 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Purchase-Impression Gap through a Sequential Re-ranker
Oct 27, 2020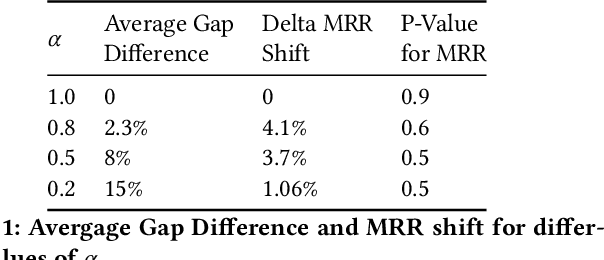
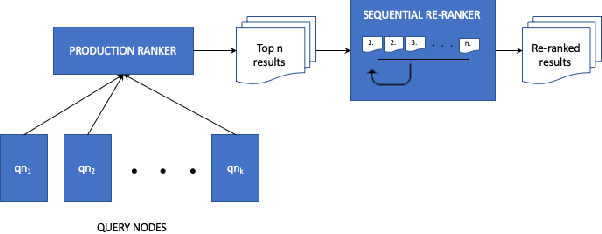
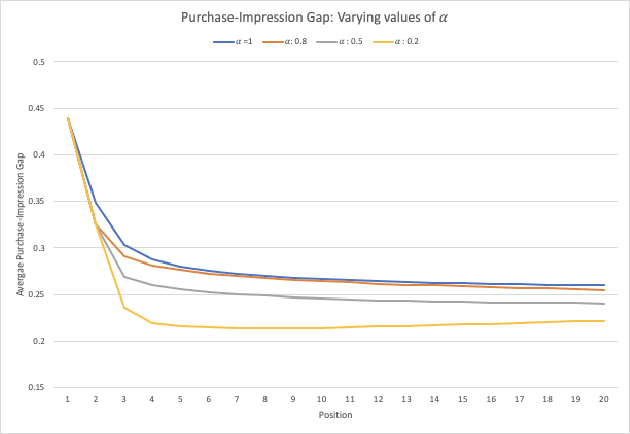
Large scale eCommerce platforms such as eBay carry a wide variety of inventory and provide several buying choices to online shoppers. It is critical for eCommerce search engines to showcase in the top results the variety and selection of inventory available, specifically in the context of the various buying intents that may be associated with a search query. Search rankers are most commonly powered by learning-to-rank models which learn the preference between items during training. However, they score items independent of other items at runtime. Although the items placed at top of the results by such scoring functions may be independently optimal, they can be sub-optimal as a set. This may lead to a mismatch between the ideal distribution of items in the top results vs what is actually impressed. In this paper, we present methods to address the purchase-impression gap observed in top search results on eCommerce sites. We establish the ideal distribution of items based on historic shopping patterns. We then present a sequential reranker that methodically reranks top search results produced by a conventional pointwise scoring ranker. The reranker produces a reordered list by sequentially selecting candidates trading off between their independent relevance and potential to address the purchase-impression gap by utilizing specially constructed features that capture impression distribution of items already added to a reranked list. The sequential reranker enables addressing purchase impression gap with respect to multiple item aspects. Early version of the reranker showed promising lifts in conversion and engagement metrics at eBay. Based on experiments on randomly sampled validation datasets, we observe that the reranking methodology presented produces around 10% reduction in purchase-impression gap at an average for the top 20 results, while making improvements to conversion metrics.
