 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Multimodal Paradox: How Added and Missing Modalities Shape Bias and Performance in Multimodal AI
May 05, 2025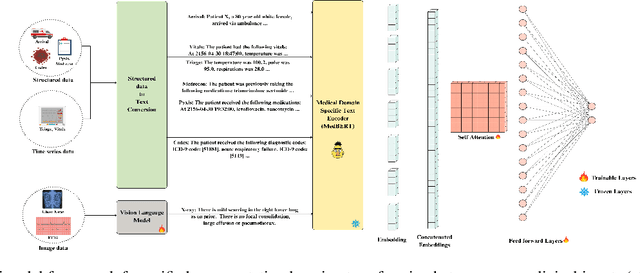



Multimodal learning, which integrates diverse data sources such as images, text, and structured data, has proven superior to unimodal counterparts in high-stakes decision-making. However, while performance gains remain the gold standard for evaluating multimodal systems, concerns around bias and robustness are frequently overlooked. In this context, this paper explores two key research questions (RQs): (i) RQ1 examines whether adding a modality con-sistently enhances performance and investigates its role in shaping fairness measures, assessing whether it mitigates or amplifies bias in multimodal models; (ii) RQ2 investigates the impact of missing modalities at inference time, analyzing how multimodal models generalize in terms of both performance and fairness. Our analysis reveals that incorporating new modalities during training consistently enhances the performance of multimodal models, while fairness trends exhibit variability across different evaluation measures and datasets. Additionally, the absence of modalities at inference degrades performance and fairness, raising concerns about its robustness in real-world deployment. We conduct extensive experiments using multimodal healthcare datasets containing images, time series, and structured information to validate our findings.
Fairness at Every Intersection: Uncovering and Mitigating Intersectional Biases in Multimodal Clinical Predictions
Nov 30, 2024



Biases in automated clinical decision-making using Electronic Healthcare Records (EHR) impose significant disparities in patient care and treatment outcomes. Conventional approaches have primarily focused on bias mitigation strategies stemming from single attributes, overlooking intersectional subgroups -- groups formed across various demographic intersections (such as race, gender, ethnicity, etc.). Rendering single-attribute mitigation strategies to intersectional subgroups becomes statistically irrelevant due to the varying distribution and bias patterns across these subgroups. The multimodal nature of EHR -- data from various sources such as combinations of text, time series, tabular, events, and images -- adds another layer of complexity as the influence on minority groups may fluctuate across modalities. In this paper, we take the initial steps to uncover potential intersectional biases in predictions by sourcing extensive multimodal datasets, MIMIC-Eye1 and MIMIC-IV ED, and propose mitigation at the intersectional subgroup level. We perform and benchmark downstream tasks and bias evaluation on the datasets by learning a unified text representation from multimodal sources, harnessing the enormous capabilities of the pre-trained clinical Language Models (LM), MedBERT, Clinical BERT, and Clinical BioBERT. Our findings indicate that the proposed sub-group-specific bias mitigation is robust across different datasets, subgroups, and embeddings, demonstrating effectiveness in addressing intersectional biases in multimodal settings.
Generating Synthetic Fair Syntax-agnostic Data by Learning and Distilling Fair Representation
Aug 20, 2024



Data Fairness is a crucial topic due to the recent wide usage of AI powered applications. Most of the real-world data is filled with human or machine biases and when those data are being used to train AI models, there is a chance that the model will reflect the bias in the training data. Existing bias-mitigating generative methods based on GANs, Diffusion models need in-processing fairness objectives and fail to consider computational overhead while choosing computationally-heavy architectures, which may lead to high computational demands, instability and poor optimization performance. To mitigate this issue, in this work, we present a fair data generation technique based on knowledge distillation, where we use a small architecture to distill the fair representation in the latent space. The idea of fair latent space distillation enables more flexible and stable training of Fair Generative Models (FGMs). We first learn a syntax-agnostic (for any data type) fair representation of the data, followed by distillation in the latent space into a smaller model. After distillation, we use the distilled fair latent space to generate high-fidelity fair synthetic data. While distilling, we employ quality loss (for fair distillation) and utility loss (for data utility) to ensure that the fairness and data utility characteristics remain in the distilled latent space. Our approaches show a 5%, 5% and 10% rise in performance in fairness, synthetic sample quality and data utility, respectively, than the state-of-the-art fair generative model.
Are Generative Language Models Multicultural? A Study on Hausa Culture and Emotions using ChatGPT
Jun 27, 2024



Large Language Models (LLMs), such as ChatGPT, are widely used to generate content for various purposes and audiences. However, these models may not reflect the cultural and emotional diversity of their users, especially for low-resource languages. In this paper, we investigate how ChatGPT represents Hausa's culture and emotions. We compare responses generated by ChatGPT with those provided by native Hausa speakers on 37 culturally relevant questions. We conducted experiments using emotion analysis and applied two similarity metrics to measure the alignment between human and ChatGPT responses. We also collected human participants ratings and feedback on ChatGPT responses. Our results show that ChatGPT has some level of similarity to human responses, but also exhibits some gaps and biases in its knowledge and awareness of the Hausa culture and emotions. We discuss the implications and limitations of our methodology and analysis and suggest ways to improve the performance and evaluation of LLMs for low-resource languages.
FairX: A comprehensive benchmarking tool for model analysis using fairness, utility, and explainability
Jun 20, 2024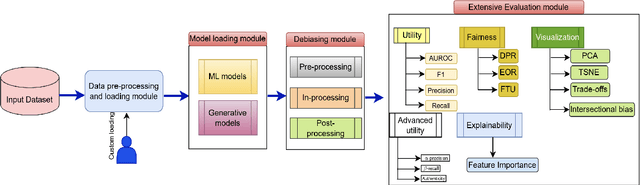

