 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementing Knowledge Representation and Reasoning with Object Oriented Design
Jan 21, 2026This paper introduces KRROOD, a framework designed to bridge the integration gap between modern software engineering and Knowledge Representation & Reasoning (KR&R) systems. While Object-Oriented Programming (OOP) is the standard for developing complex applications, existing KR&R frameworks often rely on external ontologies and specialized languages that are difficult to integrate with imperative code. KRROOD addresses this by treating knowledge as a first-class programming abstraction using native class structures, bridging the gap between the logic programming and OOP paradigms. We evaluate the system on the OWL2Bench benchmark and a human-robot task learning scenario. Experimental results show that KRROOD achieves strong performance while supporting the expressive reasoning required for real-world autonomous systems.
AI4EOSC: a Federated Cloud Platform for Artificial Intelligence in Scientific Research
Dec 18, 2025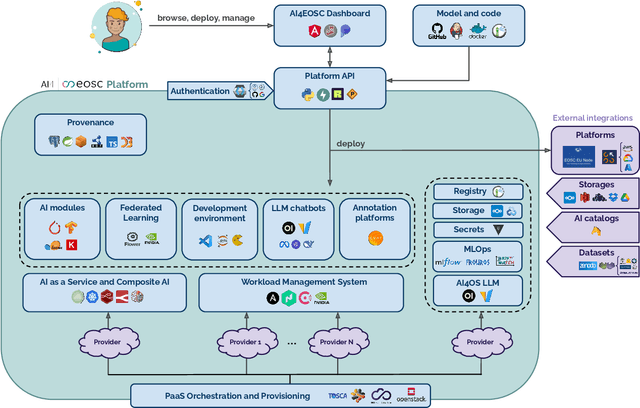
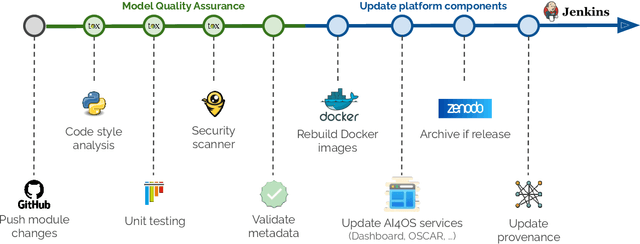
In this paper, we describe a federated compute platform dedicated to support Artificial Intelligence in scientific workloads. Putting the effort into reproducible deployments, it delivers consistent, transparent access to a federation of physically distributed e-Infrastructures. Through a comprehensive service catalogue, the platform is able to offer an integrated user experience covering the full Machine Learning lifecycle, including model development (with dedicated interactive development environments), training (with GPU resources, annotation tools, experiment tracking, and federated learning support) and deployment (covering a wide range of deployment options all along the Cloud Continuum). The platform also provides tools for traceability and reproducibility of AI models, integrates with different Artificial Intelligence model providers, datasets and storage resources, allowing users to interact with the broader Machine Learning ecosystem. Finally, it is easily customizable to lower the adoption barrier by external communities.
Generating Actionable Robot Knowledge Bases by Combining 3D Scene Graphs with Robot Ontologies
Jul 15, 2025In robotics, the effective integration of environmental data into actionable knowledge remains a significant challenge due to the variety and incompatibility of data formats commonly used in scene descriptions, such as MJCF, URDF, and SDF. This paper presents a novel approach that addresses these challenges by developing a unified scene graph model that standardizes these varied formats into the Universal Scene Description (USD) format. This standardization facilitates the integration of these scene graphs with robot ontologies through semantic reporting, enabling the translation of complex environmental data into actionable knowledge essential for cognitive robotic control. We evaluated our approach by converting procedural 3D environments into USD format, which is then annotated semantically and translated into a knowledge graph to effectively answer competency questions, demonstrating its utility for real-time robotic decision-making. Additionally, we developed a web-based visualization tool to support the semantic mapping process, providing users with an intuitive interface to manage the 3D environment.
