 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaTeaming: Exploring How Introducing Personas Can Improve Automated AI Red-Teaming
Sep 03, 2025Recent developments in AI governance and safety research have called for red-teaming methods that can effectively surface potential risks posed by AI models. Many of these calls have emphasized how the identities and backgrounds of red-teamers can shape their red-teaming strategies, and thus the kinds of risks they are likely to uncover. While automated red-teaming approaches promise to complement human red-teaming by enabling larger-scale exploration of model behavior, current approaches do not consider the role of identity. As an initial step towards incorporating people's background and identities in automated red-teaming, we develop and evaluate a novel method, PersonaTeaming, that introduces personas in the adversarial prompt generation process to explore a wider spectrum of adversarial strategies. In particular, we first introduce a methodology for mutating prompts based on either "red-teaming expert" personas or "regular AI user" personas. We then develop a dynamic persona-generating algorithm that automatically generates various persona types adaptive to different seed prompts. In addition, we develop a set of new metrics to explicitly measure the "mutation distance" to complement existing diversity measurements of adversarial prompts. Our experiments show promising improvements (up to 144.1%) in the attack success rates of adversarial prompts through persona mutation, while maintaining prompt diversity, compared to RainbowPlus, a state-of-the-art automated red-teaming method. We discuss the strengths and limitations of different persona types and mutation methods, shedding light on future opportunities to explore complementarities between automated and human red-teaming approaches.
Interactivity x Explainability: Toward Understanding How Interactivity Can Improve Computer Vision Explanations
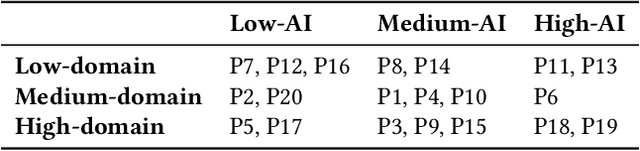
Apr 14, 2025Explanations for computer vision models are important tools for interpreting how the underlying models work. However, they are often presented in static formats, which pose challenges for users, including information overload, a gap between semantic and pixel-level information, and limited opportunities for exploration. We investigate interactivity as a mechanism for tackling these issues in three common explanation types: heatmap-based, concept-based, and prototype-based explanations. We conducted a study (N=24), using a bird identification task, involving participants with diverse technical and domain expertise. We found that while interactivity enhances user control, facilitates rapid convergence to relevant information, and allows users to expand their understanding of the model and explanation, it also introduces new challenges. To address these, we provide design recommendations for interactive computer vision explanations, including carefully selected default views, independent input controls, and constrained output spaces.
Fostering Appropriate Reliance on Large Language Models: The Role of Explanations, Sources, and Inconsistencies
Feb 12, 2025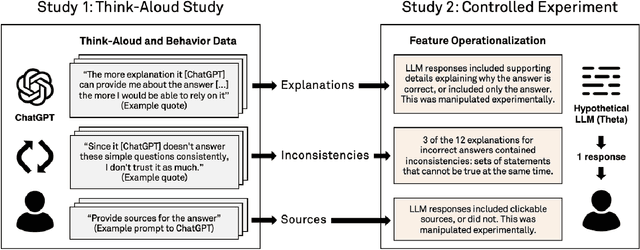
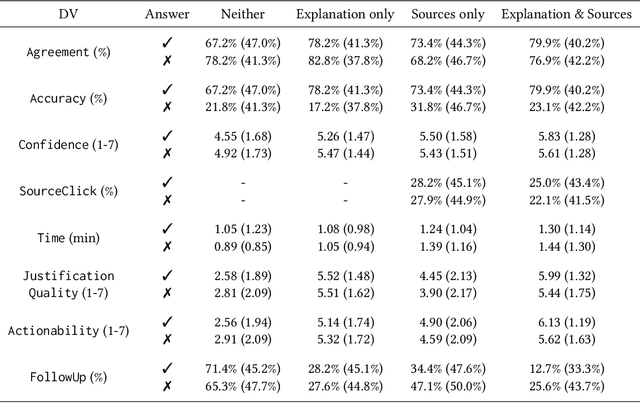
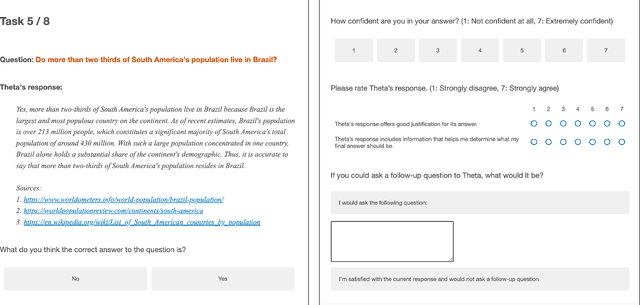

Large language models (LLMs) can produce erroneous responses that sound fluent and convincing, raising the risk that users will rely on these responses as if they were correct. Mitigating such overreliance is a key challenge. Through a think-aloud study in which participants use an LLM-infused application to answer objective questions, we identify several features of LLM responses that shape users' reliance: explanations (supporting details for answers), inconsistencies in explanations, and sources. Through a large-scale, pre-registered, controlled experiment (N=308), we isolate and study the effects of these features on users' reliance, accuracy, and other measures. We find that the presence of explanations increases reliance on both correct and incorrect responses. However, we observe less reliance on incorrect responses when sources are provided or when explanations exhibit inconsistencies. We discuss the implications of these findings for fostering appropriate reliance on LLMs.
