 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX-MEM: Agentic Semi-Structured Memory with Temporal Reasoning for Long-Term Conversational AI
Apr 15, 2026Large language models still struggle with reliable long-term conversational memory: simply enlarging context windows or applying naive retrieval often introduces noise and destabilizes responses. We present APEX-MEM, a conversational memory system that combines three key innovations: (1) a property graph which uses domain-agnostic ontology to structure conversations as temporally grounded events in an entity-centric framework, (2) append-only storage that preserves the full temporal evolution of information, and (3) a multi-tool retrieval agent that understands and resolves conflicting or evolving information at query time, producing a compact and contextually relevant memory summary. This retrieval-time resolution preserves the full interaction history while suppressing irrelevant details. APEX-MEM achieves 88.88% accuracy on LOCOMO's Question Answering task and 86.2% on LongMemEval, outperforming state-of-the-art session-aware approaches and demonstrating that structured property graphs enable more temporally coherent long-term conversational reasoning.
Controlled Text Generation with Hidden Representation Transformations
May 31, 2023



We propose CHRT (Control Hidden Representation Transformation) - a controlled language generation framework that steers large language models to generate text pertaining to certain attributes (such as toxicity). CHRT gains attribute control by modifying the hidden representation of the base model through learned transformations. We employ a contrastive-learning framework to learn these transformations that can be combined to gain multi-attribute control. The effectiveness of CHRT is experimentally shown by comparing it with seven baselines over three attributes. CHRT outperforms all the baselines in the task of detoxification, positive sentiment steering, and text simplification while minimizing the loss in linguistic qualities. Further, our approach has the lowest inference latency of only 0.01 seconds more than the base model, making it the most suitable for high-performance production environments. We open-source our code and release two novel datasets to further propel controlled language generation research.
Machine Translation Impact in E-commerce Multilingual Search
Jan 31, 2023



Previous work suggests that performance of cross-lingual information retrieval correlates highly with the quality of Machine Translation. However, there may be a threshold beyond which improving query translation quality yields little or no benefit to further improve the retrieval performance. This threshold may depend upon multiple factors including the source and target languages, the existing MT system quality and the search pipeline. In order to identify the benefit of improving an MT system for a given search pipeline, we investigate the sensitivity of retrieval quality to the presence of different