 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHausaNLP: Current Status, Challenges and Future Directions for Hausa Natural Language Processing
May 20, 2025Hausa Natural Language Processing (NLP) has gained increasing attention in recent years, yet remains understudied as a low-resource language despite having over 120 million first-language (L1) and 80 million second-language (L2) speakers worldwide. While significant advances have been made in high-resource languages, Hausa NLP faces persistent challenges, including limited open-source datasets and inadequate model representation. This paper presents an overview of the current state of Hausa NLP, systematically examining existing resources, research contributions, and gaps across fundamental NLP tasks: text classification, machine translation, named entity recognition, speech recognition, and question answering. We introduce HausaNLP (https://catalog.hausanlp.org), a curated catalog that aggregates datasets, tools, and research works to enhance accessibility and drive further development. Furthermore, we discuss challenges in integrating Hausa into large language models (LLMs), addressing issues of suboptimal tokenization and dialectal variation. Finally, we propose strategic research directions emphasizing dataset expansion, improved language modeling approaches, and strengthened community collaboration to advance Hausa NLP. Our work provides both a foundation for accelerating Hausa NLP progress and valuable insights for broader multilingual NLP research.
Exploring Cultural Nuances in Emotion Perception Across 15 African Languages
Mar 25, 2025Understanding how emotions are expressed across languages is vital for building culturally-aware and inclusive NLP systems. However, emotion expression in African languages is understudied, limiting the development of effective emotion detection tools in these languages. In this work, we present a cross-linguistic analysis of emotion expression in 15 African languages. We examine four key dimensions of emotion representation: text length, sentiment polarity, emotion co-occurrence, and intensity variations. Our findings reveal diverse language-specific patterns in emotional expression -- with Somali texts typically longer, while others like IsiZulu and Algerian Arabic show more concise emotional expression. We observe a higher prevalence of negative sentiment in several Nigerian languages compared to lower negativity in languages like IsiXhosa. Further, emotion co-occurrence analysis demonstrates strong cross-linguistic associations between specific emotion pairs (anger-disgust, sadness-fear), suggesting universal psychological connections. Intensity distributions show multimodal patterns with significant variations between language families; Bantu languages display similar yet distinct profiles, while Afroasiatic languages and Nigerian Pidgin demonstrate wider intensity ranges. These findings highlight the need for language-specific approaches to emotion detection while identifying opportunities for transfer learning across related languages.
Comparable Corpora: Opportunities for New Research Directions
Jan 24, 2025



Most conference papers present new results, but this paper will focus more on opportunities for the audience to make their own contributions. This paper is intended to challenge the community to think more broadly about what we can do with comparable corpora. We will start with a review of the history, and then suggest new directions for future research. This was a keynote at BUCC-2025, a workshop associated with Coling-2025.
Is Peer-Reviewing Worth the Effort?
Dec 18, 2024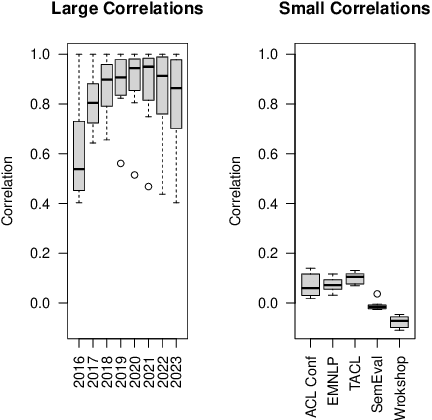
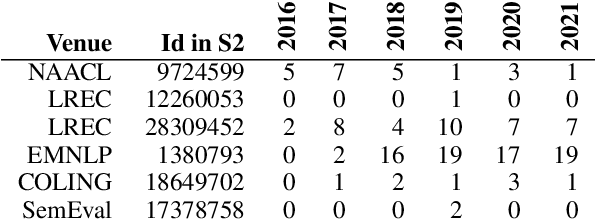
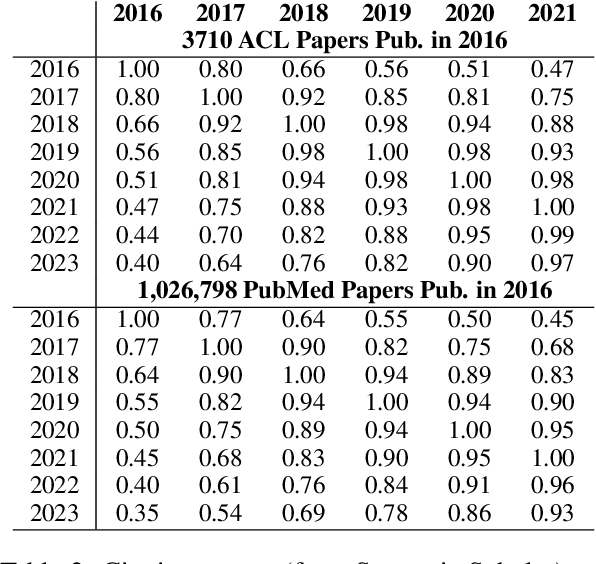
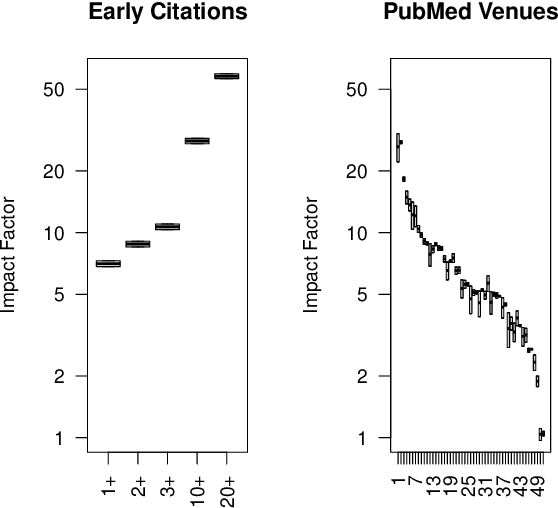
How effective is peer-reviewing in identifying important papers? We treat this question as a forecasting task. Can we predict which papers will be highly cited in the future based on venue and "early returns" (citations soon after publication)? We show early returns are more predictive than venue. Finally, we end with constructive suggestions to address scaling challenges: (a) too many submissions and (b) too few qualified reviewers.
Academic Article Recommendation Using Multiple Perspectives
Jul 08, 2024