Exploring the Effect of an Item's Neighborhood on its Sellability in eCommerce
Aug 10, 2019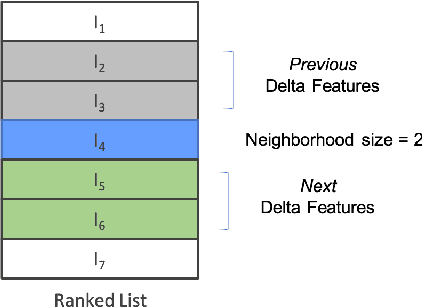
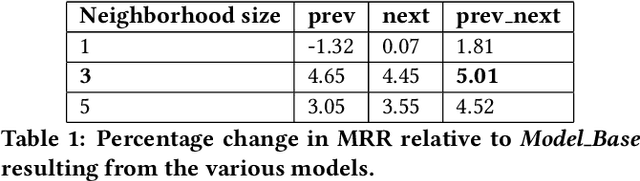
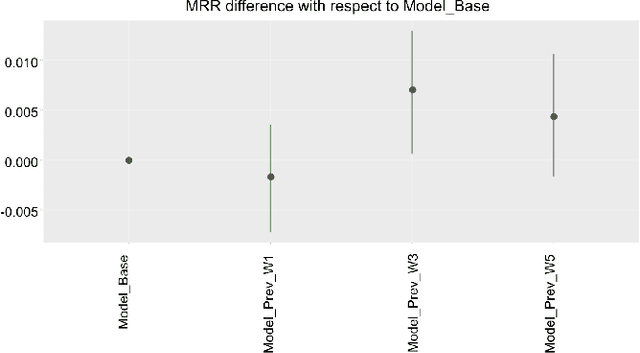
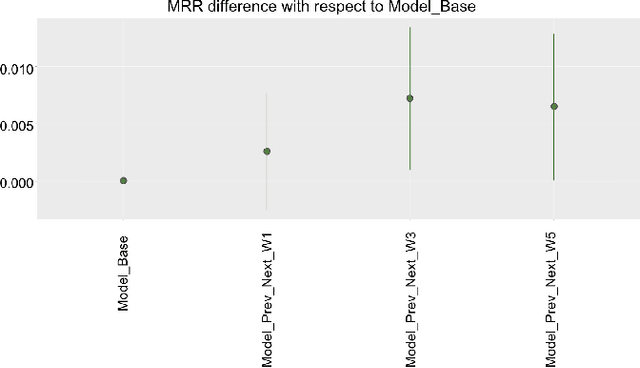
Predicting the sale of an item is a critical problem in eCommerce search. Typically, items are independently predicted with a probability of sale for a given search query. But in a dynamic marketplace like eBay, even for a single product, there are various different factors distinguishing one item from another which can influence the purchase decision for the user. Users have to make a purchase decision by considering all of these options. Majority of the existing learning to rank algorithms model the relative relevance between labeled items only at the loss functions like pairwise or list-wise losses. But they are limited to point-wise scoring functions where items are ranked independently based on the features of the item itself. In this paper, we study the influence of an item's neighborhood to its purchase decision. Here, we consider the neighborhood as the items ranked above and below the current item in search results. By adding delta features comparing items within a neighborhood and learning a ranking model, we are able to experimentally show that the new ranker with delta features outperforms our baseline ranker in terms of Mean Reciprocal Rank (MRR). The ranking model with proposed delta features result in $3-5\%$ improvement in MRR over the baseline model. We also study impact of different sizes for neighborhood. Experimental results show that neighborhood size $3$ perform the best based on MRR with an improvement of $4-5\%$ over the baseline model.
Neural MultiVoice Models for Expressing Novel Personalities in Dialog
Sep 05, 2018
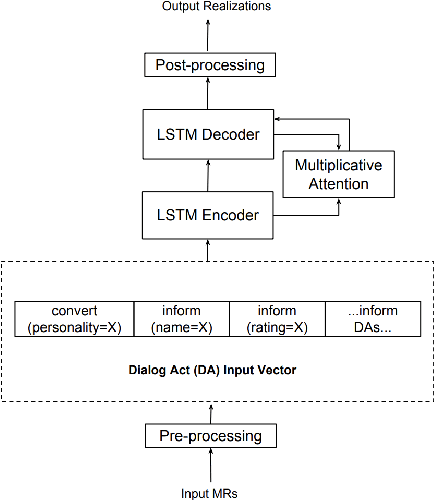

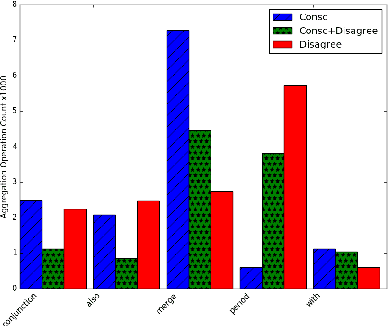
Natural language generators for task-oriented dialog should be able to vary the style of the output utterance while still effectively realizing the system dialog actions and their associated semantics. While the use of neural generation for training the response generation component of conversational agents promises to simplify the process of producing high quality responses in new domains, to our knowledge, there has been very little investigation of neural generators for task-oriented dialog that can vary their response style, and we know of no experiments on models that can generate responses that are different in style from those seen during training, while still maintain- ing semantic fidelity to the input meaning representation. Here, we show that a model that is trained to achieve a single stylis- tic personality target can produce outputs that combine stylistic targets. We carefully evaluate the multivoice outputs for both semantic fidelity and for similarities to and differences from the linguistic features that characterize the original training style. We show that contrary to our predictions, the learned models do not always simply interpolate model parameters, but rather produce styles that are distinct, and novel from the personalities they were trained on.