levels of MT quality using experimental datasets collected from actual traffic. We systematically improve the performance of our MT systems quality on language pairs as measured by MT evaluation metrics including Bleu and Chrf to determine their impact on search precision metrics and extract signals that help to guide the improvement strategies. Using this information we develop techniques to compare query translations for multiple language pairs and identify the most promising language pairs to invest and improve.
Accountable Error Characterization
May 10, 2021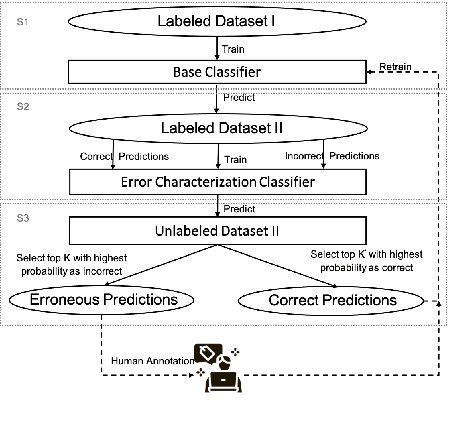
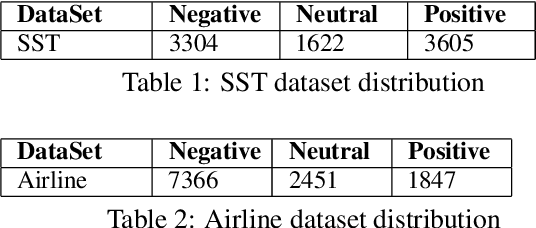

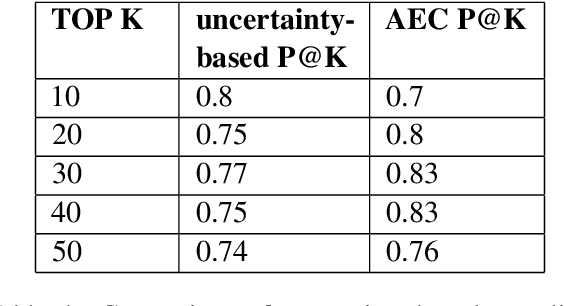
Customers of machine learning systems demand accountability from the companies employing these algorithms for various prediction tasks. Accountability requires understanding of system limit and condition of erroneous predictions, as customers are often interested in understanding the incorrect predictions, and model developers are absorbed in finding methods that can be used to get incremental improvements to an existing system. Therefore, we propose an accountable error characterization method, AEC, to understand when and where errors occur within the existing black-box models. AEC, as constructed with human-understandable linguistic features, allows the model developers to automatically identify the main sources of errors for a given classification system. It can also be used to sample for the set of most informative input points for a next round of training. We perform error detection for a sentiment analysis task using AEC as a case study. Our results on the sample sentiment task show that AEC is able to characterize erroneous predictions into human understandable categories and also achieves promising results on selecting erroneous samples when compared with the uncertainty-based sampling.
Teacher-Student Learning Paradigm for Tri-training: An Efficient Method for Unlabeled Data Exploitation
Sep 25, 2019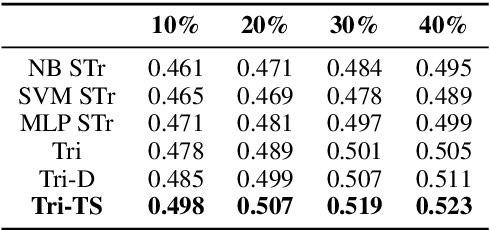
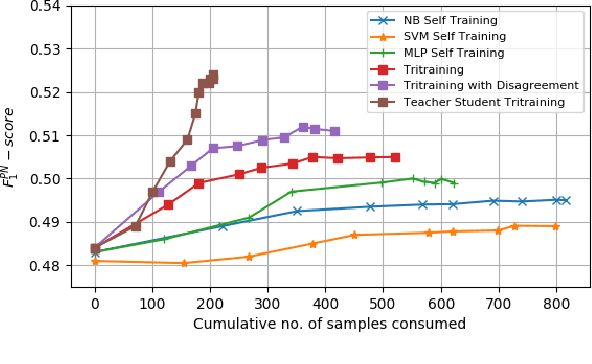
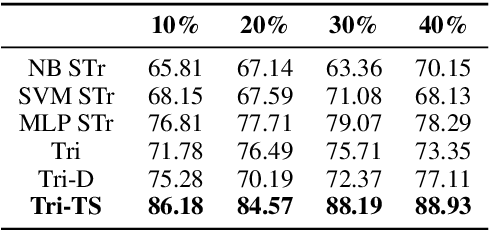
Given that labeled data is expensive to obtain in real-world scenarios, many semi-supervised algorithms have explored the task of exploitation of unlabeled data. Traditional tri-training algorithm and tri-training with disagreement have shown promise in tasks where labeled data is limited. In this work, we introduce a new paradigm for tri-training, mimicking the real world teacher-student learning process. We show that the adaptive teacher-student thresholds used in the proposed method provide more control over the learning process with higher label quality. We perform evaluation on SemEval sentiment analysis task and provide comprehensive comparisons over experimental settings containing varied labeled versus unlabeled data rates. Experimental results show that our method outperforms other strong semi-supervised baselines, while requiring less number of labeled training samples.
