 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcademic Article Recommendation Using Multiple Perspectives
Jul 08, 2024



We argue that Content-based filtering (CBF) and Graph-based methods (GB) complement one another in Academic Search recommendations. The scientific literature can be viewed as a conversation between authors and the audience. CBF uses abstracts to infer authors' positions, and GB uses citations to infer responses from the audience. In this paper, we describe nine differences between CBF and GB, as well as synergistic opportunities for hybrid combinations. Two embeddings will be used to illustrate these opportunities: (1) Specter, a CBF method based on BERT-like deepnet encodings of abstracts, and (2) ProNE, a GB method based on spectral clustering of more than 200M papers and 2B citations from Semantic Scholar.
Since the Scientific Literature Is Multilingual, Our Models Should Be Too
Mar 27, 2024



English has long been assumed the $\textit{lingua franca}$ of scientific research, and this notion is reflected in the natural language processing (NLP) research involving scientific document representation. In this position piece, we quantitatively show that the literature is largely multilingual and argue that current models and benchmarks should reflect this linguistic diversity. We provide evidence that text-based models fail to create meaningful representations for non-English papers and highlight the negative user-facing impacts of using English-only models non-discriminately across a multilingual domain. We end with suggestions for the NLP community on how to improve performance on non-English documents.
Meeting the Needs of Low-Resource Languages: The Value of Automatic Alignments via Pretrained Models
Feb 15, 2023Large multilingual models have inspired a new class of word alignment methods, which work well for the model's pretraining languages. However, the languages most in need of automatic alignment are low-resource and, thus, not typically included in the pretraining data. In this work, we ask: How do modern aligners perform on unseen languages, and are they better than traditional methods? We contribute gold-standard alignments for Bribri--Spanish, Guarani--Spanish, Quechua--Spanish, and Shipibo-Konibo--Spanish. With these, we evaluate state-of-the-art aligners with and without model adaptation to the target language. Finally, we also evaluate the resulting alignments extrinsically through two downstream tasks: named entity recognition and part-of-speech tagging. We find that although transformer-based methods generally outperform traditional models, the two classes of approach remain competitive with each other.
How to Adapt Your Pretrained Multilingual Model to 1600 Languages
Jun 03, 2021
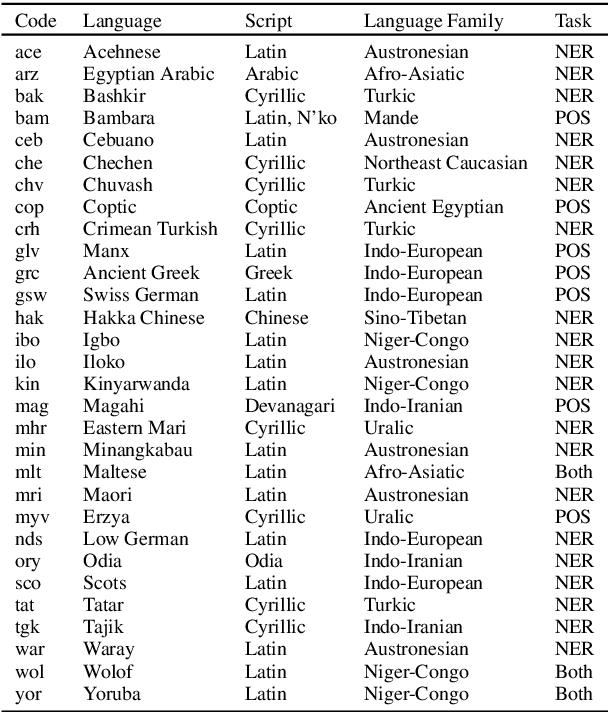