Controlling Personality-Based Stylistic Variation with Neural Natural Language Generators
May 22, 2018
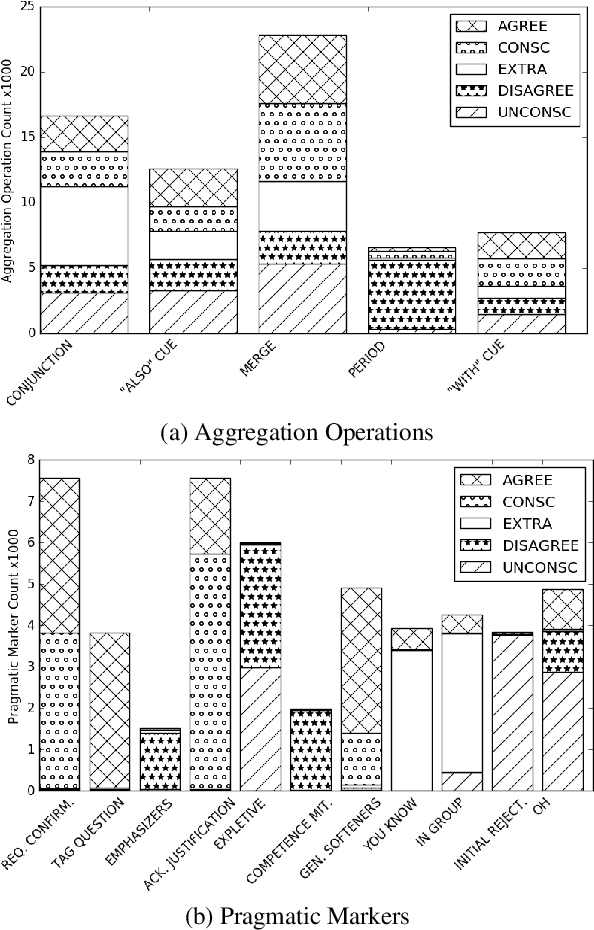

Natural language generators for task-oriented dialogue must effectively realize system dialogue actions and their associated semantics. In many applications, it is also desirable for generators to control the style of an utterance. To date, work on task-oriented neural generation has primarily focused on semantic fidelity rather than achieving stylistic goals, while work on style has been done in contexts where it is difficult to measure content preservation. Here we present three different sequence-to-sequence models and carefully test how well they disentangle content and style. We use a statistical generator, Personage, to synthesize a new corpus of over 88,000 restaurant domain utterances whose style varies according to models of personality, giving us total control over both the semantic content and the stylistic variation in the training data. We then vary the amount of explicit stylistic supervision given to the three models. We show that our most explicit model can simultaneously achieve high fidelity to both semantic and stylistic goals: this model adds a context vector of 36 stylistic parameters as input to the hidden state of the encoder at each time step, showing the benefits of explicit stylistic supervision, even when the amount of training data is large.