"I'm Not Sure, But": Examining the Impact of Large Language Models' Uncertainty Expression on User Reliance and Trust
May 01, 2024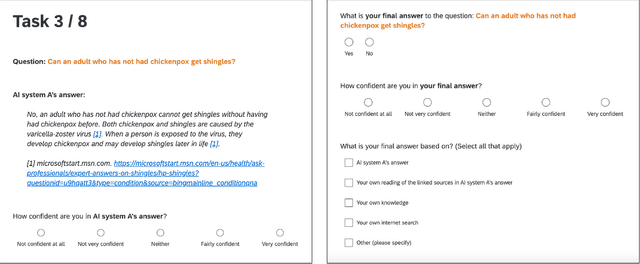
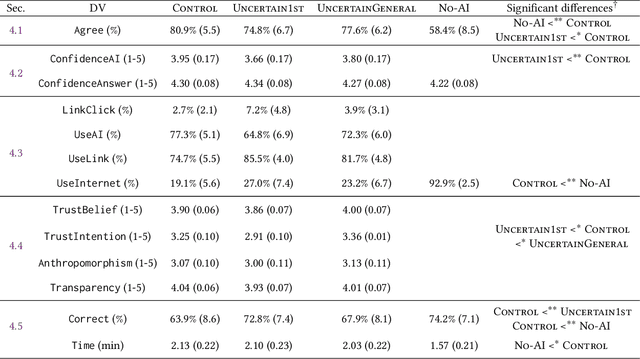
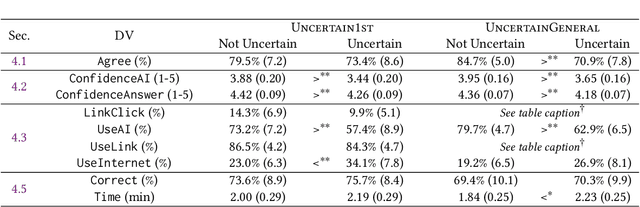
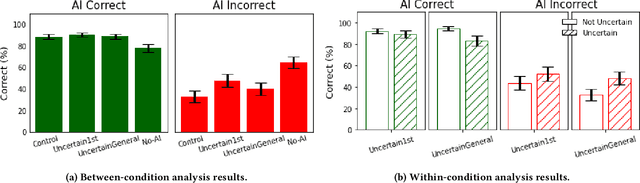
Widely deployed large language models (LLMs) can produce convincing yet incorrect outputs, potentially misleading users who may rely on them as if they were correct. To reduce such overreliance, there have been calls for LLMs to communicate their uncertainty to end users. However, there has been little empirical work examining how users perceive and act upon LLMs' expressions of uncertainty. We explore this question through a large-scale, pre-registered, human-subject experiment (N=404) in which participants answer medical questions with or without access to responses from a fictional LLM-infused search engine. Using both behavioral and self-reported measures, we examine how different natural language expressions of uncertainty impact participants' reliance, trust, and overall task performance. We find that first-person expressions (e.g., "I'm not sure, but...") decrease participants' confidence in the system and tendency to agree with the system's answers, while increasing participants' accuracy. An exploratory analysis suggests that this increase can be attributed to reduced (but not fully eliminated) overreliance on incorrect answers. While we observe similar effects for uncertainty expressed from a general perspective (e.g., "It's not clear, but..."), these effects are weaker and not statistically significant. Our findings suggest that using natural language expressions of uncertainty may be an effective approach for reducing overreliance on LLMs, but that the precise language used matters. This highlights the importance of user testing before deploying LLMs at scale.
