 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX-MEM: Agentic Semi-Structured Memory with Temporal Reasoning for Long-Term Conversational AI
Apr 15, 2026Large language models still struggle with reliable long-term conversational memory: simply enlarging context windows or applying naive retrieval often introduces noise and destabilizes responses. We present APEX-MEM, a conversational memory system that combines three key innovations: (1) a property graph which uses domain-agnostic ontology to structure conversations as temporally grounded events in an entity-centric framework, (2) append-only storage that preserves the full temporal evolution of information, and (3) a multi-tool retrieval agent that understands and resolves conflicting or evolving information at query time, producing a compact and contextually relevant memory summary. This retrieval-time resolution preserves the full interaction history while suppressing irrelevant details. APEX-MEM achieves 88.88% accuracy on LOCOMO's Question Answering task and 86.2% on LongMemEval, outperforming state-of-the-art session-aware approaches and demonstrating that structured property graphs enable more temporally coherent long-term conversational reasoning.
APEX-EM: Non-Parametric Online Learning for Autonomous Agents via Structured Procedural-Episodic Experience Replay
Mar 31, 2026LLM-based autonomous agents lack persistent procedural memory: they re-derive solutions from scratch even when structurally identical tasks have been solved before. We present \textbf{APEX-EM}, a non-parametric online learning framework that accumulates, retrieves, and reuses structured procedural plans without modifying model weights. APEX-EM introduces: (1) a \emph{structured experience representation} encoding the full procedural-episodic trace of each execution -- planning steps, artifacts, iteration history with error analysis, and quality scores; (2) a \emph{Plan-Retrieve-Generate-Iterate-Ingest} (PRGII) workflow with Task Verifiers providing multi-dimensional reward signals; and (3) a \emph{dual-outcome Experience Memory} with hybrid retrieval combining semantic search, structural signature matching, and plan DAG traversal -- enabling cross-domain transfer between tasks sharing no lexical overlap but analogous operational structure. Successful experiences serve as positive in-context examples; failures as negative examples with structured error annotations. We evaluate on BigCodeBench~\cite{zhuo2025bigcodebench}, KGQAGen-10k~\cite{zhang2025kgqagen}, and Humanity's Last Exam~\cite{phan2025hle} using Claude Sonnet 4.5 and Opus 4.5. On KGQAGen-10k, APEX-EM achieves 89.6\% accuracy versus 41.3\% without memory (+48.3pp), surpassing the oracle-retrieval upper bound (84.9\%). On BigCodeBench, it reaches 83.3\% SR from a 53.9\% baseline (+29.4pp), exceeding MemRL's~\cite{memrl2025} +11.0pp gain under comparable frozen-backbone conditions (noting backbone differences controlled for in our analysis). On HLE, entity graph retrieval reaches 48.0\% from 25.2\% (+22.8pp). Ablations show component value is task-dependent: rich judge feedback is negligible for code generation but critical for structured queries (+10.3pp), while binary-signal iteration partially compensates for weaker feedback.
