 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractivity x Explainability: Toward Understanding How Interactivity Can Improve Computer Vision Explanations
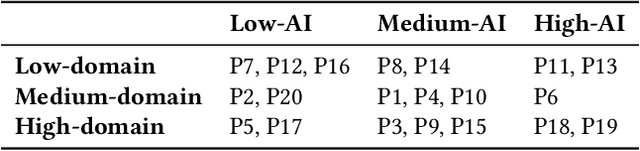
Apr 14, 2025Explanations for computer vision models are important tools for interpreting how the underlying models work. However, they are often presented in static formats, which pose challenges for users, including information overload, a gap between semantic and pixel-level information, and limited opportunities for exploration. We investigate interactivity as a mechanism for tackling these issues in three common explanation types: heatmap-based, concept-based, and prototype-based explanations. We conducted a study (N=24), using a bird identification task, involving participants with diverse technical and domain expertise. We found that while interactivity enhances user control, facilitates rapid convergence to relevant information, and allows users to expand their understanding of the model and explanation, it also introduces new challenges. To address these, we provide design recommendations for interactive computer vision explanations, including carefully selected default views, independent input controls, and constrained output spaces.
Humans, AI, and Context: Understanding End-Users' Trust in a Real-World Computer Vision Application
May 15, 2023



Trust is an important factor in people's interactions with AI systems. However, there is a lack of empirical studies examining how real end-users trust or distrust the AI system they interact with. Most research investigates one aspect of trust in lab settings with hypothetical end-users. In this paper, we provide a holistic and nuanced understanding of trust in AI through a qualitative case study of a real-world computer vision application. We report findings from interviews with 20 end-users of a popular, AI-based bird identification app where we inquired about their trust in the app from many angles. We find participants perceived the app as trustworthy and trusted it, but selectively accepted app outputs after engaging in verification behaviors, and decided against app adoption in certain high-stakes scenarios. We also find domain knowledge and context are important factors for trust-related assessment and decision-making. We discuss the implications of our findings and provide recommendations for future research on trust in AI.
UFO: A unified method for controlling Understandability and Faithfulness Objectives in concept-based explanations for CNNs
Mar 27, 2023



Concept-based explanations for convolutional neural networks (CNNs) aim to explain model behavior and outputs using a pre-defined set of semantic concepts (e.g., the model recognizes scene class ``bedroom'' based on the presence of concepts ``bed'' and ``pillow''). However, they often do not faithfully (i.e., accurately) characterize the model's behavior and can be too complex for people to understand. Further, little is known about how faithful and understandable different explanation methods are, and how to control these two properties. In this work, we propose UFO, a unified method for controlling Understandability and Faithfulness Objectives in concept-based explanations. UFO formalizes understandability and faithfulness as mathematical objectives and unifies most existing concept-based explanations methods for CNNs. Using UFO, we systematically investigate how explanations change as we turn the knobs of faithfulness and understandability. Our experiments demonstrate a faithfulness-vs-understandability tradeoff: increasing understandability reduces faithfulness. We also provide insights into the ``disagreement problem'' in explainable machine learning, by analyzing when and how concept-based explanations disagree with each other.
Interactive Visual Feature Search
Nov 28, 2022