Using Structured Representation and Data: A Hybrid Model for Negation and Sentiment in Customer Service Conversations
Jun 11, 2019


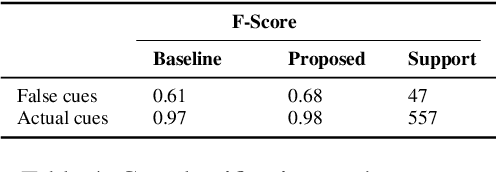
Twitter customer service interactions have recently emerged as an effective platform to respond and engage with customers. In this work, we explore the role of negation in customer service interactions, particularly applied to sentiment analysis. We define rules to identify true negation cues and scope more suited to conversational data than existing general review data. Using semantic knowledge and syntactic structure from constituency parse trees, we propose an algorithm for scope detection that performs comparable to state of the art BiLSTM. We further investigate the results of negation scope detection for the sentiment prediction task on customer service conversation data using both a traditional SVM and a Neural Network. We propose an antonym dictionary based method for negation applied to a CNN-LSTM combination model for sentiment analysis. Experimental results show that the antonym-based method outperforms the previous lexicon-based and neural network methods.
Don't get Lost in Negation: An Effective Negation Handled Dialogue Acts Prediction Algorithm for Twitter Customer Service Conversations
Jul 16, 2018

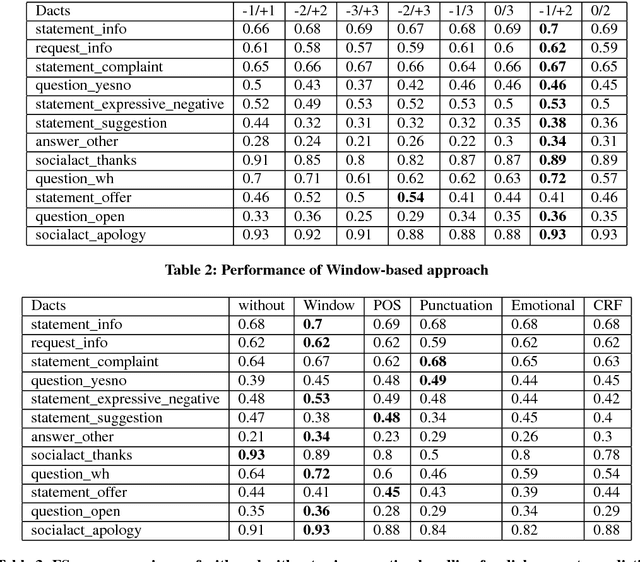
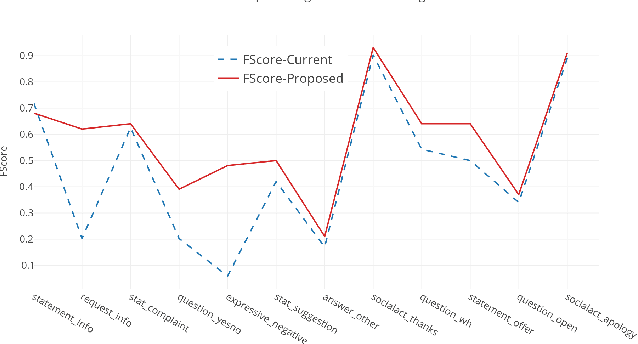
In the last several years, Twitter is being adopted by the companies as an alternative platform to interact with the customers to address their concerns. With the abundance of such unconventional conversation resources, push for developing effective virtual agents is more than ever. To address this challenge, a better understanding of such customer service conversations is required. Lately, there have been several works proposing a novel taxonomy for fine-grained dialogue acts as well as develop algorithms for automatic detection of these acts. The outcomes of these works are providing stepping stones for the ultimate goal of building efficient and effective virtual agents. But none of these works consider handling the notion of negation into the proposed algorithms. In this work, we developed an SVM-based dialogue acts prediction algorithm for Twitter customer service conversations where negation handling is an integral part of the end-to-end solution. For negation handling, we propose several efficient heuristics as well as adopt recent state-of- art third party machine learning based solutions. Empirically we show model's performance gain while handling negation compared to when we don't. Our experiments show that for the informal text such as tweets, the heuristic-based approach is more effective.
