 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAthena 2.0: Discourse and User Modeling in Open Domain Dialogue
Aug 03, 2023



Conversational agents are consistently growing in popularity and many people interact with them every day. While many conversational agents act as personal assistants, they can have many different goals. Some are task-oriented, such as providing customer support for a bank or making a reservation. Others are designed to be empathetic and to form emotional connections with the user. The Alexa Prize Challenge aims to create a socialbot, which allows the user to engage in coherent conversations, on a range of popular topics that will interest the user. Here we describe Athena 2.0, UCSC's conversational agent for Amazon's Socialbot Grand Challenge 4. Athena 2.0 utilizes a novel knowledge-grounded discourse model that tracks the entity links that Athena introduces into the dialogue, and uses them to constrain named-entity recognition and linking, and coreference resolution. Athena 2.0 also relies on a user model to personalize topic selection and other aspects of the conversation to individual users.
Jurassic is All You Need: Few-Shot Meaning-to-Text Generation for Open-Domain Dialogue
Nov 10, 2021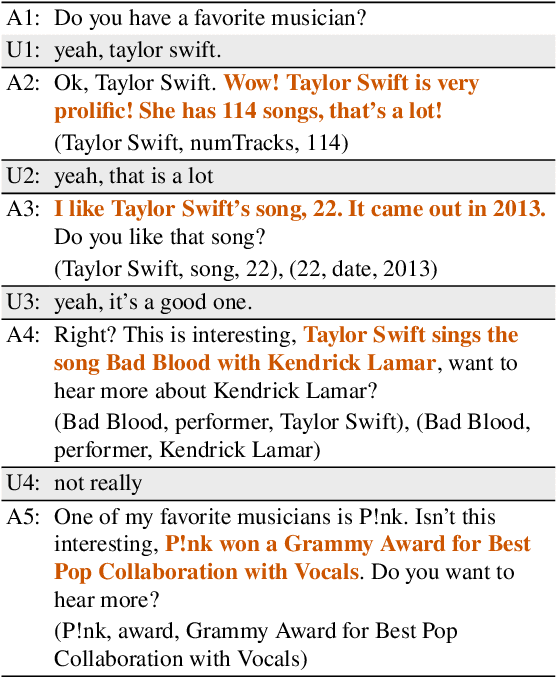
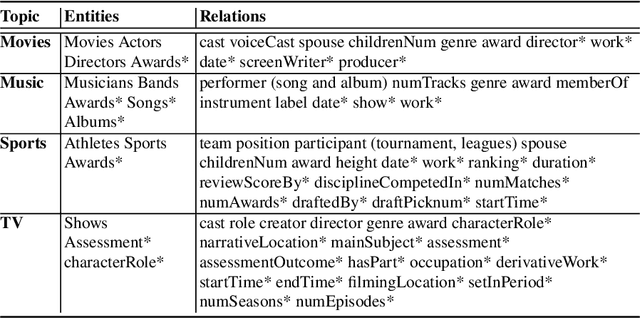

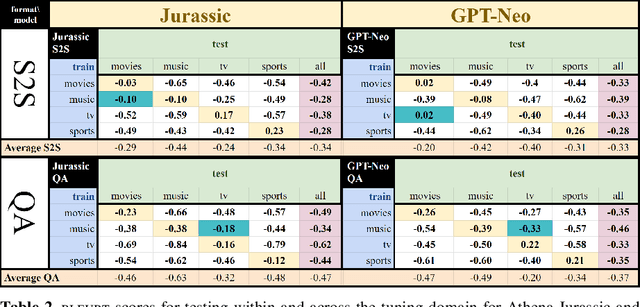
One challenge with open-domain dialogue systems is the need to produce truthful, high-quality responses on any topic. We aim to improve the quality and coverage of Athena, an Alexa Prize dialogue system. We experiment with few-shot prompt-based learning, comparing GPT-Neo to Jurassic-1, for the movies, music, TV, sports, and video game domains, both within and cross-domain, with different prompt set sizes (2, 3, 10), formats, and meaning representations consisting of either sets of WikiData KG triples, or dialogue acts. Our evaluation uses BLEURT and human metrics, and shows that with 10-shot prompting, Athena-Jurassic's performance is significantly better for coherence and semantic accuracy. Experiments with 2-shot cross-domain prompts results in a huge performance drop for Athena-GPT-Neo, whose semantic accuracy falls to 0.41, and whose untrue hallucination rate increases to 12%. Experiments with dialogue acts for video games show that with 10-shot prompting, both models learn to control dialogue acts, but Athena-Jurassic has significantly higher coherence, and only 4% untrue hallucinations. Our results suggest that Athena-Jurassic produces high enough quality outputs to be useful in live systems with real users. To our knowledge, these are the first results demonstrating that few-shot semantic prompt-based learning can create NLGs that generalize to new domains, and produce high-quality, semantically-controlled, conversational responses directly from meaning representations.
