 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrift No More? Context Equilibria in Multi-Turn LLM Interactions
Oct 09, 2025Large Language Models (LLMs) excel at single-turn tasks such as instruction following and summarization, yet real-world deployments require sustained multi-turn interactions where user goals and conversational context persist and evolve. A recurring challenge in this setting is context drift: the gradual divergence of a model's outputs from goal-consistent behavior across turns. Unlike single-turn errors, drift unfolds temporally and is poorly captured by static evaluation metrics. In this work, we present a study of context drift in multi-turn interactions and propose a simple dynamical framework to interpret its behavior. We formalize drift as the turn-wise KL divergence between the token-level predictive distributions of the test model and a goal-consistent reference model, and propose a recurrence model that interprets its evolution as a bounded stochastic process with restoring forces and controllable interventions. We instantiate this framework in both synthetic long-horizon rewriting tasks and realistic user-agent simulations such as in $\tau$-Bench, measuring drift for several open-weight LLMs that are used as user simulators. Our experiments consistently reveal stable, noise-limited equilibria rather than runaway degradation, and demonstrate that simple reminder interventions reliably reduce divergence in line with theoretical predictions. Together, these results suggest that multi-turn drift can be understood as a controllable equilibrium phenomenon rather than as inevitable decay, providing a foundation for studying and mitigating context drift in extended interactions.
A Survey on Long-Video Storytelling Generation: Architectures, Consistency, and Cinematic Quality
Jul 09, 2025

Despite the significant progress that has been made in video generative models, existing state-of-the-art methods can only produce videos lasting 5-16 seconds, often labeled "long-form videos". Furthermore, videos exceeding 16 seconds struggle to maintain consistent character appearances and scene layouts throughout the narrative. In particular, multi-subject long videos still fail to preserve character consistency and motion coherence. While some methods can generate videos up to 150 seconds long, they often suffer from frame redundancy and low temporal diversity. Recent work has attempted to produce long-form videos featuring multiple characters, narrative coherence, and high-fidelity detail. We comprehensively studied 32 papers on video generation to identify key architectural components and training strategies that consistently yield these qualities. We also construct a comprehensive novel taxonomy of existing methods and present comparative tables that categorize papers by their architectural designs and performance characteristics.
Learning to Clarify by Reinforcement Learning Through Reward-Weighted Fine-Tuning
Jun 08, 2025
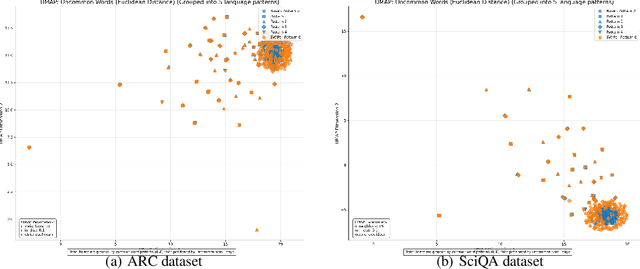


Question answering (QA) agents automatically answer questions posed in natural language. In this work, we learn to ask clarifying questions in QA agents. The key idea in our method is to simulate conversations that contain clarifying questions and learn from them using reinforcement learning (RL). To make RL practical, we propose and analyze offline RL objectives that can be viewed as reward-weighted supervised fine-tuning (SFT) and easily optimized in large language models. Our work stands in a stark contrast to recently proposed methods, based on SFT and direct preference optimization, which have additional hyper-parameters and do not directly optimize rewards. We compare to these methods empirically and report gains in both optimized rewards and language quality.
Understanding Generative AI Capabilities in Everyday Image Editing Tasks
May 22, 2025Generative AI (GenAI) holds significant promise for automating everyday image editing tasks, especially following the recent release of GPT-4o on March 25, 2025. However, what subjects do people most often want edited? What kinds of editing actions do they want to perform (e.g., removing or stylizing the subject)? Do people prefer precise edits with predictable outcomes or highly creative ones? By understanding the characteristics of real-world requests and the corresponding edits made by freelance photo-editing wizards, can we draw lessons for improving AI-based editors and determine which types of requests can currently be handled successfully by AI editors? In this paper, we present a unique study addressing these questions by analyzing 83k requests from the past 12 years (2013-2025) on the Reddit community, which collected 305k PSR-wizard edits. According to human ratings, approximately only 33% of requests can be fulfilled by the best AI editors (including GPT-4o, Gemini-2.0-Flash, SeedEdit). Interestingly, AI editors perform worse on low-creativity requests that require precise editing than on more open-ended tasks. They often struggle to preserve the identity of people and animals, and frequently make non-requested touch-ups. On the other side of the table, VLM judges (e.g., o1) perform differently from human judges and may prefer AI edits more than human edits. Code and qualitative examples are available at: https://psrdataset.github.io
LUSIFER: Language Universal Space Integration for Enhanced Multilingual Embeddings with Large Language Models
Jan 01, 2025



