian and Western European origin languages to gauge their alignment with their respective cultures, anticipating a closer fit. We find that (1) models have limited alignment with the evidence in the literature; (2) written language has greater effect on LLMs' response than information on participants origin; and (3) LLMs responses were found more similar for East Asian languages than Western European languages.
Are Generative Language Models Multicultural? A Study on Hausa Culture and Emotions using ChatGPT
Jun 27, 2024



Large Language Models (LLMs), such as ChatGPT, are widely used to generate content for various purposes and audiences. However, these models may not reflect the cultural and emotional diversity of their users, especially for low-resource languages. In this paper, we investigate how ChatGPT represents Hausa's culture and emotions. We compare responses generated by ChatGPT with those provided by native Hausa speakers on 37 culturally relevant questions. We conducted experiments using emotion analysis and applied two similarity metrics to measure the alignment between human and ChatGPT responses. We also collected human participants ratings and feedback on ChatGPT responses. Our results show that ChatGPT has some level of similarity to human responses, but also exhibits some gaps and biases in its knowledge and awareness of the Hausa culture and emotions. We discuss the implications and limitations of our methodology and analysis and suggest ways to improve the performance and evaluation of LLMs for low-resource languages.
Dependency Dialogue Acts -- Annotation Scheme and Case Study
Feb 25, 2023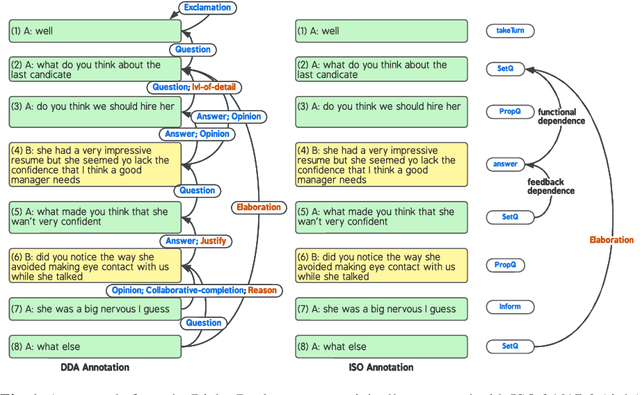