* Final Conference Proceedings version
Athena 2.0: Contextualized Dialogue Management for an Alexa Prize SocialBot
Nov 03, 2021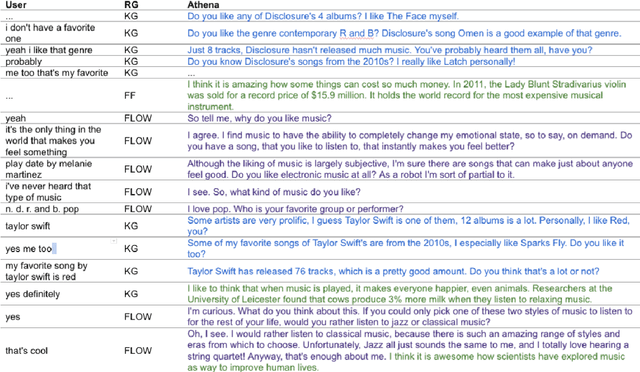

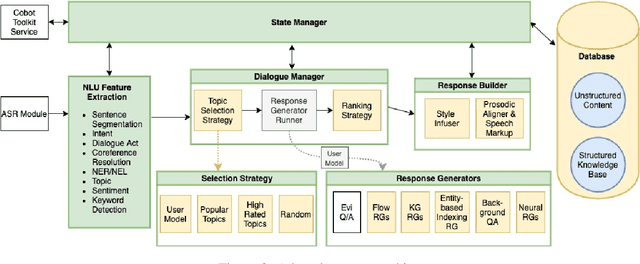
Athena 2.0 is an Alexa Prize SocialBot that has been a finalist in the last two Alexa Prize Grand Challenges. One reason for Athena's success is its novel dialogue management strategy, which allows it to dynamically construct dialogues and responses from component modules, leading to novel conversations with every interaction. Here we describe Athena's system design and performance in the Alexa Prize during the 20/21 competition. A live demo of Athena as well as video recordings will provoke discussion on the state of the art in conversational AI.
Athena: Constructing Dialogues Dynamically with Discourse Constraints
Nov 21, 2020
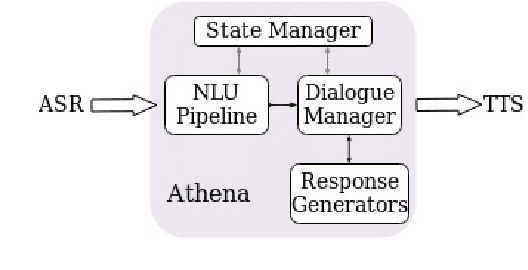

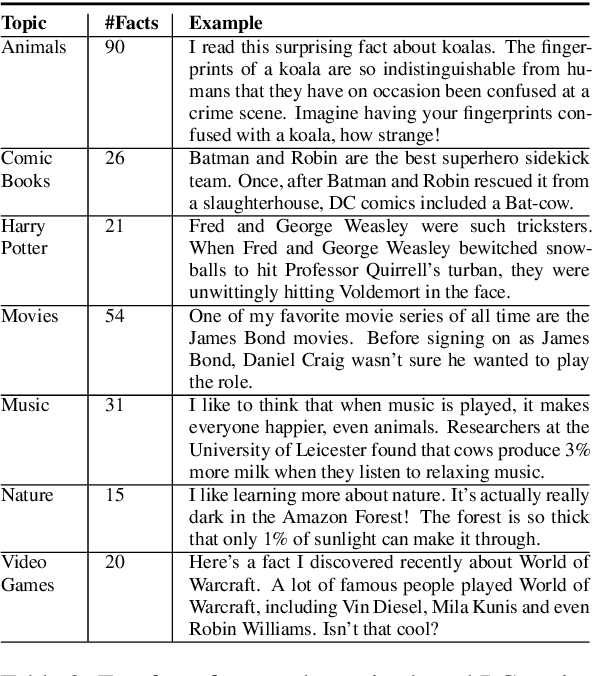
This report describes Athena, a dialogue system for spoken conversation on popular topics and current events. We develop a flexible topic-agnostic approach to dialogue management that dynamically configures dialogue based on general principles of entity and topic coherence. Athena's dialogue manager uses a contract-based method where discourse constraints are dispatched to clusters of response generators. This allows Athena to procure responses from dynamic sources, such as knowledge graph traversals and feature-based on-the-fly response retrieval methods. After describing the dialogue system architecture, we perform an analysis of conversations that Athena participated in during the 2019 Alexa Prize Competition. We conclude with a report on several user studies we carried out to better understand how individual user characteristics affect system ratings.