Recent advancements in large language models (LLMs) based embedding models have established new state-of-the-art benchmarks for text embedding tasks, particularly in dense vector-based retrieval. However, these models predominantly focus on English, leaving multilingual embedding capabilities largely unexplored. To address this limitation, we present LUSIFER, a novel zero-shot approach that adapts LLM-based embedding models for multilingual tasks without requiring multilingual supervision. LUSIFER's architecture combines a multilingual encoder, serving as a language-universal learner, with an LLM-based embedding model optimized for embedding-specific tasks. These components are seamlessly integrated through a minimal set of trainable parameters that act as a connector, effectively transferring the multilingual encoder's language understanding capabilities to the specialized embedding model. Additionally, to comprehensively evaluate multilingual embedding performance, we introduce a new benchmark encompassing 5 primary embedding tasks, 123 diverse datasets, and coverage across 14 languages. Extensive experimental results demonstrate that LUSIFER significantly enhances the multilingual performance across various embedding tasks, particularly for medium and low-resource languages, without requiring explicit multilingual training data.
GUI Agents: A Survey
Dec 18, 2024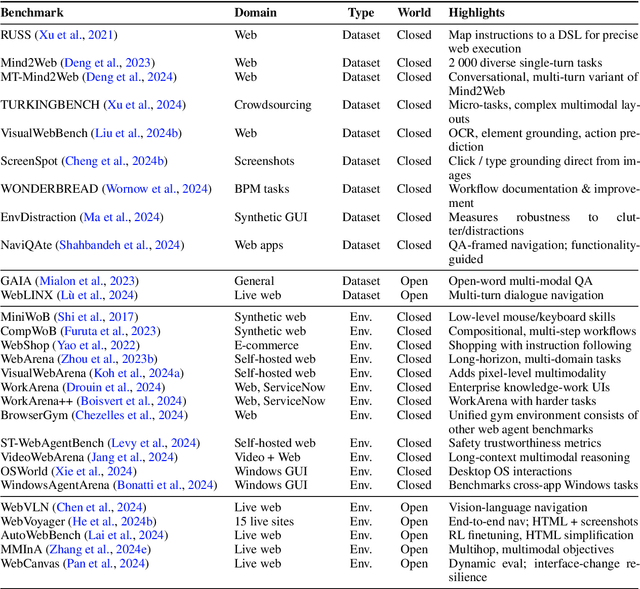
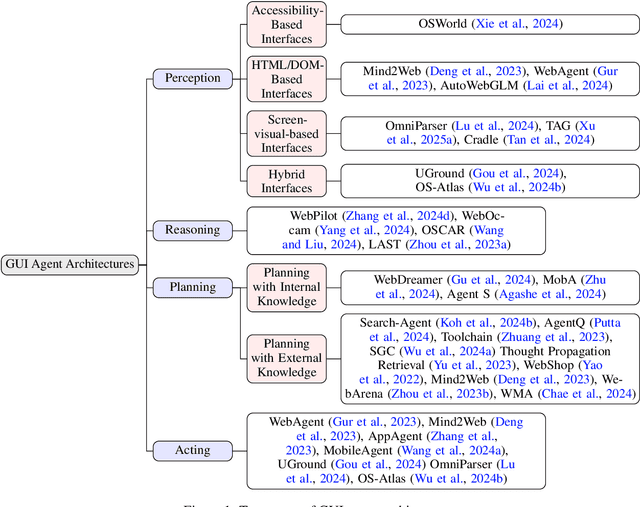

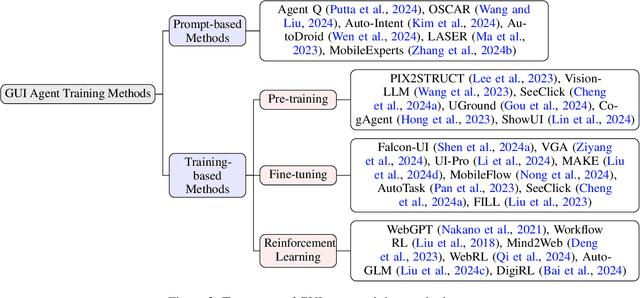
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction. These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms. Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods. We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions. Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.
SlimLM: An Efficient Small Language Model for On-Device Document Assistance
Nov 15, 2024



