 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Multimodal Paradox: How Added and Missing Modalities Shape Bias and Performance in Multimodal AI
May 05, 2025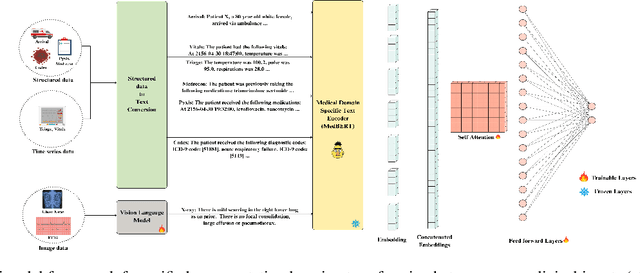



Multimodal learning, which integrates diverse data sources such as images, text, and structured data, has proven superior to unimodal counterparts in high-stakes decision-making. However, while performance gains remain the gold standard for evaluating multimodal systems, concerns around bias and robustness are frequently overlooked. In this context, this paper explores two key research questions (RQs): (i) RQ1 examines whether adding a modality con-sistently enhances performance and investigates its role in shaping fairness measures, assessing whether it mitigates or amplifies bias in multimodal models; (ii) RQ2 investigates the impact of missing modalities at inference time, analyzing how multimodal models generalize in terms of both performance and fairness. Our analysis reveals that incorporating new modalities during training consistently enhances the performance of multimodal models, while fairness trends exhibit variability across different evaluation measures and datasets. Additionally, the absence of modalities at inference degrades performance and fairness, raising concerns about its robustness in real-world deployment. We conduct extensive experiments using multimodal healthcare datasets containing images, time series, and structured information to validate our findings.
Fairness at Every Intersection: Uncovering and Mitigating Intersectional Biases in Multimodal Clinical Predictions
Nov 30, 2024



Biases in automated clinical decision-making using Electronic Healthcare Records (EHR) impose significant disparities in patient care and treatment outcomes. Conventional approaches have primarily focused on bias mitigation strategies stemming from single attributes, overlooking intersectional subgroups -- groups formed across various demographic intersections (such as race, gender, ethnicity, etc.). Rendering single-attribute mitigation strategies to intersectional subgroups becomes statistically irrelevant due to the varying distribution and bias patterns across these subgroups. The multimodal nature of EHR -- data from various sources such as combinations of text, time series, tabular, events, and images -- adds another layer of complexity as the influence on minority groups may fluctuate across modalities. In this paper, we take the initial steps to uncover potential intersectional biases in predictions by sourcing extensive multimodal datasets, MIMIC-Eye1 and MIMIC-IV ED, and propose mitigation at the intersectional subgroup level. We perform and benchmark downstream tasks and bias evaluation on the datasets by learning a unified text representation from multimodal sources, harnessing the enormous capabilities of the pre-trained clinical Language Models (LM), MedBERT, Clinical BERT, and Clinical BioBERT. Our findings indicate that the proposed sub-group-specific bias mitigation is robust across different datasets, subgroups, and embeddings, demonstrating effectiveness in addressing intersectional biases in multimodal settings.