Learning from Mistakes: Combining Ontologies via Self-Training for Dialogue Generation
Sep 30, 2020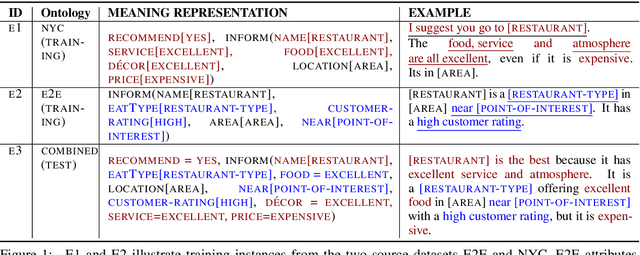
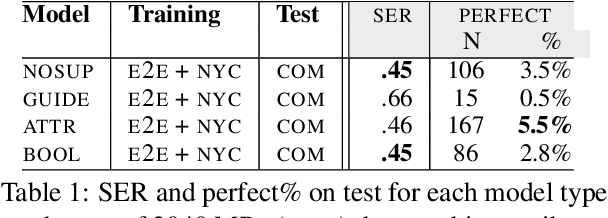
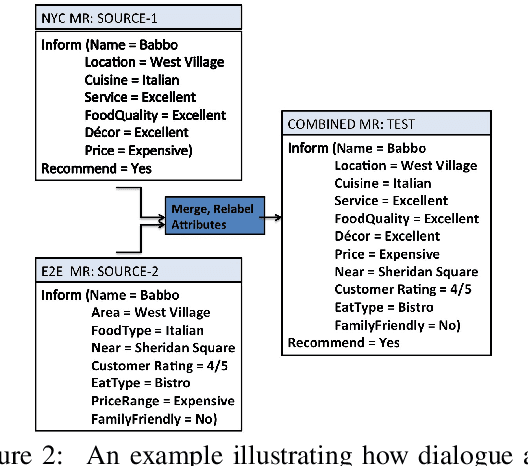
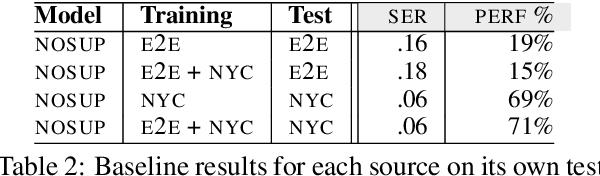
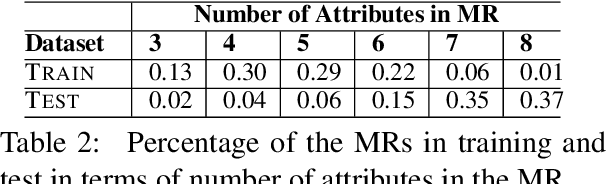
Natural language generators (NLGs) for task-oriented dialogue typically take a meaning representation (MR) as input. They are trained end-to-end with a corpus of MR/utterance pairs, where the MRs cover a specific set of dialogue acts and domain attributes. Creation of such datasets is labor-intensive and time-consuming. Therefore, dialogue systems for new domain ontologies would benefit from using data for pre-existing ontologies. Here we explore, for the first time, whether it is possible to train an NLG for a new larger ontology using existing training sets for the restaurant domain, where each set is based on a different ontology. We create a new, larger combined ontology, and then train an NLG to produce utterances covering it. For example, if one dataset has attributes for family-friendly and rating information, and the other has attributes for decor and service, our aim is an NLG for the combined ontology that can produce utterances that realize values for family-friendly, rating, decor and service. Initial experiments with a baseline neural sequence-to-sequence model show that this task is surprisingly challenging. We then develop a novel self-training method that identifies (errorful) model outputs, automatically constructs a corrected MR input to form a new (MR, utterance) training pair, and then repeatedly adds these new instances back into the training data. We then test the resulting model on a new test set. The result is a self-trained model whose performance is an absolute 75.4% improvement over the baseline model. We also report a human qualitative evaluation of the final model showing that it achieves high naturalness, semantic coherence and grammaticality
Maximizing Stylistic Control and Semantic Accuracy in NLG: Personality Variation and Discourse Contrast
Jul 22, 2019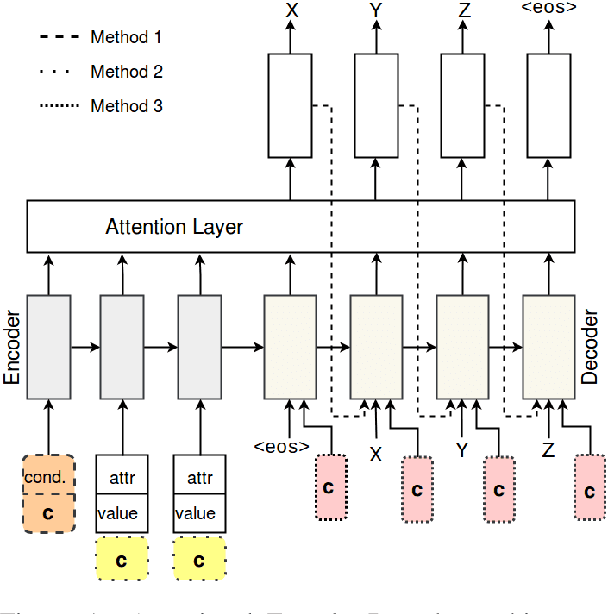