Question-Context Alignment and Answer-Context Dependencies for Effective Answer Sentence Selection
Jun 03, 2023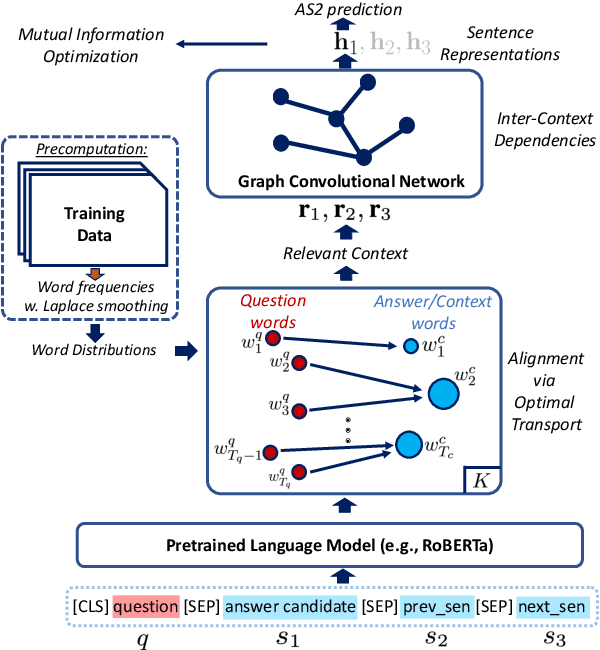
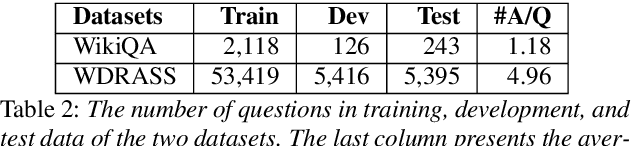
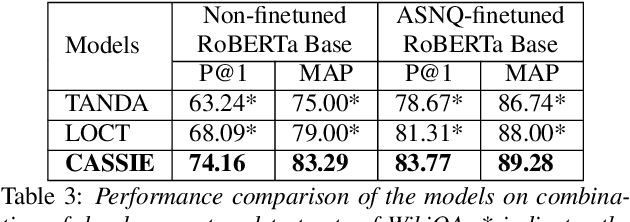
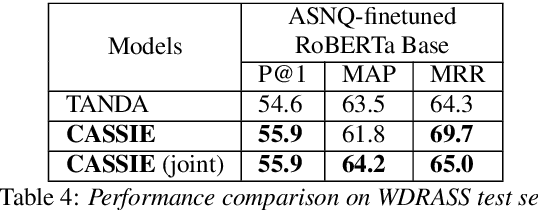
Answer sentence selection (AS2) in open-domain question answering finds answer for a question by ranking candidate sentences extracted from web documents. Recent work exploits answer context, i.e., sentences around a candidate, by incorporating them as additional input string to the Transformer models to improve the correctness scoring. In this paper, we propose to improve the candidate scoring by explicitly incorporating the dependencies between question-context and answer-context into the final representation of a candidate. Specifically, we use Optimal Transport to compute the question-based dependencies among sentences in the passage where the answer is extracted from. We then represent these dependencies as edges in a graph and use Graph Convolutional Network to derive the representation of a candidate, a node in the graph. Our proposed model achieves significant improvements on popular AS2 benchmarks, i.e., WikiQA and WDRASS, obtaining new state-of-the-art on all benchmarks.
Controlled Text Generation with Hidden Representation Transformations
May 31, 2023



We propose CHRT (Control Hidden Representation Transformation) - a controlled language generation framework that steers large language models to generate text pertaining to certain attributes (such as toxicity). CHRT gains attribute control by modifying the hidden representation of the base model through learned transformations. We employ a contrastive-learning framework to learn these transformations that can be combined to gain multi-attribute control. The effectiveness of CHRT is experimentally shown by comparing it with seven baselines over three attributes. CHRT outperforms all the baselines in the task of detoxification, positive sentiment steering, and text simplification while minimizing the loss in linguistic qualities. Further, our approach has the lowest inference latency of only 0.01 seconds more than the base model, making it the most suitable for high-performance production environments. We open-source our code and release two novel datasets to further propel controlled language generation research.
Cross-Lingual Knowledge Distillation for Answer Sentence Selection in Low-Resource Languages
May 25, 2023



While impressive performance has been achieved on the task of Answer Sentence Selection (AS2) for English, the same does not hold for languages that lack large labeled datasets. In this work, we propose Cross-Lingual Knowledge Distillation (CLKD) from a strong English AS2 teacher as a method to train AS2 models for low-resource languages in the tasks without the need of labeled data for the target language. To evaluate our method, we introduce 1) Xtr-WikiQA, a translation-based WikiQA dataset for 9 additional languages, and 2) TyDi-AS2, a multilingual AS2 dataset with over 70K questions spanning 8 typologically diverse languages. We conduct extensive experiments on Xtr-WikiQA and TyDi-AS2 with multiple teachers, diverse monolingual and multilingual pretrained language models (PLMs) as students, and both monolingual and multilingual training. The results demonstrate that CLKD either outperforms or rivals even supervised fine-tuning with the same amount of labeled data and a combination of machine translation and the teacher model. Our method can potentially enable stronger AS2 models for low-resource languages, while TyDi-AS2 can serve as the largest multilingual AS2 dataset for further studies in the research community.