While small language models (SLMs) show promises for mobile deployment, their real-world performance and applications on smartphones remains underexplored. We present SlimLM, a series of SLMs optimized for document assistance tasks on mobile devices. Through extensive experiments on a Samsung Galaxy S24, we identify the optimal trade-offs between model size (ranging from 125M to 7B parameters), context length, and inference time for efficient on-device processing. SlimLM is pre-trained on SlimPajama-627B and fine-tuned on DocAssist, our constructed dataset for summarization, question answering and suggestion tasks. Our smallest model demonstrates efficient performance on S24, while larger variants offer enhanced capabilities within mobile constraints. We evaluate SlimLM against existing SLMs, showing comparable or superior performance and offering a benchmark for future research in on-device language models. We also provide an Android application, offering practical insights into SLM deployment. Our findings provide valuable insights and illuminate the capabilities of running advanced language models on high-end smartphones, potentially reducing server costs and enhancing privacy through on-device processing.
DynaSaur: Large Language Agents Beyond Predefined Actions
Nov 04, 2024


Existing LLM agent systems typically select actions from a fixed and predefined set at every step. While this approach is effective in closed, narrowly-scoped environments, we argue that it presents two major challenges when deploying LLM agents in real-world scenarios: (1) selecting from a fixed set of actions significantly restricts the planning and acting capabilities of LLM agents, and (2) this approach requires substantial human effort to enumerate and implement all possible actions, which becomes impractical in complex environments with a vast number of potential actions. In this work, we propose an LLM agent framework that enables the dynamic creation and composition of actions in an online manner. In this framework, the agent interacts with the environment by generating and executing programs written in a general-purpose programming language at each step. Furthermore, generated actions are accumulated over time for future reuse. Our extensive experiments on the GAIA benchmark demonstrate that this framework offers significantly greater flexibility and outperforms previous methods. Notably, it allows an LLM agent to recover in scenarios where no relevant action exists in the predefined set or when existing actions fail due to unforeseen edge cases. At the time of writing, we hold the top position on the GAIA public leaderboard. Our code can be found in \href{https://github.com/adobe-research/dynasaur}{https://github.com/adobe-research/dynasaur}.
Taipan: Efficient and Expressive State Space Language Models with Selective Attention
Oct 24, 2024Efficient long-context language modeling remains a significant challenge in Natural Language Processing (NLP). While Transformers dominate language tasks, they struggle with long sequences due to quadratic computational complexity in training and linearly scaling memory costs during inference. Recent State Space Models (SSMs) such as Mamba offer alternatives with constant memory usage, but they underperform in tasks requiring extensive in-context retrieval. We introduce Taipan, a novel hybrid architecture that combines Mamba-2 with Selective Attention Layers (SALs). These SALs identify tokens requiring long-range interactions, remove less important features, and then augment their representations using the attention module. This approach balances Mamba's efficiency with Transformer-like performance in memory-intensive tasks. By constraining the attention budget, Taipan extends accurate predictions to context lengths of up to 1 million tokens while preserving computational efficiency. Our experiments demonstrate Taipan's superior performance across various scales and tasks, offering a promising solution for efficient long-context language modeling.
Are Language Model Logits Calibrated?
Oct 21, 2024Some information is factual (e.g., "Paris is in France"), whereas other information is probabilistic (e.g., "the coin flip will be a [Heads/Tails]."). We believe that good Language Models (LMs) should understand and reflect this nuance. Our work investigates this by testing if LMs' output probabilities are calibrated to their textual contexts. We define model "calibration" as the degree to which the output probabilities of candidate tokens are aligned with the relative likelihood that should be inferred from the given context. For example, if the context concerns two equally likely options (e.g., heads or tails for a fair coin), the output probabilities should reflect this. Likewise, context that concerns non-uniformly likely events (e.g., rolling a six with a die) should also be appropriately captured with proportionate output probabilities. We find that even in simple settings the best LMs (1) are poorly calibrated, and (2) have systematic biases (e.g., preferred colors and sensitivities to word orderings). For example, gpt-4o-mini often picks the first of two options presented in the prompt regardless of the options' implied likelihood, whereas Llama-3.1-8B picks the second. Our other consistent finding is mode-collapse: Instruction-tuned models often over-allocate probability mass on a single option. These systematic biases introduce non-intuitive model behavior, making models harder for users to understand.