SlugNERDS: A Named Entity Recognition Tool for Open Domain Dialogue Systems
May 10, 2018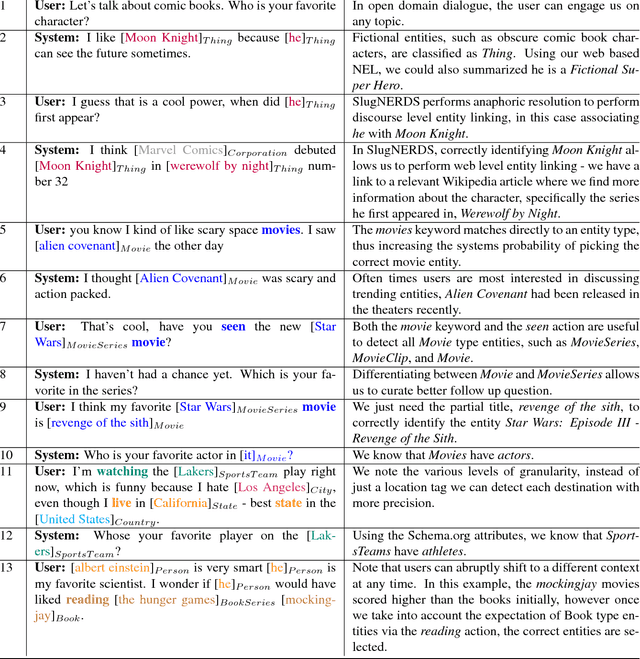
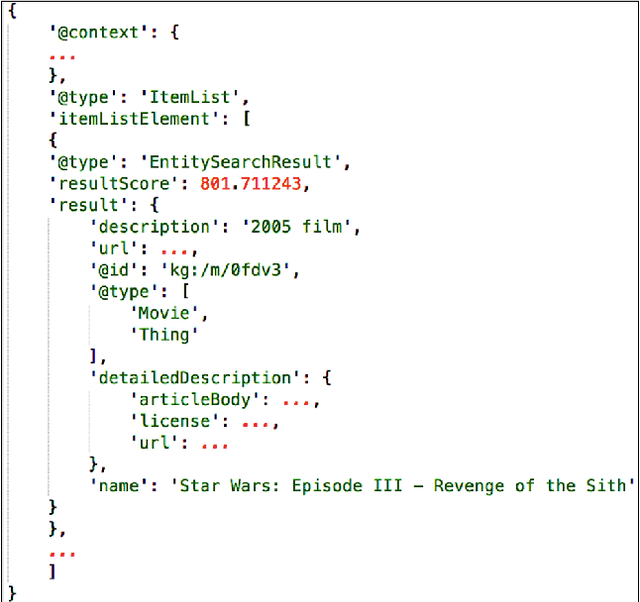
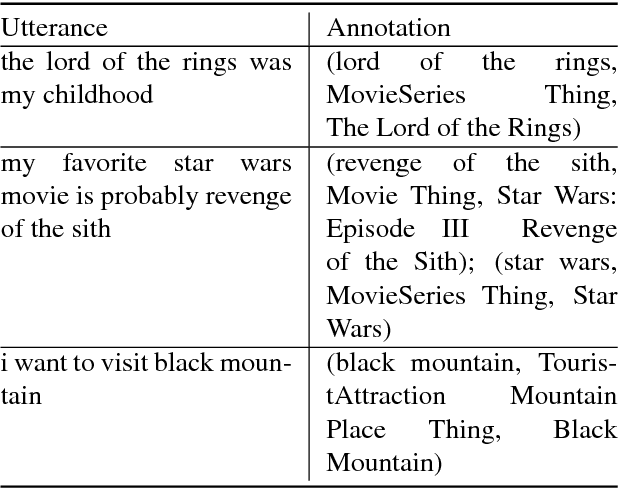
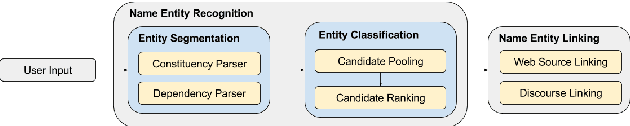
In dialogue systems, the tasks of named entity recognition (NER) and named entity linking (NEL) are vital preprocessing steps for understanding user intent, especially in open domain interaction where we cannot rely on domain-specific inference. UCSC's effort as one of the funded teams in the 2017 Amazon Alexa Prize Contest has yielded Slugbot, an open domain social bot, aimed at casual conversation. We discovered several challenges specifically associated with both NER and NEL when building Slugbot, such as that the NE labels are too coarse-grained or the entity types are not linked to a useful ontology. Moreover, we have discovered that traditional approaches do not perform well in our context: even systems designed to operate on tweets or other social media data do not work well in dialogue systems. In this paper, we introduce Slugbot's Named Entity Recognition for dialogue Systems (SlugNERDS), a NER and NEL tool which