 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlimLM: An Efficient Small Language Model for On-Device Document Assistance
Nov 15, 2024



While small language models (SLMs) show promises for mobile deployment, their real-world performance and applications on smartphones remains underexplored. We present SlimLM, a series of SLMs optimized for document assistance tasks on mobile devices. Through extensive experiments on a Samsung Galaxy S24, we identify the optimal trade-offs between model size (ranging from 125M to 7B parameters), context length, and inference time for efficient on-device processing. SlimLM is pre-trained on SlimPajama-627B and fine-tuned on DocAssist, our constructed dataset for summarization, question answering and suggestion tasks. Our smallest model demonstrates efficient performance on S24, while larger variants offer enhanced capabilities within mobile constraints. We evaluate SlimLM against existing SLMs, showing comparable or superior performance and offering a benchmark for future research in on-device language models. We also provide an Android application, offering practical insights into SLM deployment. Our findings provide valuable insights and illuminate the capabilities of running advanced language models on high-end smartphones, potentially reducing server costs and enhancing privacy through on-device processing.
Taipan: Efficient and Expressive State Space Language Models with Selective Attention
Oct 24, 2024Efficient long-context language modeling remains a significant challenge in Natural Language Processing (NLP). While Transformers dominate language tasks, they struggle with long sequences due to quadratic computational complexity in training and linearly scaling memory costs during inference. Recent State Space Models (SSMs) such as Mamba offer alternatives with constant memory usage, but they underperform in tasks requiring extensive in-context retrieval. We introduce Taipan, a novel hybrid architecture that combines Mamba-2 with Selective Attention Layers (SALs). These SALs identify tokens requiring long-range interactions, remove less important features, and then augment their representations using the attention module. This approach balances Mamba's efficiency with Transformer-like performance in memory-intensive tasks. By constraining the attention budget, Taipan extends accurate predictions to context lengths of up to 1 million tokens while preserving computational efficiency. Our experiments demonstrate Taipan's superior performance across various scales and tasks, offering a promising solution for efficient long-context language modeling.
PEEB: Part-based Image Classifiers with an Explainable and Editable Language Bottleneck
Mar 08, 2024



CLIP-based classifiers rely on the prompt containing a {class name} that is known to the text encoder. That is, CLIP performs poorly on new classes or the classes whose names rarely appear on the Internet (e.g., scientific names of birds). For fine-grained classification, we propose PEEB - an explainable and editable classifier to (1) express the class name into a set of pre-defined text descriptors that describe the visual parts of that class; and (2) match the embeddings of the detected parts to their textual descriptors in each class to compute a logit score for classification. In a zero-shot setting where the class names are unknown, PEEB outperforms CLIP by a large margin (~10x in accuracy). Compared to part-based classifiers, PEEB is not only the state-of-the-art on the supervised-learning setting (88.80% accuracy) but also the first to enable users to edit the class definitions to form a new classifier without retraining. Compared to concept bottleneck models, PEEB is also the state-of-the-art in both zero-shot and supervised learning settings.
Semi-supervised Neural Machine Translation with Consistency Regularization for Low-Resource Languages
Apr 02, 2023The advent of deep learning has led to a significant gain in machine translation. However, most of the studies required a large parallel dataset which is scarce and expensive to construct and even unavailable for some languages. This paper presents a simple yet effective method to tackle this problem for low-resource languages by augmenting high-quality sentence pairs and training NMT models in a semi-supervised manner. Specifically, our approach combines the cross-entropy loss for supervised learning with KL Divergence for unsupervised fashion given pseudo and augmented target sentences derived from the model. We also introduce a SentenceBERT-based filter to enhance the quality of augmenting data by retaining semantically similar sentence pairs. Experimental results show that our approach significantly improves NMT baselines, especially on low-resource datasets with 0.46--2.03 BLEU scores. We also demonstrate that using unsupervised training for augmented data is more efficient than reusing the ground-truth target sentences for supervised learning.
PiC: A Phrase-in-Context Dataset for Phrase Understanding and Semantic Search
Jul 20, 2022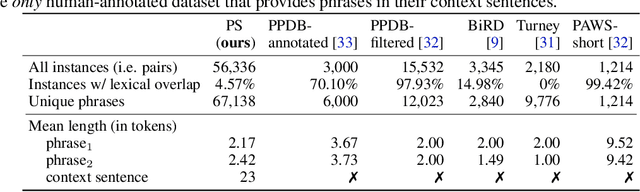