ACM -- Attribute Conditioning for Abstractive Multi Document Summarization
May 09, 2022
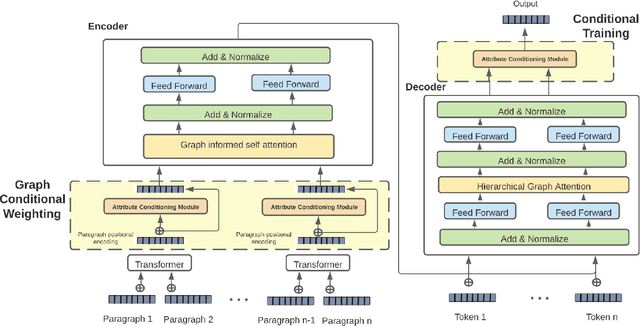


Abstractive multi document summarization has evolved as a task through the basic sequence to sequence approaches to transformer and graph based techniques. Each of these approaches has primarily focused on the issues of multi document information synthesis and attention based approaches to extract salient information. A challenge that arises with multi document summarization which is not prevalent in single document summarization is the need to effectively summarize multiple documents that might have conflicting polarity, sentiment or subjective information about a given topic. In this paper we propose ACM, attribute conditioned multi document summarization,a model that incorporates attribute conditioning modules in order to decouple conflicting information by conditioning for a certain attribute in the output summary. This approach shows strong gains in ROUGE score over baseline multi document summarization approaches and shows gains in fluency, informativeness and reduction in repetitiveness as shown through a human annotation analysis study.
Training Mixed-Domain Translation Models via Federated Learning
May 03, 2022



Training mixed-domain translation models is a complex task that demands tailored architectures and costly data preparation techniques. In this work, we leverage federated learning (FL) in order to tackle the problem. Our investigation demonstrates that with slight modifications in the training process, neural machine translation (NMT) engines can be easily adapted when an FL-based aggregation is applied to fuse different domains. Experimental results also show that engines built via FL are able to perform on par with state-of-the-art baselines that rely on centralized training techniques. We evaluate our hypothesis in the presence of five datasets with different sizes, from different domains, to translate from German into English and discuss how FL and NMT can mutually benefit from each other. In addition to providing benchmarking results on the union of FL and NMT, we also propose a novel technique to dynamically control the communication bandwidth by selecting impactful parameters during FL updates. This is a significant achievement considering the large size of NMT engines that need to be exchanged between FL parties.