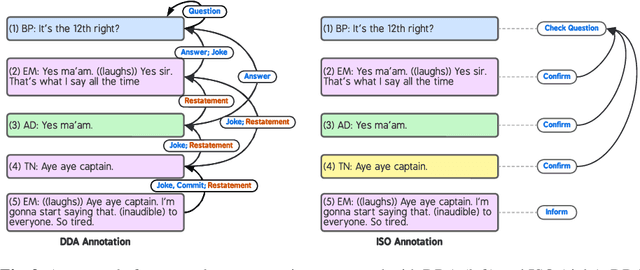
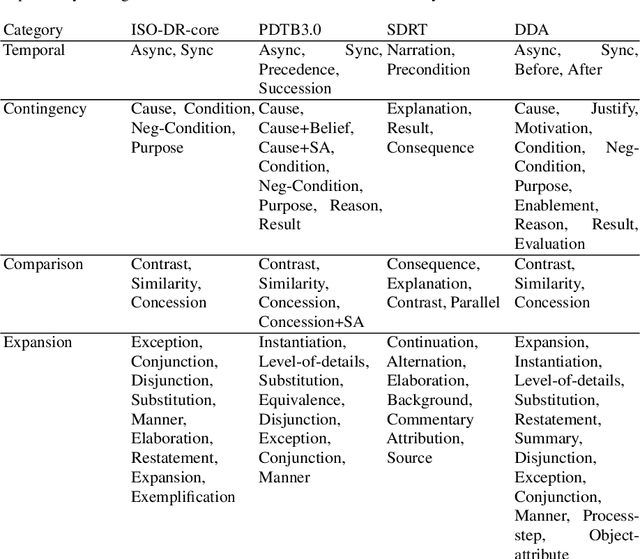
In this paper, we introduce Dependency Dialogue Acts (DDA), a novel framework for capturing the structure of speaker-intentions in multi-party dialogues. DDA combines and adapts features from existing dialogue annotation frameworks, and emphasizes the multi-relational response structure of dialogues in addition to the dialogue acts and rhetorical relations. It represents the functional, discourse, and response structure in multi-party multi-threaded conversations. A few key features distinguish DDA from existing dialogue annotation frameworks such as SWBD-DAMSL and the ISO 24617-2 standard. First, DDA prioritizes the relational structure of the dialogue units and the dialog context, annotating both dialog acts and rhetorical relations as response relations to particular utterances. Second, DDA embraces overloading in dialogues, encouraging annotators to specify multiple response relations and dialog acts for each dialog unit. Lastly, DDA places an emphasis on adequately capturing how a speaker is using the full dialog context to plan and organize their speech. With these features, DDA is highly expressive and recall-oriented with regard to conversation dynamics between multiple speakers. In what follows, we present the DDA annotation framework and case studies annotating DDA structures in multi-party, multi-threaded conversations.
* The 13th International Workshop on Spoken Dialogue Systems Technology
A Major Obstacle for NLP Research: Let's Talk about Time Allocation!
Nov 30, 2022The field of natural language processing (NLP) has grown over the last few years: conferences have become larger, we have published an incredible amount of papers, and state-of-the-art research has been implemented in a large variety of customer-facing products. However, this paper argues that we have been less successful than we should have been and reflects on where and how the field fails to tap its full potential. Specifically, we demonstrate that, in recent years, subpar time allocation has been a major obstacle for NLP research. We outline multiple concrete problems together with their negative consequences and, importantly, suggest remedies to improve the status quo. We hope that this paper will be a starting point for discussions around which common practices are -- or are not -- beneficial for NLP research.
Expansive Participatory AI: Supporting Dreaming within Inequitable Institutions
Nov 22, 2022Participatory Artificial Intelligence (PAI) has recently gained interest by researchers as means to inform the design of technology through collective's lived experience. PAI has a greater promise than that of providing useful input to developers, it can contribute to the process of democratizing the design of technology, setting the focus on what should be designed. However, in the process of PAI there existing institutional power dynamics that hinder the realization of expansive dreams and aspirations of the relevant stakeholders. In this work we propose co-design principals for AI that address institutional power dynamics focusing on Participatory AI with youth.
* 3 pages, Human-Centered AI workshop
Refocusing on Relevance: Personalization in NLG
Sep 10, 2021Many NLG tasks such as summarization, dialogue response, or open domain question answering focus primarily on a source text in order to generate a target response. This standard approach falls short, however, when a user's intent or context of work is not easily recoverable based solely on that source text -- a scenario that we argue is more of the rule than the exception. In this work, we argue that NLG systems in general should place a much higher level of emphasis on making use of additional context, and suggest that relevance (as used in Information Retrieval) be thought of as a crucial tool for designing user-oriented text-generating tasks. We further discuss possible harms and hazards around such personalization, and argue that value-sensitive design represents a crucial path forward through these challenges.
Are Some Words Worth More than Others?
Oct 14, 2020
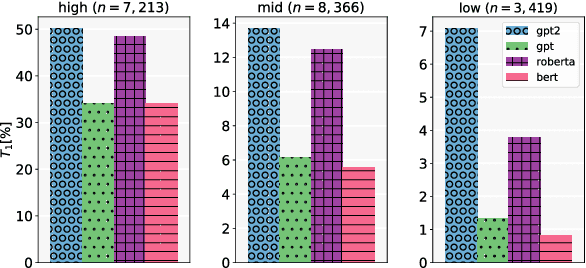
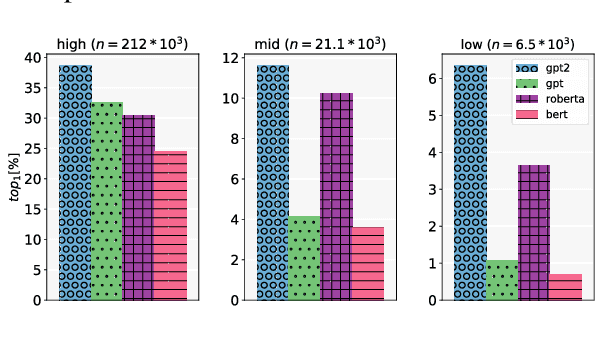

Current evaluation metrics for language modeling and generation rely heavily on the accuracy of predicted (or generated) words as compared to a reference ground truth. While important, token-level accuracy only captures one aspect of a language model's behavior, and ignores linguistic properties of words that may allow some mis-predicted tokens to be useful in practice. Furthermore, statistics directly tied to prediction accuracy (including perplexity) may be confounded by the Zipfian nature of written language, as the majority of the prediction attempts will occur with frequently-occurring types. A model's performance may vary greatly between high- and low-frequency words, which in practice could lead to failure modes such as repetitive and dull generated text being produced by a downstream consumer of a language model. To address this, we propose two new intrinsic evaluation measures within the framework of a simple word prediction task that are designed to give a more holistic picture of a language model's performance. We evaluate several commonly-used large English language models using our proposed metrics, and demonstrate that our approach reveals functional differences in performance between the models that are obscured by more traditional metrics.