We argue that Content-based filtering (CBF) and Graph-based methods (GB) complement one another in Academic Search recommendations. The scientific literature can be viewed as a conversation between authors and the audience. CBF uses abstracts to infer authors' positions, and GB uses citations to infer responses from the audience. In this paper, we describe nine differences between CBF and GB, as well as synergistic opportunities for hybrid combinations. Two embeddings will be used to illustrate these opportunities: (1) Specter, a CBF method based on BERT-like deepnet encodings of abstracts, and (2) ProNE, a GB method based on spectral clustering of more than 200M papers and 2B citations from Semantic Scholar.
Are Generative Language Models Multicultural? A Study on Hausa Culture and Emotions using ChatGPT
Jun 27, 2024



Large Language Models (LLMs), such as ChatGPT, are widely used to generate content for various purposes and audiences. However, these models may not reflect the cultural and emotional diversity of their users, especially for low-resource languages. In this paper, we investigate how ChatGPT represents Hausa's culture and emotions. We compare responses generated by ChatGPT with those provided by native Hausa speakers on 37 culturally relevant questions. We conducted experiments using emotion analysis and applied two similarity metrics to measure the alignment between human and ChatGPT responses. We also collected human participants ratings and feedback on ChatGPT responses. Our results show that ChatGPT has some level of similarity to human responses, but also exhibits some gaps and biases in its knowledge and awareness of the Hausa culture and emotions. We discuss the implications and limitations of our methodology and analysis and suggest ways to improve the performance and evaluation of LLMs for low-resource languages.
Since the Scientific Literature Is Multilingual, Our Models Should Be Too
Mar 27, 2024



English has long been assumed the $\textit{lingua franca}$ of scientific research, and this notion is reflected in the natural language processing (NLP) research involving scientific document representation. In this position piece, we quantitatively show that the literature is largely multilingual and argue that current models and benchmarks should reflect this linguistic diversity. We provide evidence that text-based models fail to create meaningful representations for non-English papers and highlight the negative user-facing impacts of using English-only models non-discriminately across a multilingual domain. We end with suggestions for the NLP community on how to improve performance on non-English documents.
Data-Driven Adaptive Simultaneous Machine Translation
Apr 27, 2022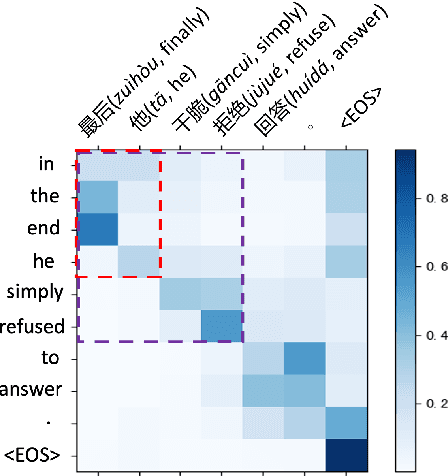
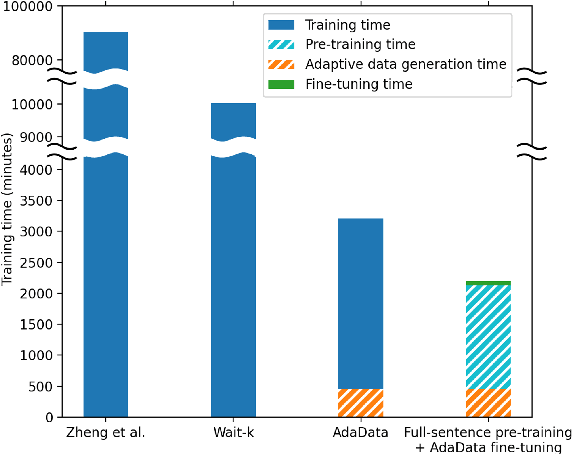
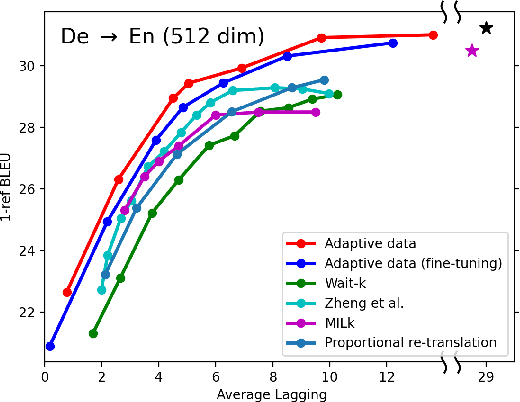
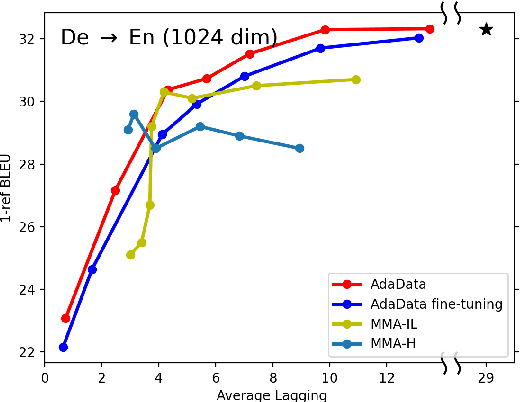
In simultaneous translation (SimulMT), the most widely used strategy is the wait-k policy thanks to its simplicity and effectiveness in balancing translation quality and latency. However, wait-k suffers from two major limitations: (a) it is a fixed policy that can not adaptively adjust latency given context, and (b) its training is much slower than full-sentence translation. To alleviate these issues, we propose a novel and efficient training scheme for adaptive SimulMT by augmenting the training corpus with adaptive prefix-to-prefix pairs, while the training complexity remains the same as that of training full-sentence translation models. Experiments on two language pairs show that our method outperforms all strong baselines in terms of translation quality and latency.
Efficiently Disentangle Causal Representations
Jan 06, 2022