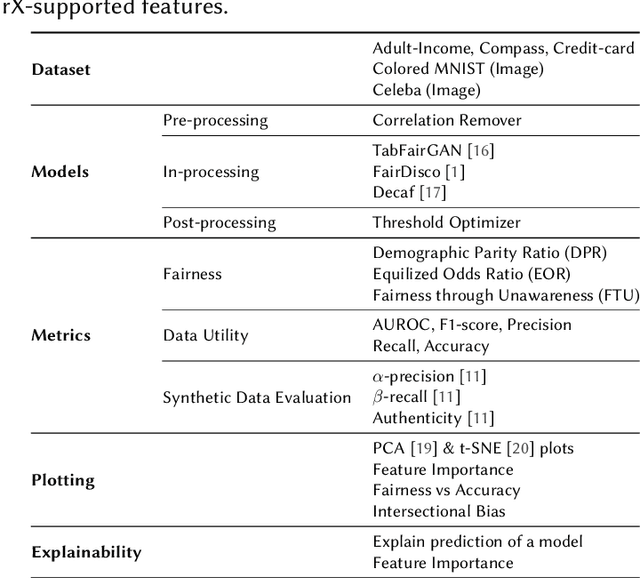
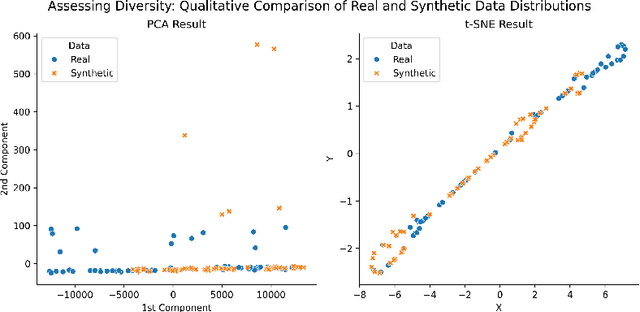
We present FairX, an open-source Python-based benchmarking tool designed for the comprehensive analysis of models under the umbrella of fairness, utility, and eXplainability (XAI). FairX enables users to train benchmarking bias-removal models and evaluate their fairness using a wide array of fairness metrics, data utility metrics, and generate explanations for model predictions, all within a unified framework. Existing benchmarking tools do not have the way to evaluate synthetic data generated from fair generative models, also they do not have the support for training fair generative models either. In FairX, we add fair generative models in the collection of our fair-model library (pre-processing, in-processing, post-processing) and evaluation metrics for evaluating the quality of synthetic fair data. This version of FairX supports both tabular and image datasets. It also allows users to provide their own custom datasets. The open-source FairX benchmarking package is publicly available at https://github.com/fahim-sikder/FairX.
Bt-GAN: Generating Fair Synthetic Healthdata via Bias-transforming Generative Adversarial Networks
Apr 26, 2024Synthetic data generation offers a promising solution to enhance the usefulness of Electronic Healthcare Records (EHR) by generating realistic de-identified data. However, the existing literature primarily focuses on the quality of synthetic health data, neglecting the crucial aspect of fairness in downstream predictions. Consequently, models trained on synthetic EHR have faced criticism for producing biased outcomes in target tasks. These biases can arise from either spurious correlations between features or the failure of models to accurately represent sub-groups. To address these concerns, we present Bias-transforming Generative Adversarial Networks (Bt-GAN), a GAN-based synthetic data generator specifically designed for the healthcare domain. In order to tackle spurious correlations (i), we propose an information-constrained Data Generation Process that enables the generator to learn a fair deterministic transformation based on a well-defined notion of algorithmic fairness. To overcome the challenge of capturing exact sub-group representations (ii), we incentivize the generator to preserve sub-group densities through score-based weighted sampling. This approach compels the generator to learn from underrepresented regions of the data manifold. We conduct extensive experiments using the MIMIC-III database. Our results demonstrate that Bt-GAN achieves SOTA accuracy while significantly improving fairness and minimizing bias amplification. We also perform an in-depth explainability analysis to provide additional evidence supporting the validity of our study. In conclusion, our research introduces a novel and professional approach to addressing the limitations of synthetic data generation in the healthcare domain. By incorporating fairness considerations and leveraging advanced techniques such as GANs, we pave the way for more reliable and unbiased predictions in healthcare applications.
TransFusion: Generating Long, High Fidelity Time Series using Diffusion Models with Transformers
Jul 24, 2023

The generation of high-quality, long-sequenced time-series data is essential due to its wide range of applications. In the past, standalone Recurrent and Convolutional Neural Network-based Generative Adversarial Networks (GAN) were used to synthesize time-series data. However, they are inadequate for generating long sequences of time-series data due to limitations in the architecture. Furthermore, GANs are well known for their training instability and mode collapse problem. To address this, we propose TransFusion, a diffusion, and transformers-based generative model to generate high-quality long-sequence time-series data. We have stretched the sequence length to 384, and generated high-quality synthetic data. To the best of our knowledge, this is the first study that has been done with this long-sequence length. Also, we introduce two evaluation metrics to evaluate the quality of the synthetic data as well as its predictive characteristics. We evaluate TransFusion with a wide variety of visual and empirical metrics, and TransFusion outperforms the previous state-of-the-art by a significant margin.