Many visualization techniques have been created to help explain the behavior of convolutional neural networks (CNNs), but they largely consist of static diagrams that convey limited information. Interactive visualizations can provide more rich insights and allow users to more easily explore a model's behavior; however, they are typically not easily reusable and are specific to a particular model. We introduce Visual Feature Search, a novel interactive visualization that is generalizable to any CNN and can easily be incorporated into a researcher's workflow. Our tool allows a user to highlight an image region and search for images from a given dataset with the most similar CNN features. It supports searching through large image datasets with an efficient cache-based search implementation. We demonstrate how our tool elucidates different aspects of model behavior by performing experiments on supervised, self-supervised, and human-edited CNNs. We also release a portable Python library and several IPython notebooks to enable researchers to easily use our tool in their own experiments. Our code can be found at https://github.com/lookingglasslab/VisualFeatureSearch.
Improving Fine-Grain Segmentation via Interpretable Modifications: A Case Study in Fossil Segmentation
Oct 08, 2022
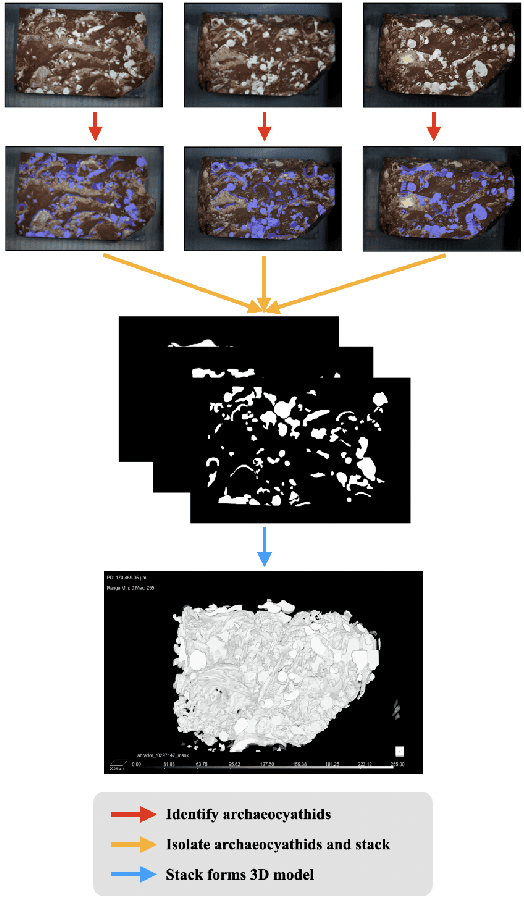
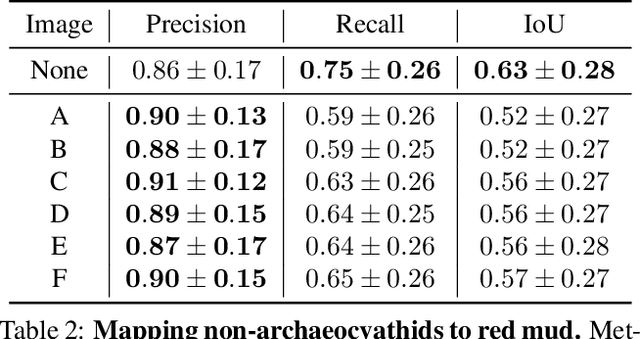
Most interpretability research focuses on datasets containing thousands of images of commonplace objects. However, many high-impact datasets, such as those in medicine and the geosciences, contain fine-grain objects that require domain-expert knowledge to recognize and are time-consuming to collect and annotate. As a result, these datasets contain few annotated images, and current machine vision models cannot train intensively on them. Thus, adapting interpretability techniques to maximize the amount of information that models can learn from small, fine-grain datasets is an important endeavor. Using a Mask R-CNN to segment ancient reef fossils in rock sample images, we present a general paradigm for identifying and mitigating model weaknesses. Specifically, we apply image perturbations to expose the Mask R-CNN's inability to distinguish between different classes of fossils and its inconsistency in segmenting fossils with different textures. To address these shortcomings, we extend an existing model-editing method for correcting systematic mistakes in image classification to image segmentation and introduce a novel application of the technique: encouraging a greater separation between positive and negative pixels for a given class. Through extensive experiments, we find that editing the model by perturbing all pixels for a given class in one image is most effective (compared to using multiple images and/or fewer pixels). Our paradigm may also generalize to other segmentation models trained on small, fine-grain datasets.
"Help Me Help the AI": Understanding How Explainability Can Support Human-AI Interaction
Oct 02, 2022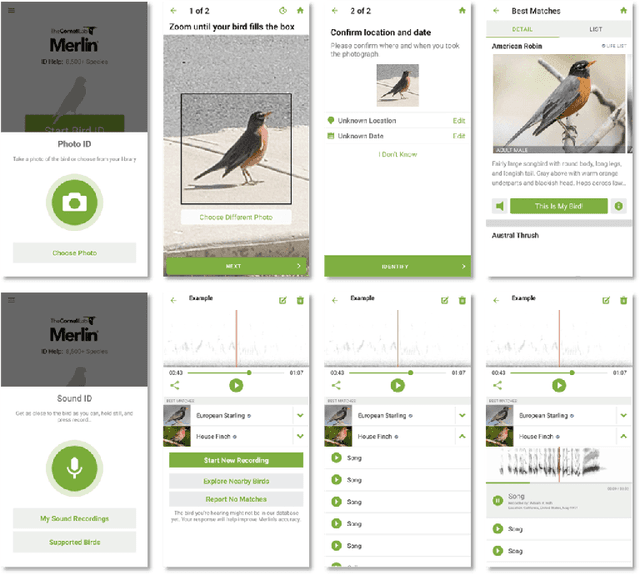