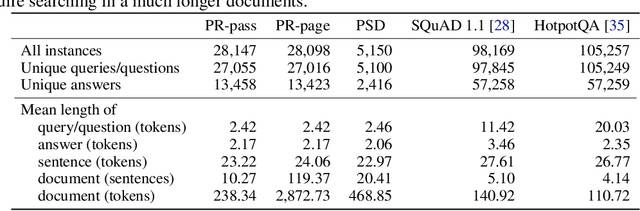

Since BERT (Devlin et al., 2018), learning contextualized word embeddings has been a de-facto standard in NLP. However, the progress of learning contextualized phrase embeddings is hindered by the lack of a human-annotated, phrase-in-context benchmark. To fill this gap, we propose PiC - a dataset of ~28K of noun phrases accompanied by their contextual Wikipedia pages and a suite of three tasks of increasing difficulty for evaluating the quality of phrase embeddings. We find that training on our dataset improves ranking models' accuracy and remarkably pushes Question Answering (QA) models to near-human accuracy which is 95% Exact Match (EM) on semantic search given a query phrase and a passage. Interestingly, we find evidence that such impressive performance is because the QA models learn to better capture the common meaning of a phrase regardless of its actual context. That is, on our Phrase Sense Disambiguation (PSD) task, SotA model accuracy drops substantially (60% EM), failing to differentiate between two different senses of the same phrase under two different contexts. Further results on our 3-task PiC benchmark reveal that learning contextualized phrase embeddings remains an interesting, open challenge.
Double Trouble: How to not explain a text classifier's decisions using counterfactuals synthesized by masked language models?
Oct 22, 2021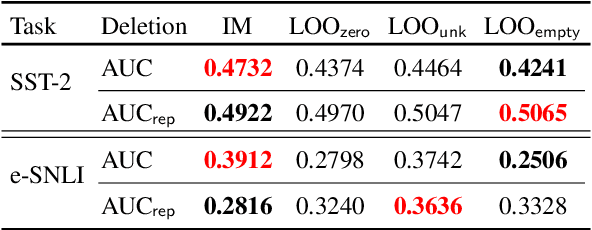
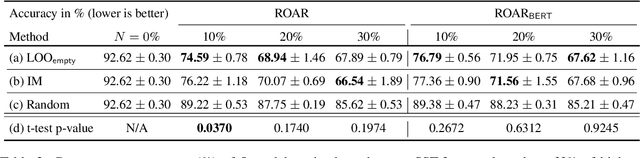

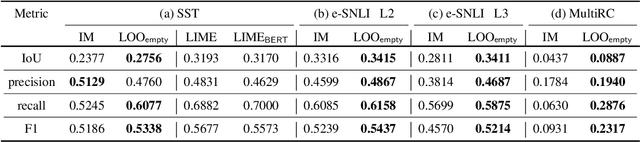
Explaining how important each input feature is to a classifier's decision is critical in high-stake applications. An underlying principle behind dozens of explanation methods is to take the prediction difference between before-and-after an input feature (here, a token) is removed as its attribution - the individual treatment effect in causal inference. A recent method called Input Marginalization (IM) (Kim et al., 2020) uses BERT to replace a token - i.e. simulating the do(.) operator - yielding more plausible counterfactuals. However, our rigorous evaluation using five metrics and on three datasets found IM explanations to be consistently more biased, less accurate, and less plausible than those derived from simply deleting a word.
Out of Order: How important is the sequential order of words in a sentence in Natural Language Understanding tasks?
Dec 30, 2020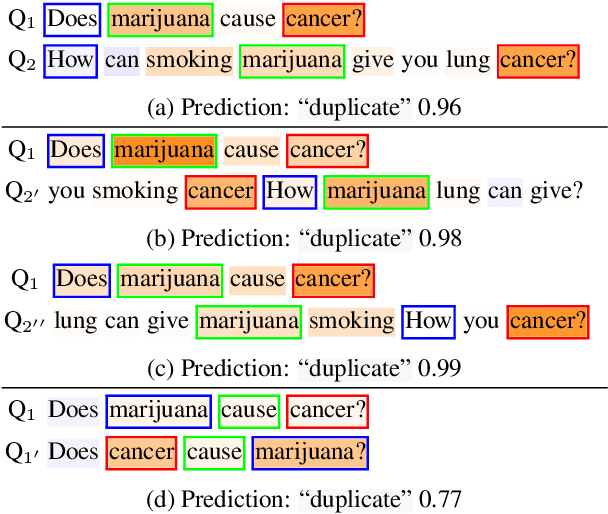

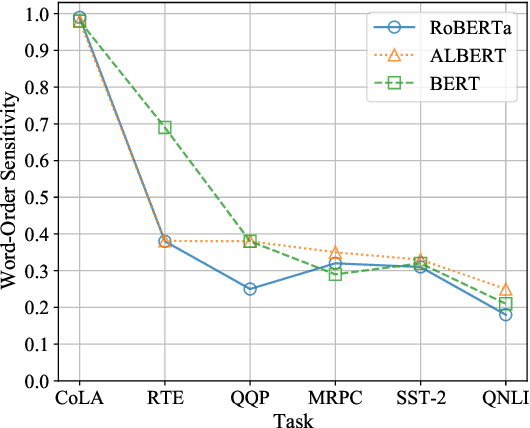
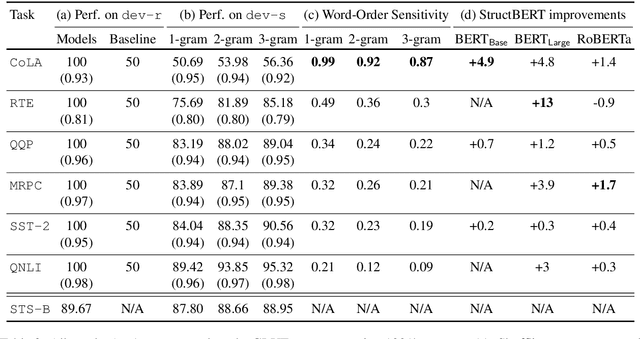
Do state-of-the-art natural language understanding models care about word order - one of the most important characteristics of a sequence? Not always! We found 75% to 90% of the correct predictions of BERT-based classifiers, trained on many GLUE tasks, remain constant after input words are randomly shuffled. Despite BERT embeddings are famously contextual, the contribution of each individual word to downstream tasks is almost unchanged even after the word's context is shuffled. BERT-based models are able to exploit superficial cues (e.g. the sentiment of keywords in sentiment analysis; or the word-wise similarity between sequence-pair inputs in natural language inference) to make correct decisions when tokens are arranged in random orders. Encouraging classifiers to capture word order information improves the performance on most GLUE tasks, SQuAD 2.0 and out-of-samples. Our work suggests that many GLUE tasks are not challenging machines to understand the meaning of a sentence.