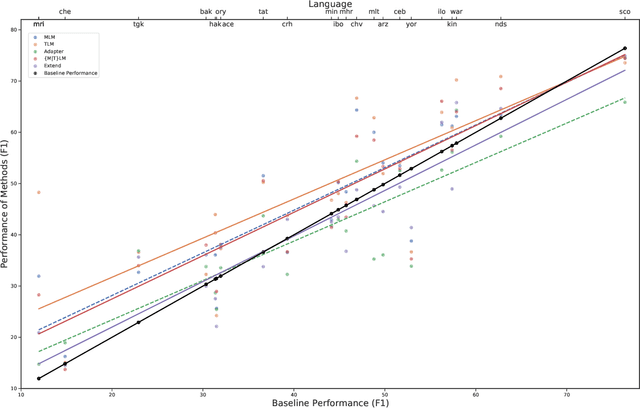
Pretrained multilingual models (PMMs) enable zero-shot learning via cross-lingual transfer, performing best for languages seen during pretraining. While methods exist to improve performance for unseen languages, they have almost exclusively been evaluated using amounts of raw text only available for a small fraction of the world's languages. In this paper, we evaluate the performance of existing methods to adapt PMMs to new languages using a resource available for over 1600 languages: the New Testament. This is challenging for two reasons: (1) the small corpus size, and (2) the narrow domain. While performance drops for all approaches, we surprisingly still see gains of up to $17.69\%$ accuracy for part-of-speech tagging and $6.29$ F1 for NER on average over all languages as compared to XLM-R. Another unexpected finding is that continued pretraining, the simplest approach, performs best. Finally, we perform a case study to disentangle the effects of domain and size and to shed light on the influence of the finetuning source language.
AmericasNLI: Evaluating Zero-shot Natural Language Understanding of Pretrained Multilingual Models in Truly Low-resource Languages
Apr 18, 2021
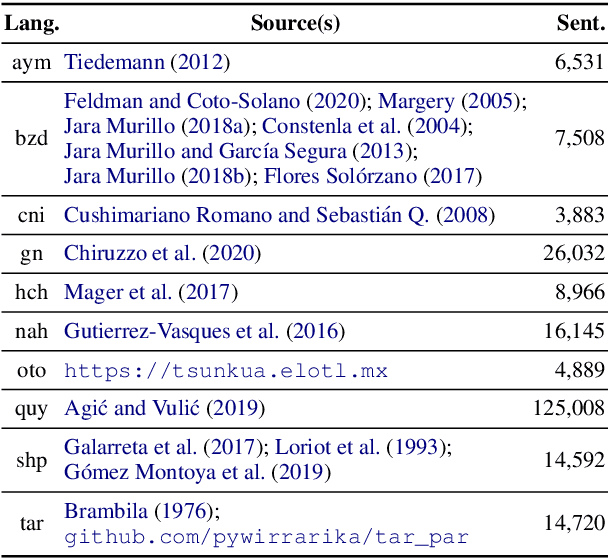
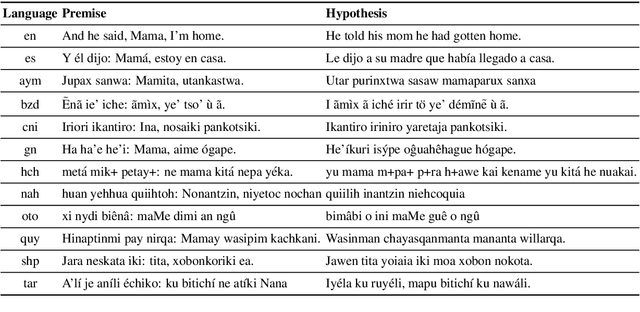

Pretrained multilingual models are able to perform cross-lingual transfer in a zero-shot setting, even for languages unseen during pretraining. However, prior work evaluating performance on unseen languages has largely been limited to low-level, syntactic tasks, and it remains unclear if zero-shot learning of high-level, semantic tasks is possible for unseen languages. To explore this question, we present AmericasNLI, an extension of XNLI (Conneau et al., 2018) to 10 indigenous languages of the Americas. We conduct experiments with XLM-R, testing multiple zero-shot and translation-based approaches. Additionally, we explore model adaptation via continued pretraining and provide an analysis of the dataset by considering hypothesis-only models. We find that XLM-R's zero-shot performance is poor for all 10 languages, with an average performance of 38.62%. Continued pretraining offers improvements, with an average accuracy of 44.05%. Surprisingly, training on poorly translated data by far outperforms all other methods with an accuracy of 48.72%.
Athena: Constructing Dialogues Dynamically with Discourse Constraints
Nov 21, 2020
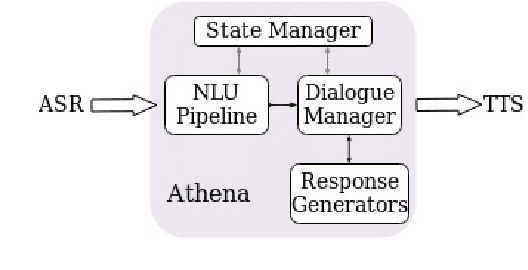

This report describes Athena, a dialogue system for spoken conversation on popular topics and current events. We develop a flexible topic-agnostic approach to dialogue management that dynamically configures dialogue based on general principles of entity and topic coherence. Athena's dialogue manager uses a contract-based method where discourse constraints are dispatched to clusters of response generators. This allows Athena to procure responses from dynamic sources, such as knowledge graph traversals and feature-based on-the-fly response retrieval methods. After describing the dialogue system architecture, we perform an analysis of conversations that Athena participated in during the 2019 Alexa Prize Competition. We conclude with a report on several user studies we carried out to better understand how individual user characteristics affect system ratings.
Curate and Generate: A Corpus and Method for Joint Control of Semantics and Style in Neural NLG
Jun 14, 2019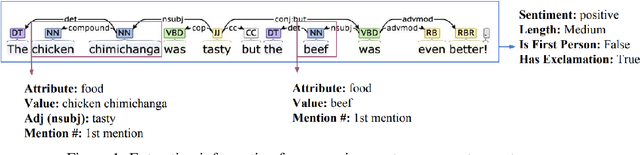


Neural natural language generation (NNLG) from structured meaning representations has become increasingly popular in recent years. While we have seen progress with generating syntactically correct utterances that preserve semantics, various shortcomings of NNLG systems are clear: new tasks require new training data which is not available or straightforward to acquire, and model outputs are simple and may be dull and repetitive. This paper addresses these two critical challenges in NNLG by: (1) scalably (and at no cost) creating training datasets of parallel meaning representations and reference texts with rich style markup by using data from freely available and naturally descriptive user reviews, and (2) systematically exploring how the style markup enables joint control of semantic and stylistic aspects of neural model output. We present YelpNLG, a corpus of 300,000 rich, parallel meaning representations and highly stylistically varied reference texts spanning different restaurant attributes, and describe a novel methodology that can be scalably reused to generate NLG datasets for other domains. The experiments show that the models control important aspects, including lexical choice of adjectives, output length, and sentiment, allowing the models to successfully hit multiple style targets without sacrificing semantics.