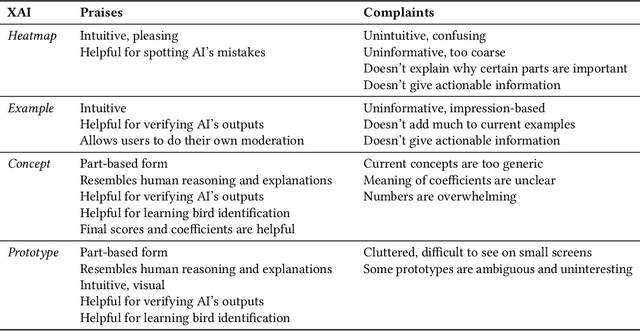
Despite the proliferation of explainable AI (XAI) methods, little is understood about end-users' explainability needs. This gap is critical, because end-users may have needs that XAI methods should but don't yet support. To address this gap and contribute to understanding how explainability can support human-AI interaction, we conducted a study of a real-world AI application via interviews with 20 end-users of Merlin, a bird-identification app. We found that people express a need for practically useful information that can improve their collaboration with the AI system, and intend to use XAI explanations for calibrating trust, improving their task skills, changing their behavior to supply better inputs to the AI system, and giving constructive feedback to developers. We also assessed end-users' perceptions of existing XAI approaches, finding that they prefer part-based explanations. Finally, we discuss implications of our findings and provide recommendations for future designs of XAI, specifically XAI for human-AI collaboration.
Overlooked factors in concept-based explanations: Dataset choice, concept salience, and human capability
Jul 20, 2022

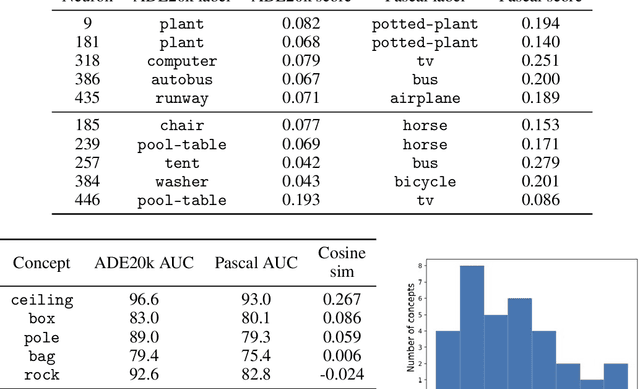
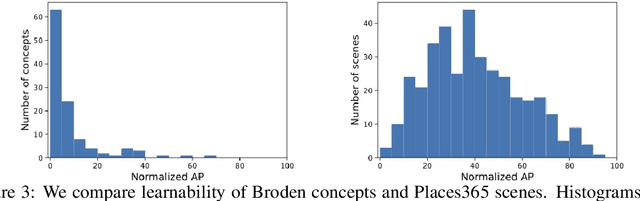
Concept-based interpretability methods aim to explain deep neural network model predictions using a predefined set of semantic concepts. These methods evaluate a trained model on a new, "probe" dataset and correlate model predictions with the visual concepts labeled in that dataset. Despite their popularity, they suffer from limitations that are not well-understood and articulated by the literature. In this work, we analyze three commonly overlooked factors in concept-based explanations. First, the choice of the probe dataset has a profound impact on the generated explanations. Our analysis reveals that different probe datasets may lead to very different explanations, and suggests that the explanations are not generalizable outside the probe dataset. Second, we find that concepts in the probe dataset are often less salient and harder to learn than the classes they claim to explain, calling into question the correctness of the explanations. We argue that only visually salient concepts should be used in concept-based explanations. Finally, while existing methods use hundreds or even thousands of concepts, our human studies reveal a much stricter upper bound of 32 concepts or less, beyond which the explanations are much less practically useful. We make suggestions for future development and analysis of concept-based interpretability methods. Code for our analysis and user interface can be found at \url{https://github.com/princetonvisualai/OverlookedFactors}
Gender Artifacts in Visual Datasets
Jun 18, 2022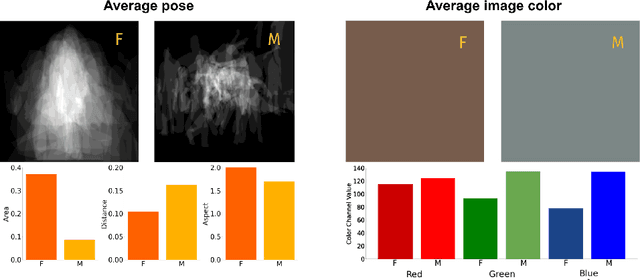