Summarizing Dialogic Arguments from Social Media
Oct 31, 2017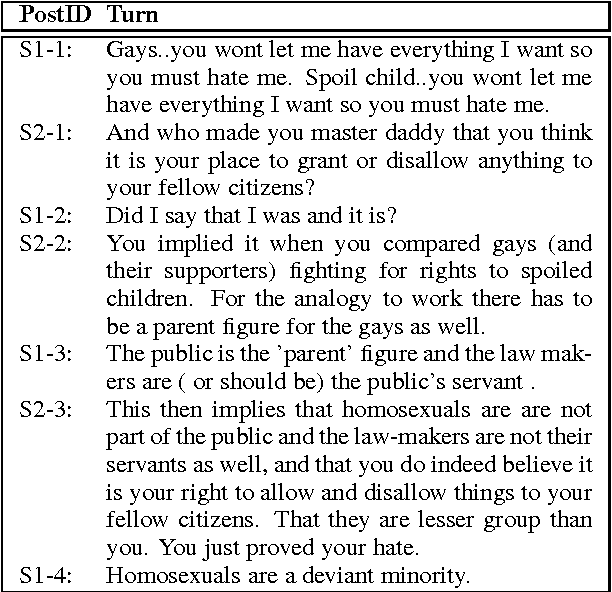
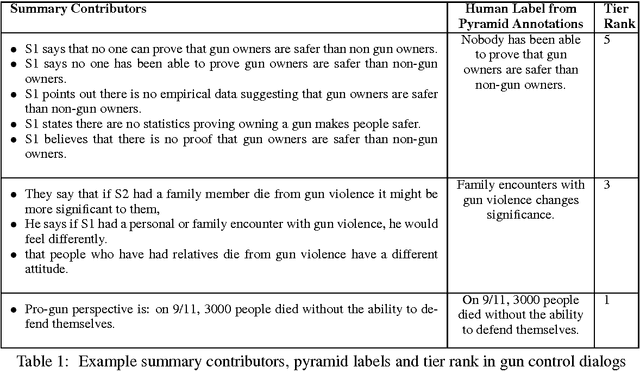

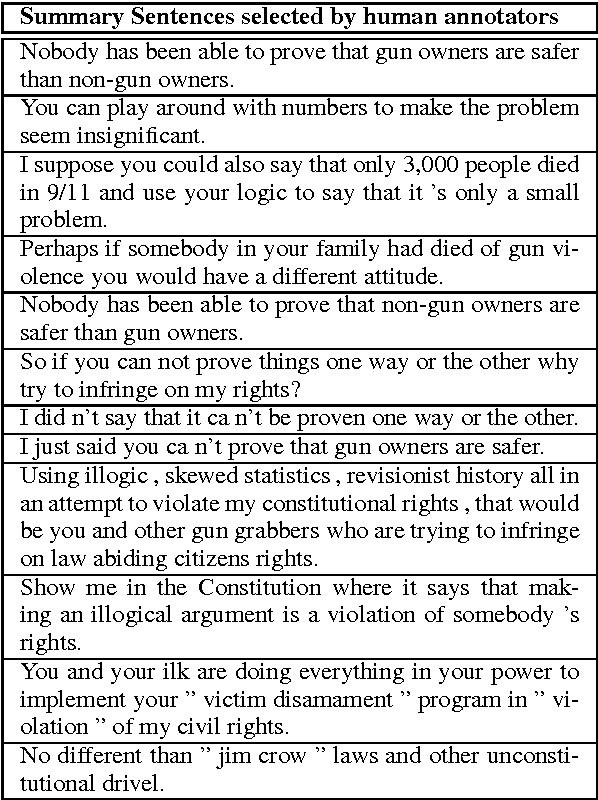
Online argumentative dialog is a rich source of information on popular beliefs and opinions that could be useful to companies as well as governmental or public policy agencies. Compact, easy to read, summaries of these dialogues would thus be highly valuable. A priori, it is not even clear what form such a summary should take. Previous work on summarization has primarily focused on summarizing written texts, where the notion of an abstract of the text is well defined. We collect gold standard training data consisting of five human summaries for each of 161 dialogues on the topics of Gay Marriage, Gun Control and Abortion. We present several different computational models aimed at identifying segments of the dialogues whose content should be used for the summary, using linguistic features and Word2vec features with both SVMs and Bidirectional LSTMs. We show that we can identify the most important arguments by using the dialog context with a best F-measure of 0.74 for gun control, 0.71 for gay marriage, and 0.67 for abortion.