Digital Twin Generation from Visual Data: A Survey
Apr 17, 2025This survey explores recent developments in generating digital twins from videos. Such digital twins can be used for robotics application, media content creation, or design and construction works. We analyze various approaches, including 3D Gaussian Splatting, generative in-painting, semantic segmentation, and foundation models highlighting their advantages and limitations. Additionally, we discuss challenges such as occlusions, lighting variations, and scalability, as well as potential future research directions. This survey aims to provide a comprehensive overview of state-of-the-art methodologies and their implications for real-world applications. Awesome list: https://github.com/ndrwmlnk/awesome-digital-twins
GPU-Accelerated Motion Planning of an Underactuated Forestry Crane in Cluttered Environments
Mar 18, 2025



Autonomous large-scale machine operations require fast, efficient, and collision-free motion planning while addressing unique challenges such as hydraulic actuation limits and underactuated joint dynamics. This paper presents a novel two-step motion planning framework designed for an underactuated forestry crane. The first step employs GPU-accelerated stochastic optimization to rapidly compute a globally shortest collision-free path. The second step refines this path into a dynamically feasible trajectory using a trajectory optimizer that ensures compliance with system dynamics and actuation constraints. The proposed approach is benchmarked against conventional techniques, including RRT-based methods and purely optimization-based approaches. Simulation results demonstrate substantial improvements in computation speed and motion feasibility, making this method highly suitable for complex crane systems.
Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
Allowing humans to interactively guide machines where to look does not always improve human-AI team's classification accuracy
Apr 14, 2024Via thousands of papers in Explainable AI (XAI), attention maps \cite{vaswani2017attention} and feature attribution maps \cite{bansal2020sam} have been established as a common means for finding how important each input feature is to an AI's decisions. It is an interesting, unexplored question whether allowing users to edit the feature importance at test time would improve a human-AI team's accuracy on downstream tasks. In this paper, we address this question by leveraging CHM-Corr, a state-of-the-art, ante-hoc explainable classifier \cite{taesiri2022visual} that first predicts patch-wise correspondences between the input and training-set images, and then base on them to make classification decisions. We build CHM-Corr++, an interactive interface for CHM-Corr, enabling users to edit the feature attribution map provided by CHM-Corr and observe updated model decisions. Via CHM-Corr++, users can gain insights into if, when, and how the model changes its outputs, improving their understanding beyond static explanations. However, our user study with 18 users who performed 1,400 decisions finds no statistical significance that our interactive approach improves user accuracy on CUB-200 bird image classification over static explanations. This challenges the hypothesis that interactivity can boost human-AI team accuracy~\cite{sokol2020one,sun2022exploring,shen2024towards,singh2024rethinking,mindlin2024beyond,lakkaraju2022rethinking,cheng2019explaining,liu2021understanding} and raises needs for future research. We open-source CHM-Corr++, an interactive tool for editing image classifier attention (see an interactive demo \href{http://137.184.82.109:7080/}{here}). % , and it lays the groundwork for future research to enable effective human-AI interaction in computer vision. We release code and data on \href{https://github.com/anguyen8/chm-corr-interactive}{github}.
Instance Segmentation under Occlusions via Location-aware Copy-Paste Data Augmentation
Oct 27, 2023Occlusion is a long-standing problem in computer vision, particularly in instance segmentation. ACM MMSports 2023 DeepSportRadar has introduced a dataset that focuses on segmenting human subjects within a basketball context and a specialized evaluation metric for occlusion scenarios. Given the modest size of the dataset and the highly deformable nature of the objects to be segmented, this challenge demands the application of robust data augmentation techniques and wisely-chosen deep learning architectures. Our work (ranked 1st in the competition) first proposes a novel data augmentation technique, capable of generating more training samples with wider distribution. Then, we adopt a new architecture - Hybrid Task Cascade (HTC) framework with CBNetV2 as backbone and MaskIoU head to improve segmentation performance. Furthermore, we employ a Stochastic Weight Averaging (SWA) training strategy to improve the model's generalization. As a result, we achieve a remarkable occlusion score (OM) of 0.533 on the challenge dataset, securing the top-1 position on the leaderboard. Source code is available at this https://github.com/nguyendinhson-kaist/MMSports23-Seg-AutoID.