Allowing humans to interactively guide machines where to look does not always improve human-AI team's classification accuracy
Apr 14, 2024Via thousands of papers in Explainable AI (XAI), attention maps \cite{vaswani2017attention} and feature attribution maps \cite{bansal2020sam} have been established as a common means for finding how important each input feature is to an AI's decisions. It is an interesting, unexplored question whether allowing users to edit the feature importance at test time would improve a human-AI team's accuracy on downstream tasks. In this paper, we address this question by leveraging CHM-Corr, a state-of-the-art, ante-hoc explainable classifier \cite{taesiri2022visual} that first predicts patch-wise correspondences between the input and training-set images, and then base on them to make classification decisions. We build CHM-Corr++, an interactive interface for CHM-Corr, enabling users to edit the feature attribution map provided by CHM-Corr and observe updated model decisions. Via CHM-Corr++, users can gain insights into if, when, and how the model changes its outputs, improving their understanding beyond static explanations. However, our user study with 18 users who performed 1,400 decisions finds no statistical significance that our interactive approach improves user accuracy on CUB-200 bird image classification over static explanations. This challenges the hypothesis that interactivity can boost human-AI team accuracy~\cite{sokol2020one,sun2022exploring,shen2024towards,singh2024rethinking,mindlin2024beyond,lakkaraju2022rethinking,cheng2019explaining,liu2021understanding} and raises needs for future research. We open-source CHM-Corr++, an interactive tool for editing image classifier attention (see an interactive demo \href{http://137.184.82.109:7080/}{here}). % , and it lays the groundwork for future research to enable effective human-AI interaction in computer vision. We release code and data on \href{https://github.com/anguyen8/chm-corr-interactive}{github}.
WiCV@CVPR2023: The Eleventh Women In Computer Vision Workshop at the Annual CVPR Conference
Sep 22, 2023In this paper, we present the details of Women in Computer Vision Workshop - WiCV 2023, organized alongside the hybrid CVPR 2023 in Vancouver, Canada. WiCV aims to amplify the voices of underrepresented women in the computer vision community, fostering increased visibility in both academia and industry. We believe that such events play a vital role in addressing gender imbalances within the field. The annual WiCV@CVPR workshop offers a) opportunity for collaboration between researchers from minority groups, b) mentorship for female junior researchers, c) financial support to presenters to alleviate finanacial burdens and d) a diverse array of role models who can inspire younger researchers at the outset of their careers. In this paper, we present a comprehensive report on the workshop program, historical trends from the past WiCV@CVPR events, and a summary of statistics related to presenters, attendees, and sponsorship for the WiCV 2023 workshop.
Humans, AI, and Context: Understanding End-Users' Trust in a Real-World Computer Vision Application
May 15, 2023



Trust is an important factor in people's interactions with AI systems. However, there is a lack of empirical studies examining how real end-users trust or distrust the AI system they interact with. Most research investigates one aspect of trust in lab settings with hypothetical end-users. In this paper, we provide a holistic and nuanced understanding of trust in AI through a qualitative case study of a real-world computer vision application. We report findings from interviews with 20 end-users of a popular, AI-based bird identification app where we inquired about their trust in the app from many angles. We find participants perceived the app as trustworthy and trusted it, but selectively accepted app outputs after engaging in verification behaviors, and decided against app adoption in certain high-stakes scenarios. We also find domain knowledge and context are important factors for trust-related assessment and decision-making. We discuss the implications of our findings and provide recommendations for future research on trust in AI.
UFO: A unified method for controlling Understandability and Faithfulness Objectives in concept-based explanations for CNNs
Mar 27, 2023



Concept-based explanations for convolutional neural networks (CNNs) aim to explain model behavior and outputs using a pre-defined set of semantic concepts (e.g., the model recognizes scene class ``bedroom'' based on the presence of concepts ``bed'' and ``pillow''). However, they often do not faithfully (i.e., accurately) characterize the model's behavior and can be too complex for people to understand. Further, little is known about how faithful and understandable different explanation methods are, and how to control these two properties. In this work, we propose UFO, a unified method for controlling Understandability and Faithfulness Objectives in concept-based explanations. UFO formalizes understandability and faithfulness as mathematical objectives and unifies most existing concept-based explanations methods for CNNs. Using UFO, we systematically investigate how explanations change as we turn the knobs of faithfulness and understandability. Our experiments demonstrate a faithfulness-vs-understandability tradeoff: increasing understandability reduces faithfulness. We also provide insights into the ``disagreement problem'' in explainable machine learning, by analyzing when and how concept-based explanations disagree with each other.