is optimized to address these issues. We describe two new resources that we are building as part of this work: SlugEntityDB and SchemaActuator. We believe these resources will be useful for the research community.
* Resources can be found: https://nlds.soe.ucsc.edu/node/56
Slugbot: An Application of a Novel and Scalable Open Domain Socialbot Framework
Jan 04, 2018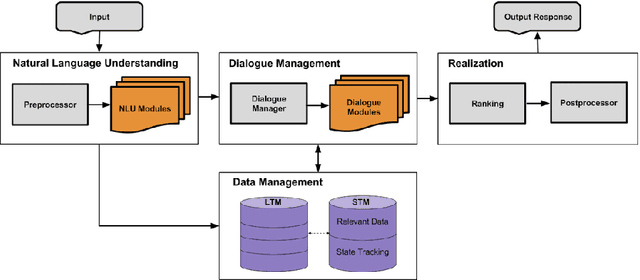
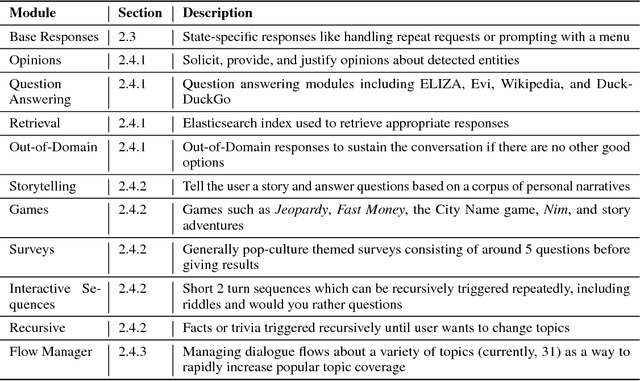


In this paper we introduce a novel, open domain socialbot for the Amazon Alexa Prize competition, aimed at carrying on friendly conversations with users on a variety of topics. We present our modular system, highlighting our different data sources and how we use the human mind as a model for data management. Additionally we build and employ natural language understanding and information retrieval tools and APIs to expand our knowledge bases. We describe our semistructured, scalable framework for crafting topic-specific dialogue flows, and give details on our dialogue management schemes and scoring mechanisms. Finally we briefly evaluate the performance of our system and observe the challenges that an open domain socialbot faces.