AdvisingNets: Learning to Distinguish Correct and Wrong Classifications via Nearest-Neighbor Explanations
Aug 25, 2023Besides providing insights into how an image classifier makes its predictions, nearest-neighbor examples also help humans make more accurate decisions. Yet, leveraging this type of explanation to improve both human-AI team accuracy and classifier's accuracy remains an open question. In this paper, we aim to increase both types of accuracy by (1) comparing the input image with post-hoc, nearest-neighbor explanations using a novel network (AdvisingNet), and (2) employing a new reranking algorithm. Over different baseline models, our method consistently improves the image classification accuracy on CUB-200 and Cars-196 datasets. Interestingly, we also reach the state-of-the-art human-AI team accuracy on CUB-200 where both humans and an AdvisingNet make decisions on complementary subsets of images.
Fix Fairness, Don't Ruin Accuracy: Performance Aware Fairness Repair using AutoML
Jun 15, 2023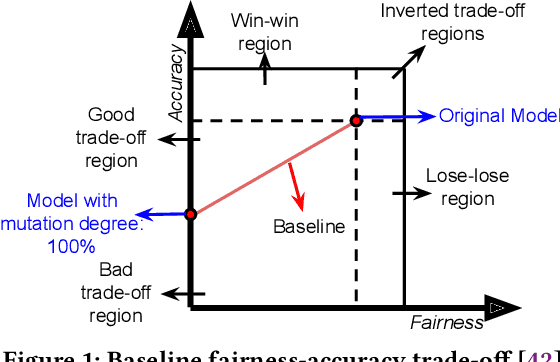

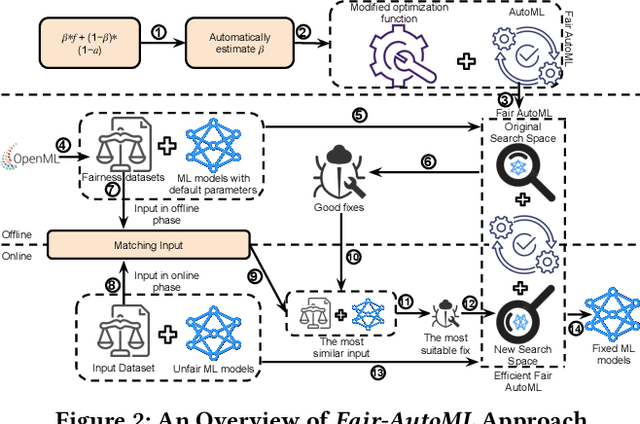
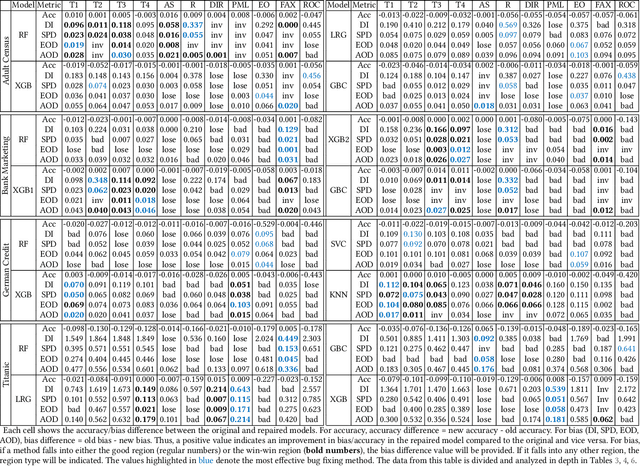
Machine learning (ML) is increasingly being used in critical decision-making software, but incidents have raised questions about the fairness of ML predictions. To address this issue, new tools and methods are needed to mitigate bias in ML-based software. Previous studies have proposed bias mitigation algorithms that only work in specific situations and often result in a loss of accuracy. Our proposed solution is a novel approach that utilizes automated machine learning (AutoML) techniques to mitigate bias. Our approach includes two key innovations: a novel optimization function and a fairness-aware search space. By improving the default optimization function of AutoML and incorporating fairness objectives, we are able to mitigate bias with little to no loss of accuracy. Additionally, we propose a fairness-aware search space pruning method for AutoML to reduce computational cost and repair time. Our approach, built on the state-of-the-art Auto-Sklearn tool, is designed to reduce bias in real-world scenarios. In order to demonstrate the effectiveness of our approach, we evaluated our approach on four fairness problems and 16 different ML models, and our results show a significant improvement over the baseline and existing bias mitigation techniques. Our approach, Fair-AutoML, successfully repaired 60 out of 64 buggy cases, while existing bias mitigation techniques only repaired up to 44 out of 64 cases.