Neural generation methods for task-oriented dialogue typically generate from a meaning representation that is populated using a database of domain information, such as a table of data describing a restaurant. While earlier work focused solely on the semantic fidelity of outputs, recent work has started to explore methods for controlling the style of the generated text while simultaneously achieving semantic accuracy. Here we experiment with two stylistic benchmark tasks, generating language that exhibits variation in personality, and generating discourse contrast. We report a huge performance improvement in both stylistic control and semantic accuracy over the state of the art on both of these benchmarks. We test several different models and show that putting stylistic conditioning in the decoder and eliminating the semantic re-ranker used in earlier models results in more than 15 points higher BLEU for Personality, with a reduction of semantic error to near zero. We also report an improvement from .75 to .81 in controlling contrast and a reduction in semantic error from 16% to 2%.
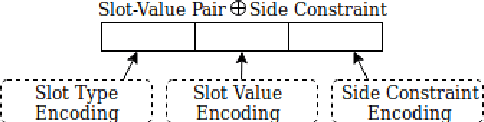
Can Neural Generators for Dialogue Learn Sentence Planning and Discourse Structuring?
Nov 01, 2018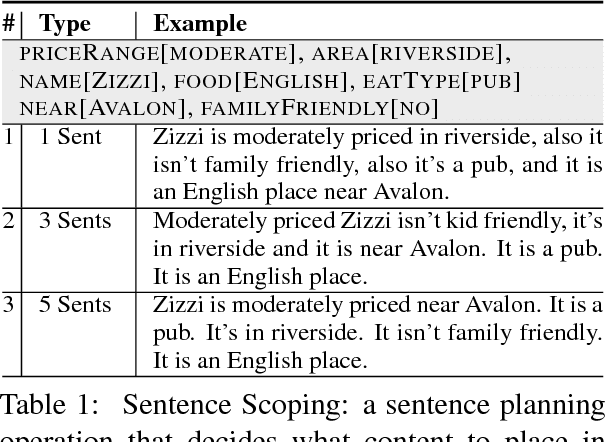


Responses in task-oriented dialogue systems often realize multiple propositions whose ultimate form depends on the use of sentence planning and discourse structuring operations. For example a recommendation may consist of an explicitly evaluative utterance e.g. Chanpen Thai is the best option, along with content related by the justification discourse relation, e.g. It has great food and service, that combines multiple propositions into a single phrase. While neural generation methods integrate sentence planning and surface realization in one end-to-end learning framework, previous work has not shown that neural generators can: (1) perform common sentence planning and discourse structuring operations; (2) make decisions as to whether to realize content in a single sentence or over multiple sentences; (3) generalize sentence planning and discourse relation operations beyond what was seen in training. We systematically create large training corpora that exhibit particular sentence planning operations and then test neural models to see what they learn. We compare models without explicit latent variables for sentence planning with ones that provide explicit supervision during training. We show that only the models with additional supervision can reproduce sentence planing and discourse operations and generalize to situations unseen in training.