Summarizing Dialogic Arguments from Social Media
Oct 31, 2017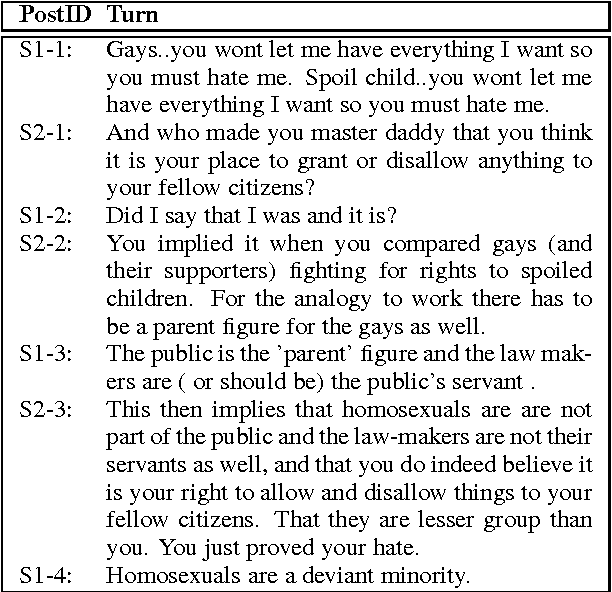
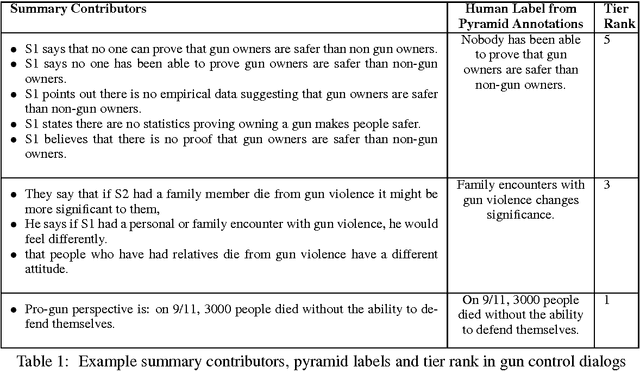

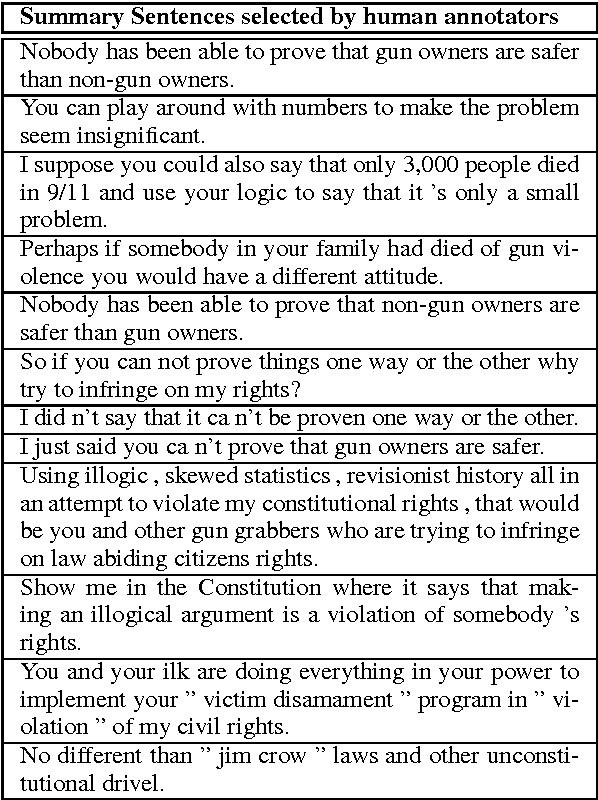
Online argumentative dialog is a rich source of information on popular beliefs and opinions that could be useful to companies as well as governmental or public policy agencies. Compact, easy to read, summaries of these dialogues would thus be highly valuable. A priori, it is not even clear what form such a summary should take. Previous work on summarization has primarily focused on summarizing written texts, where the notion of an abstract of the text is well defined. We collect gold standard training data consisting of five human summaries for each of 161 dialogues on the topics of Gay Marriage, Gun Control and Abortion. We present several different computational models aimed at identifying segments of the dialogues whose content should be used for the summary, using linguistic features and Word2vec features with both SVMs and Bidirectional LSTMs. We show that we can identify the most important arguments by using the dialog context with a best F-measure of 0.74 for gun control, 0.71 for gay marriage, and 0.67 for abortion.