Communication-Efficient Federated Learning for Neural Machine Translation
Dec 12, 2021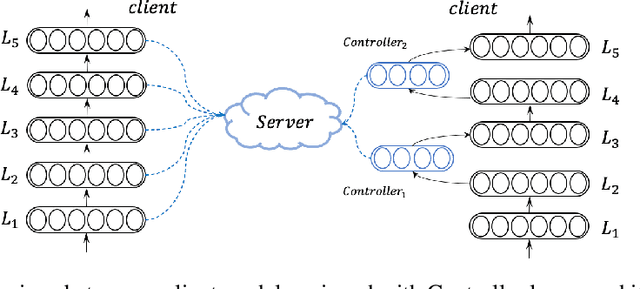
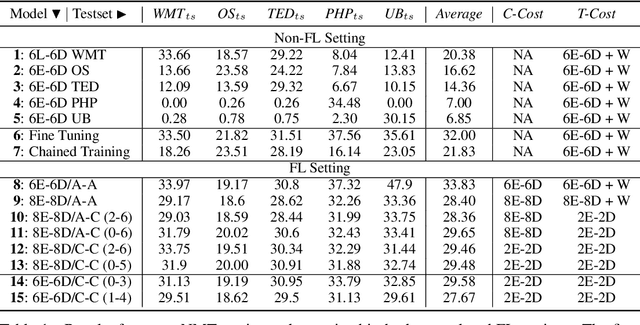
Training neural machine translation (NMT) models in federated learning (FL) settings could be inefficient both computationally and communication-wise, due to the large size of translation engines as well as the multiple rounds of updates required to train clients and a central server. In this paper, we explore how to efficiently build NMT models in an FL setup by proposing a novel solution. In order to reduce the communication overhead, out of all neural layers we only exchange what we term "Controller" layers. Controllers are a small number of additional neural components connected to our pre-trained architectures. These new components are placed in between original layers. They act as liaisons to communicate with the central server and learn minimal information that is sufficient enough to update clients. We evaluated the performance of our models on five datasets from different domains to translate from German into English. We noted that the models equipped with Controllers preform on par with those trained in a central and non-FL setting. In addition, we observed a substantial reduction in the communication traffic of the FL pipeline, which is a direct consequence of using Controllers. Based on our experiments, Controller-based models are ~6 times less expensive than their other peers. This reduction is significantly important when we consider the number of parameters in large models and it becomes even more critical when such parameters need to be exchanged for multiple rounds in FL settings.
Deep Reinforced Self-Attention Masks for Abstractive Summarization (DR.SAS)
Dec 30, 2019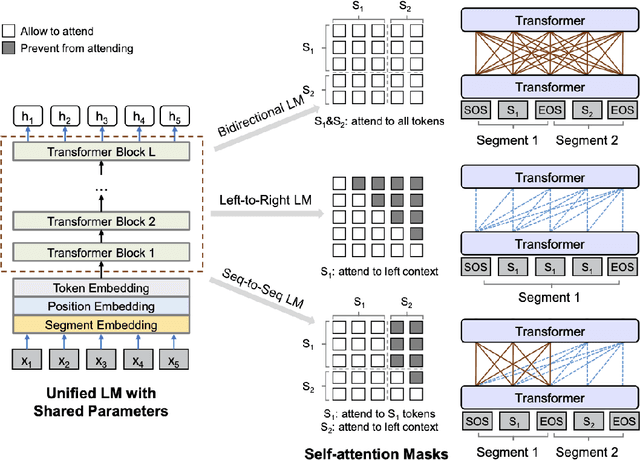
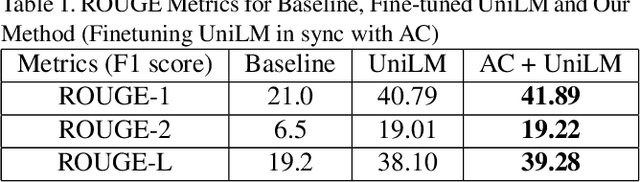

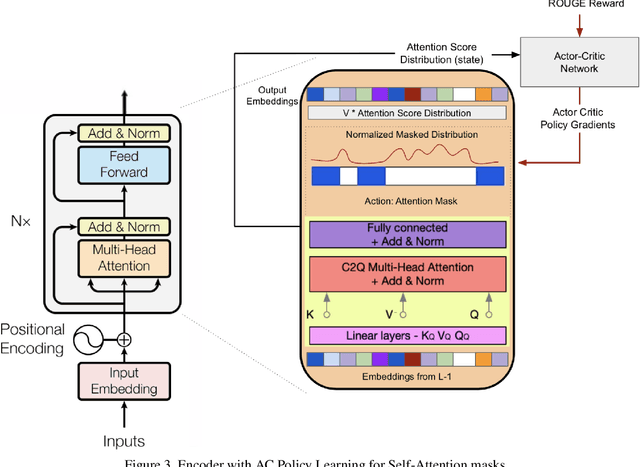
We present a novel architectural scheme to tackle the abstractive summarization problem based on the CNN/DMdataset which fuses Reinforcement Learning (RL) withUniLM, which is a pre-trained Deep Learning Model, to solve various natural language tasks. We have tested the limits of learning fine-grained attention in Transformers to improve the summarization quality. UniLM applies attention to the entire token space in a global fashion. We propose DR.SAS which applies the Actor-Critic (AC) algorithm to learn a dynamic self-attention distribution over the tokens to reduce redundancy and generate factual and coherent summaries to improve the quality of summarization. After performing hyperparameter tuning, we achievedbetter ROUGE results compared to the baseline. Our model tends to be more extractive/factual yet coherent in detail because of optimization over ROUGE rewards. We present detailed error analysis with examples of the strengths and limitations of our model. Our codebase will be publicly available on our GitHub.