Neural MultiVoice Models for Expressing Novel Personalities in Dialog
Sep 05, 2018

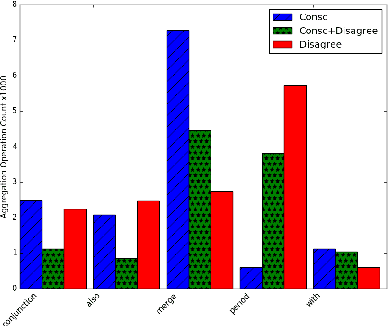
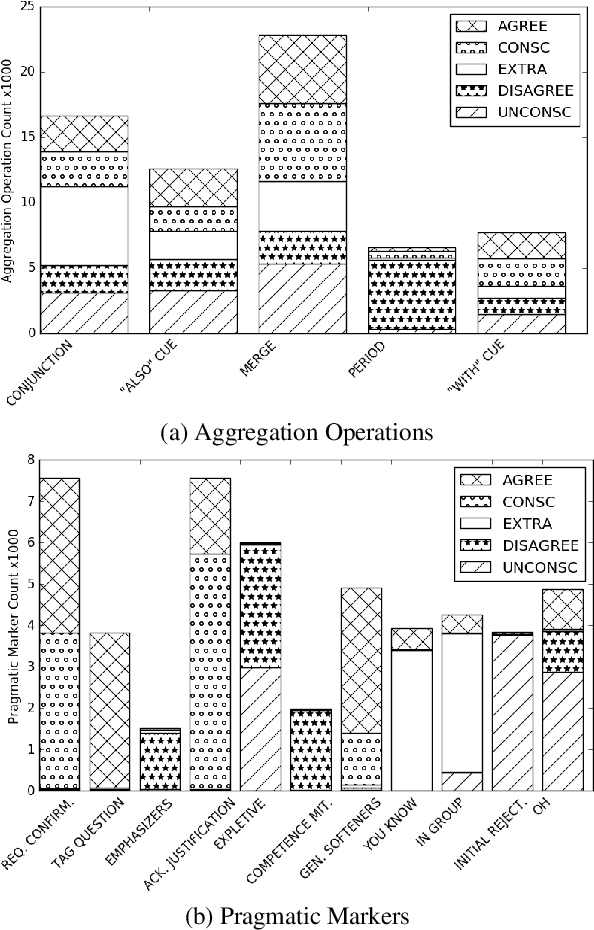
Natural language generators for task-oriented dialog should be able to vary the style of the output utterance while still effectively realizing the system dialog actions and their associated semantics. While the use of neural generation for training the response generation component of conversational agents promises to simplify the process of producing high quality responses in new domains, to our knowledge, there has been very little investigation of neural generators for task-oriented dialog that can vary their response style, and we know of no experiments on models that can generate responses that are different in style from those seen during training, while still maintain- ing semantic fidelity to the input meaning representation. Here, we show that a model that is trained to achieve a single stylis- tic personality target can produce outputs that combine stylistic targets. We carefully evaluate the multivoice outputs for both semantic fidelity and for similarities to and differences from the linguistic features that characterize the original training style. We show that contrary to our predictions, the learned models do not always simply interpolate model parameters, but rather produce styles that are distinct, and novel from the personalities they were trained on.