A Dual Encoder Sequence to Sequence Model for Open-Domain Dialogue Modeling
Oct 28, 2017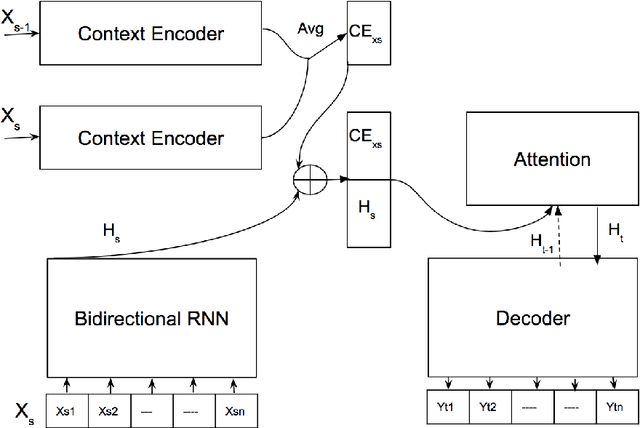


Ever since the successful application of sequence to sequence learning for neural machine translation systems, interest has surged in its applicability towards language generation in other problem domains. Recent work has investigated the use of these neural architectures towards modeling open-domain conversational dialogue, where it has been found that although these models are capable of learning a good distributional language model, dialogue coherence is still of concern. Unlike translation, conversation is much more a one-to-many mapping from utterance to a response, and it is even more pressing that the model be aware of the preceding flow of conversation. In this paper we propose to tackle this problem by introducing previous conversational context in terms of latent representations of dialogue acts over time. We inject the latent context representations into a sequence to sequence neural network in the form of dialog acts using a second encoder to enhance the quality and the coherence of the conversations generated. The main task of this research work is to show that adding latent variables that capture discourse relations does indeed result in more coherent responses when compared to conventional sequence to sequence models.
Topic Based Sentiment Analysis Using Deep Learning
Oct 28, 2017

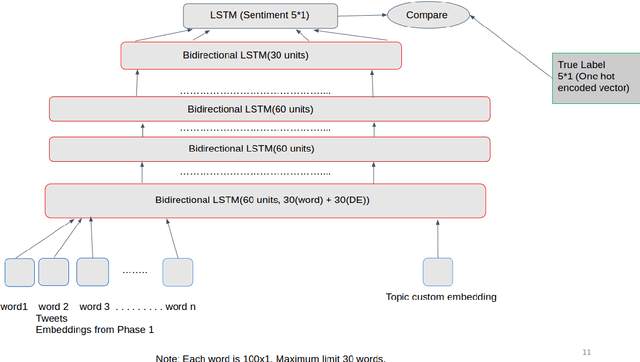
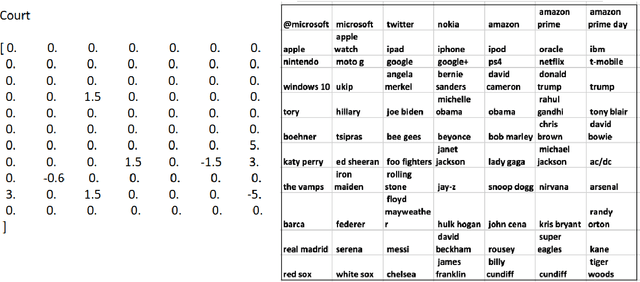
In this paper , we tackle Sentiment Analysis conditioned on a Topic in Twitter data using Deep Learning . We propose a 2-tier approach : In the first phase we create our own Word Embeddings and see that they do perform better than state-of-the-art embeddings when used with standard classifiers. We then perform inference on these embeddings to learn more about a word with respect to all the topics being considered, and also the top n-influencing words for each topic. In the second phase we use these embeddings to predict the sentiment of the tweet with respect to a given topic, and all other topics under discussion.