 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion-Context Alignment and Answer-Context Dependencies for Effective Answer Sentence Selection
Jun 03, 2023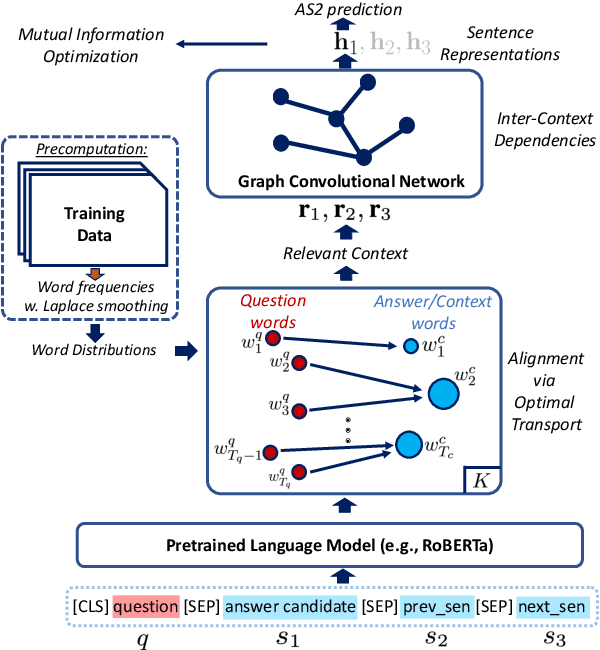
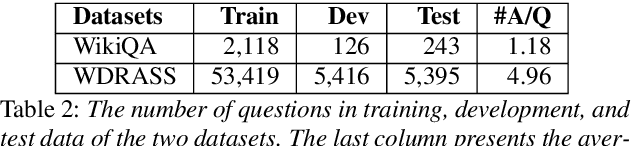
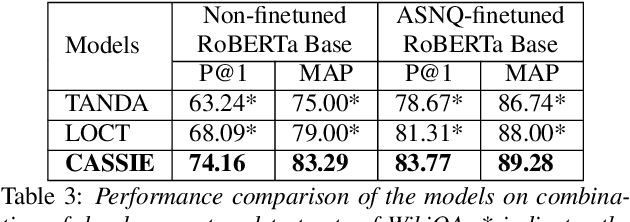
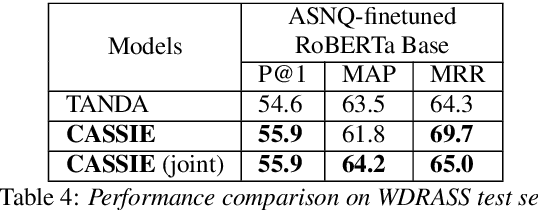
Answer sentence selection (AS2) in open-domain question answering finds answer for a question by ranking candidate sentences extracted from web documents. Recent work exploits answer context, i.e., sentences around a candidate, by incorporating them as additional input string to the Transformer models to improve the correctness scoring. In this paper, we propose to improve the candidate scoring by explicitly incorporating the dependencies between question-context and answer-context into the final representation of a candidate. Specifically, we use Optimal Transport to compute the question-based dependencies among sentences in the passage where the answer is extracted from. We then represent these dependencies as edges in a graph and use Graph Convolutional Network to derive the representation of a candidate, a node in the graph. Our proposed model achieves significant improvements on popular AS2 benchmarks, i.e., WikiQA and WDRASS, obtaining new state-of-the-art on all benchmarks.
MINION: a Large-Scale and Diverse Dataset for Multilingual Event Detection
Nov 17, 2022
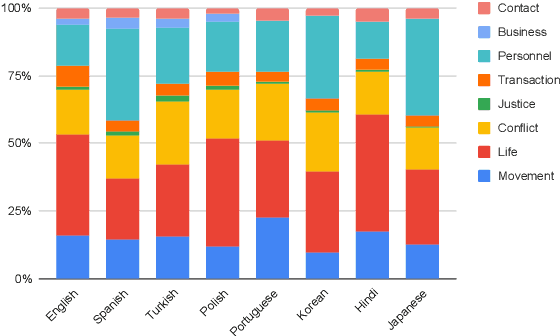


Event Detection (ED) is the task of identifying and classifying trigger words of event mentions in text. Despite considerable research efforts in recent years for English text, the task of ED in other languages has been significantly less explored. Switching to non-English languages, important research questions for ED include how well existing ED models perform on different languages, how challenging ED is in other languages, and how well ED knowledge and annotation can be transferred across languages. To answer those questions, it is crucial to obtain multilingual ED datasets that provide consistent event annotation for multiple languages. There exist some multilingual ED datasets; however, they tend to cover a handful of languages and mainly focus on popular ones. Many languages are not covered in existing multilingual ED datasets. In addition, the current datasets are often small and not accessible to the public. To overcome those shortcomings, we introduce a new large-scale multilingual dataset for ED (called MINION) that consistently annotates events for 8 different languages; 5 of them have not been supported by existing multilingual datasets. We also perform extensive experiments and analysis to demonstrate the challenges and transferability of ED across languages in MINION that in all call for more research effort in this area.
FAMIE: A Fast Active Learning Framework for Multilingual Information Extraction
Feb 16, 2022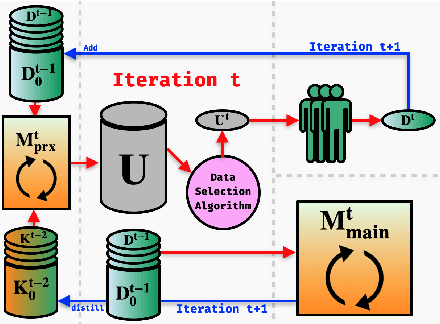