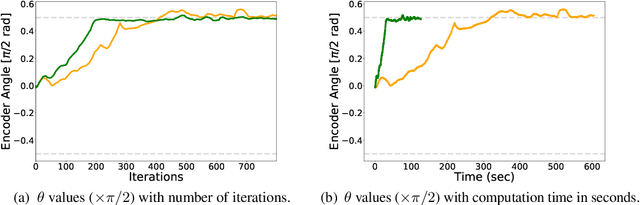

This paper proposes an efficient approach to learning disentangled representations with causal mechanisms based on the difference of conditional probabilities in original and new distributions. We approximate the difference with models' generalization abilities so that it fits in the standard machine learning framework and can be efficiently computed. In contrast to the state-of-the-art approach, which relies on the learner's adaptation speed to new distribution, the proposed approach only requires evaluating the model's generalization ability. We provide a theoretical explanation for the advantage of the proposed method, and our experiments show that the proposed technique is 1.9--11.0$\times$ more sample efficient and 9.4--32.4 times quicker than the previous method on various tasks. The source code is available at \url{https://github.com/yuanpeng16/EDCR}.
Exploiting a Zoo of Checkpoints for Unseen Tasks
Nov 05, 2021
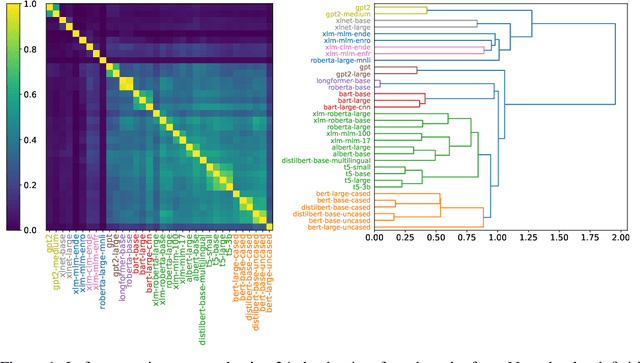
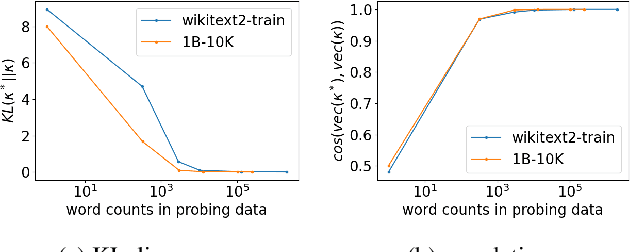

There are so many models in the literature that it is difficult for practitioners to decide which combinations are likely to be effective for a new task. This paper attempts to address this question by capturing relationships among checkpoints published on the web. We model the space of tasks as a Gaussian process. The covariance can be estimated from checkpoints and unlabeled probing data. With the Gaussian process, we can identify representative checkpoints by a maximum mutual information criterion. This objective is submodular. A greedy method identifies representatives that are likely to "cover" the task space. These representatives generalize to new tasks with superior performance. Empirical evidence is provided for applications from both computational linguistics as well as computer vision.