BERTQA -- Attention on Steroids
Dec 14, 2019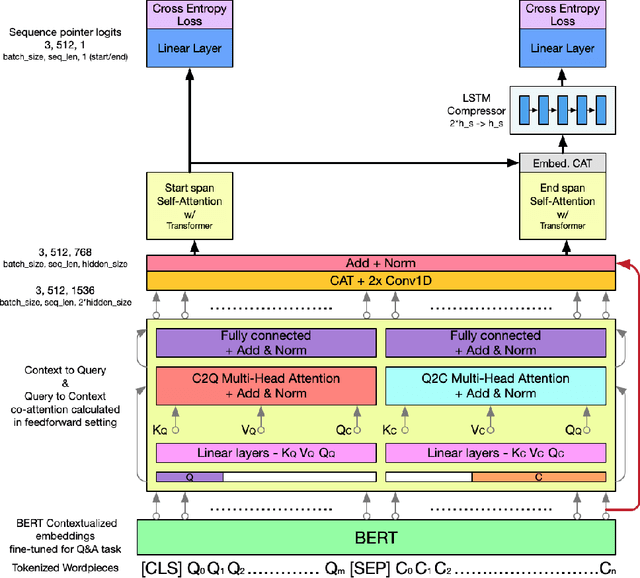
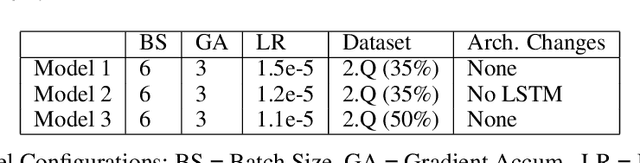
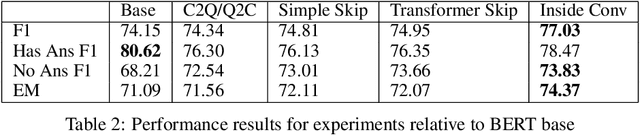
In this work, we extend the Bidirectional Encoder Representations from Transformers (BERT) with an emphasis on directed coattention to obtain an improved F1 performance on the SQUAD2.0 dataset. The Transformer architecture on which BERT is based places hierarchical global attention on the concatenation of the context and query. Our additions to the BERT architecture augment this attention with a more focused context to query (C2Q) and query to context (Q2C) attention via a set of modified Transformer encoder units. In addition, we explore adding convolution-based feature extraction within the coattention architecture to add localized information to self-attention. We found that coattention significantly improves the no answer F1 by 4 points in the base and 1 point in the large architecture. After adding skip connections the no answer F1 improved further without causing an additional loss in has answer F1. The addition of localized feature extraction added to attention produced an overall dev F1 of 77.03 in the base architecture. We applied our findings to the large BERT model which contains twice as many layers and further used our own augmented version of the SQUAD 2.0 dataset created by back translation, which we have named SQUAD 2.Q. Finally, we performed hyperparameter tuning and ensembled our best models for a final F1/EM of 82.317/79.442 (Attention on Steroids, PCE Test Leaderboard).