This paper presents FAMIE, a comprehensive and efficient active learning (AL) toolkit for multilingual information extraction. FAMIE is designed to address a fundamental problem in existing AL frameworks where annotators need to wait for a long time between annotation batches due to the time-consuming nature of model training and data selection at each AL iteration. This hinders the engagement, productivity, and efficiency of annotators. Based on the idea of using a small proxy network for fast data selection, we introduce a novel knowledge distillation mechanism to synchronize the proxy network with the main large model (i.e., BERT-based) to ensure the appropriateness of the selected annotation examples for the main model. Our AL framework can support multiple languages. The experiments demonstrate the advantages of FAMIE in terms of competitive performance and time efficiency for sequence labeling with AL. We publicly release our code (\url{https://github.com/nlp-uoregon/famie}) and demo website (\url{http://nlp.uoregon.edu:9000/}). A demo video for FAMIE is provided at: \url{https://youtu.be/I2i8n_jAyrY}.
Custom Deep Neural Network for 3D Covid Chest CT-scan Classification
Jul 03, 2021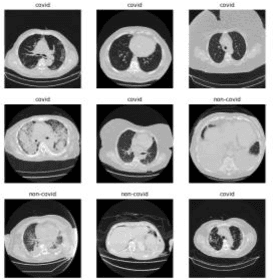
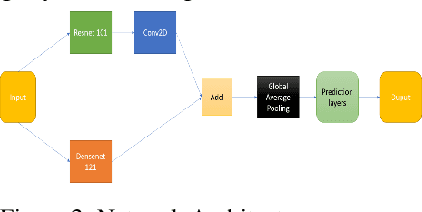


3D CT-scan base on chest is one of the controversial topisc of the researcher nowadays. There are many tasks to diagnose the disease through CT-scan images, include Covid19. In this paper, we propose a method that custom and combine Deep Neural Network to classify the series of 3D CT-scans chest images. In our methods, we experiment with 2 backbones is DenseNet 121 and ResNet 101. In this proposal, we separate the experiment into 2 tasks, one is for 2 backbones combination of ResNet and DenseNet, one is for DenseNet backbones combination.
Cross-Task Instance Representation Interactions and Label Dependencies for Joint Information Extraction with Graph Convolutional Networks
Mar 26, 2021
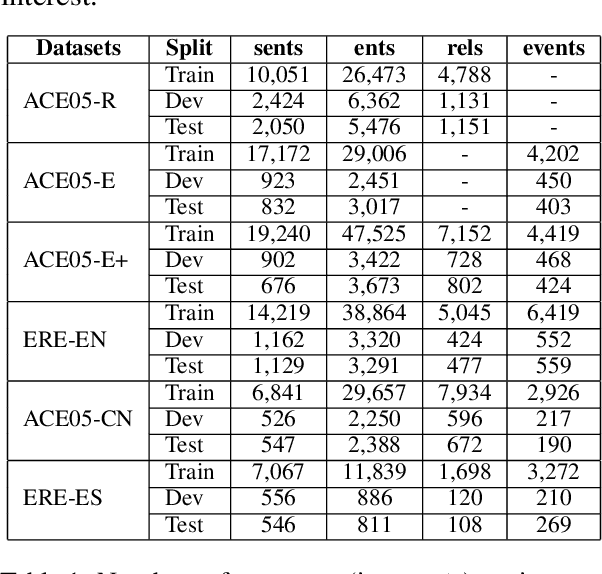

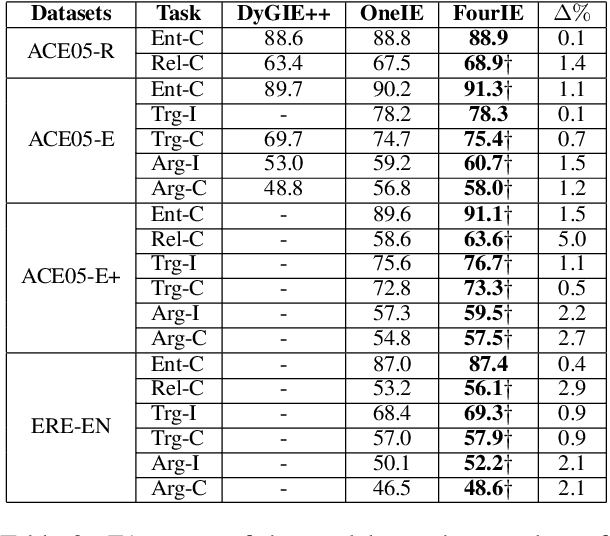
Existing works on information extraction (IE) have mainly solved the four main tasks separately (entity mention recognition, relation extraction, event trigger detection, and argument extraction), thus failing to benefit from inter-dependencies between tasks. This paper presents a novel deep learning model to simultaneously solve the four tasks of IE in a single model (called FourIE). Compared to few prior work on jointly performing four IE tasks, FourIE features two novel contributions to capture inter-dependencies between tasks. First, at the representation level, we introduce an interaction graph between instances of the four tasks that is used to enrich the prediction representation for one instance with those from related instances of other tasks. Second, at the label level, we propose a dependency graph for the information types in the four IE tasks that captures the connections between the types expressed in an input sentence. A new regularization mechanism is introduced to enforce the consistency between the golden and predicted type dependency graphs to improve representation learning. We show that the proposed model achieves the state-of-the-art performance for joint IE on both monolingual and multilingual learning settings with three different languages.