"Help Me Help the AI": Understanding How Explainability Can Support Human-AI Interaction
Oct 02, 2022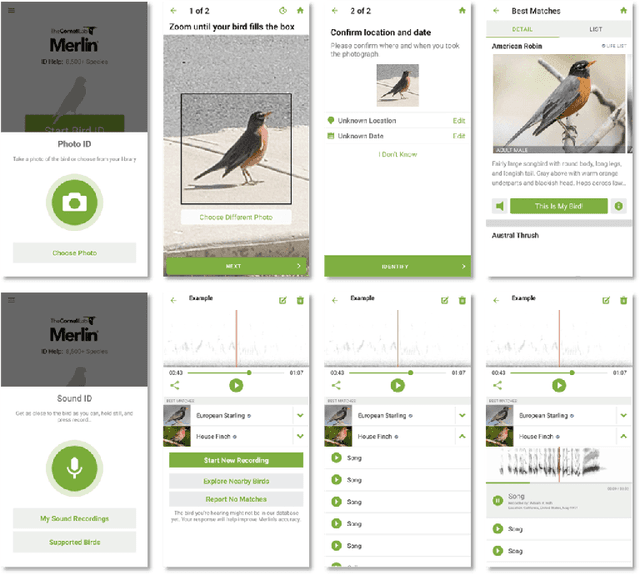

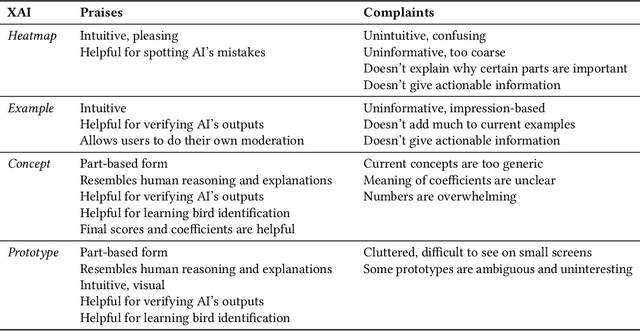
Despite the proliferation of explainable AI (XAI) methods, little is understood about end-users' explainability needs. This gap is critical, because end-users may have needs that XAI methods should but don't yet support. To address this gap and contribute to understanding how explainability can support human-AI interaction, we conducted a study of a real-world AI application via interviews with 20 end-users of Merlin, a bird-identification app. We found that people express a need for practically useful information that can improve their collaboration with the AI system, and intend to use XAI explanations for calibrating trust, improving their task skills, changing their behavior to supply better inputs to the AI system, and giving constructive feedback to developers. We also assessed end-users' perceptions of existing XAI approaches, finding that they prefer part-based explanations. Finally, we discuss implications of our findings and provide recommendations for future designs of XAI, specifically XAI for human-AI collaboration.
Overlooked factors in concept-based explanations: Dataset choice, concept salience, and human capability
Jul 20, 2022

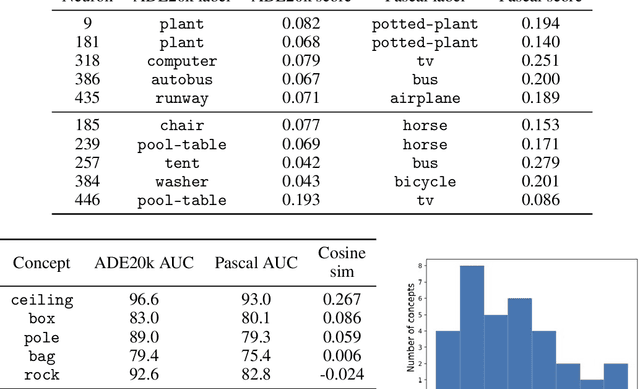
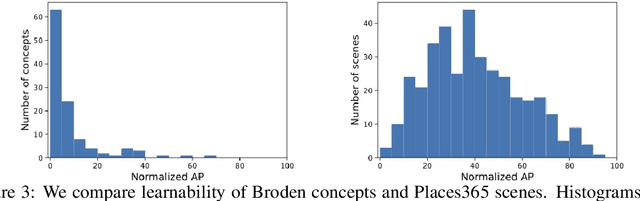
Concept-based interpretability methods aim to explain deep neural network model predictions using a predefined set of semantic concepts. These methods evaluate a trained model on a new, "probe" dataset and correlate model predictions with the visual concepts labeled in that dataset. Despite their popularity, they suffer from limitations that are not well-understood and articulated by the literature. In this work, we analyze three commonly overlooked factors in concept-based explanations. First, the choice of the probe dataset has a profound impact on the generated explanations. Our analysis reveals that different probe datasets may lead to very different explanations, and suggests that the explanations are not generalizable outside the probe dataset. Second, we find that concepts in the probe dataset are often less salient and harder to learn than the classes they claim to explain, calling into question the correctness of the explanations. We argue that only visually salient concepts should be used in concept-based explanations. Finally, while existing methods use hundreds or even thousands of concepts, our human studies reveal a much stricter upper bound of 32 concepts or less, beyond which the explanations are much less practically useful. We make suggestions for future development and analysis of concept-based interpretability methods. Code for our analysis and user interface can be found at \url{https://github.com/princetonvisualai/OverlookedFactors}