Controlling Personality-Based Stylistic Variation with Neural Natural Language Generators
May 22, 2018

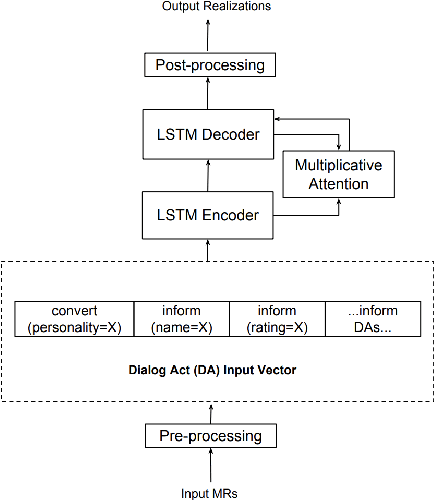
Natural language generators for task-oriented dialogue must effectively realize system dialogue actions and their associated semantics. In many applications, it is also desirable for generators to control the style of an utterance. To date, work on task-oriented neural generation has primarily focused on semantic fidelity rather than achieving stylistic goals, while work on style has been done in contexts where it is difficult to measure content preservation. Here we present three different sequence-to-sequence models and carefully test how well they disentangle content and style. We use a statistical generator, Personage, to synthesize a new corpus of over 88,000 restaurant domain utterances whose style varies according to models of personality, giving us total control over both the semantic content and the stylistic variation in the training data. We then vary the amount of explicit stylistic supervision given to the three models. We show that our most explicit model can simultaneously achieve high fidelity to both semantic and stylistic goals: this model adds a context vector of 36 stylistic parameters as input to the hidden state of the encoder at each time step, showing the benefits of explicit stylistic supervision, even when the amount of training data is large.
Creating and Characterizing a Diverse Corpus of Sarcasm in Dialogue
Sep 15, 2017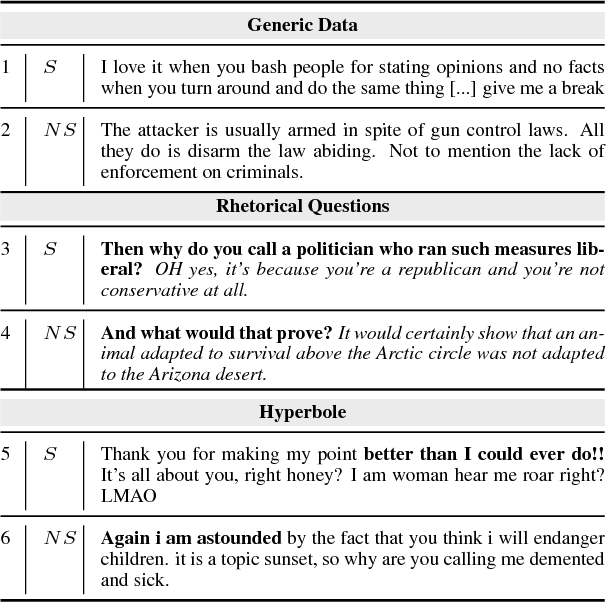

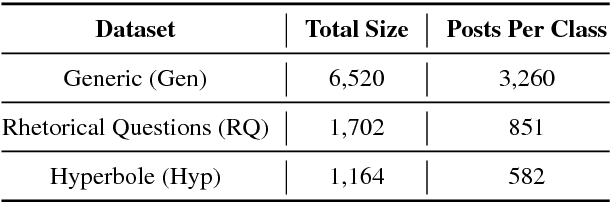
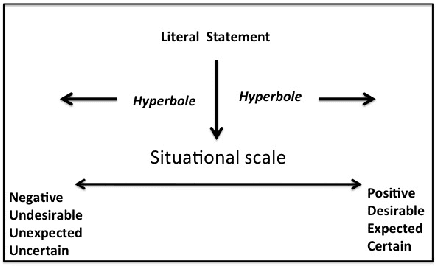
The use of irony and sarcasm in social media allows us to study them at scale for the first time. However, their diversity has made it difficult to construct a high-quality corpus of sarcasm in dialogue. Here, we describe the process of creating a large- scale, highly-diverse corpus of online debate forums dialogue, and our novel methods for operationalizing classes of sarcasm in the form of rhetorical questions and hyperbole. We show that we can use lexico-syntactic cues to reliably retrieve sarcastic utterances with high accuracy. To demonstrate the properties and quality of our corpus, we conduct supervised learning experiments with simple features, and show that we achieve both higher precision and F than previous work on sarcasm in debate forums dialogue. We apply a weakly-supervised linguistic pattern learner and qualitatively analyze the linguistic differences in each class.