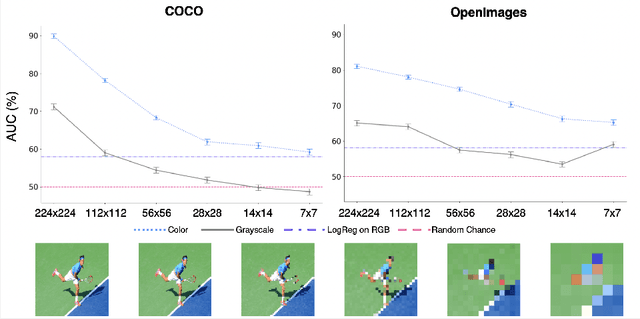
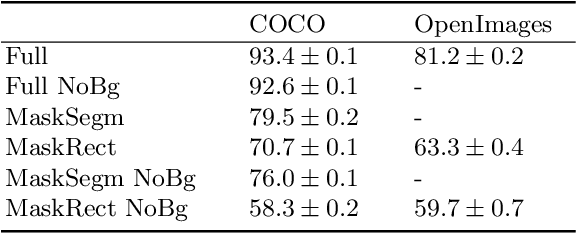
Gender biases are known to exist within large-scale visual datasets and can be reflected or even amplified in downstream models. Many prior works have proposed methods for mitigating gender biases, often by attempting to remove gender expression information from images. To understand the feasibility and practicality of these approaches, we investigate what $\textit{gender artifacts}$ exist within large-scale visual datasets. We define a $\textit{gender artifact}$ as a visual cue that is correlated with gender, focusing specifically on those cues that are learnable by a modern image classifier and have an interpretable human corollary. Through our analyses, we find that gender artifacts are ubiquitous in the COCO and OpenImages datasets, occurring everywhere from low-level information (e.g., the mean value of the color channels) to the higher-level composition of the image (e.g., pose and location of people). Given the prevalence of gender artifacts, we claim that attempts to remove gender artifacts from such datasets are largely infeasible. Instead, the responsibility lies with researchers and practitioners to be aware that the distribution of images within datasets is highly gendered and hence develop methods which are robust to these distributional shifts across groups.
ELUDE: Generating interpretable explanations via a decomposition into labelled and unlabelled features
Jun 16, 2022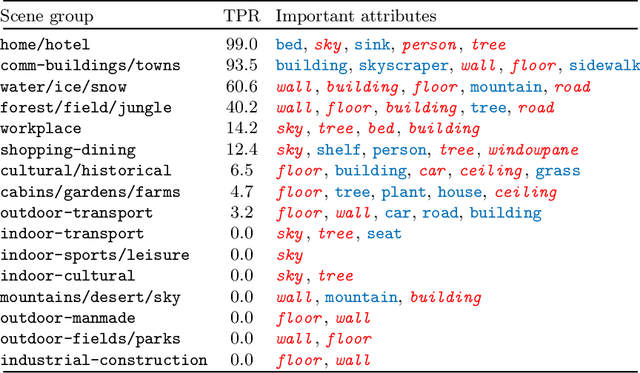
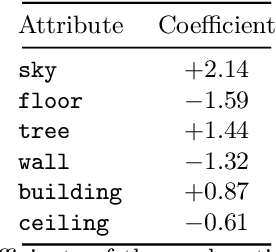
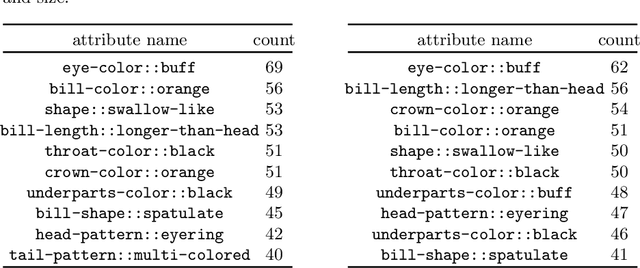

Deep learning models have achieved remarkable success in different areas of machine learning over the past decade; however, the size and complexity of these models make them difficult to understand. In an effort to make them more interpretable, several recent works focus on explaining parts of a deep neural network through human-interpretable, semantic attributes. However, it may be impossible to completely explain complex models using only semantic attributes. In this work, we propose to augment these attributes with a small set of uninterpretable features. Specifically, we develop a novel explanation framework ELUDE (Explanation via Labelled and Unlabelled DEcomposition) that decomposes a model's prediction into two parts: one that is explainable through a linear combination of the semantic attributes, and another that is dependent on the set of uninterpretable features. By identifying the latter, we are able to analyze the "unexplained" portion of the model, obtaining insights into the information used by the model. We show that the set of unlabelled features can generalize to multiple models trained with the same feature space and compare our work to two popular attribute-oriented methods, Interpretable Basis Decomposition and Concept Bottleneck, and discuss the additional insights ELUDE provides.
HIVE: Evaluating the Human Interpretability of Visual Explanations
Jan 10, 2022
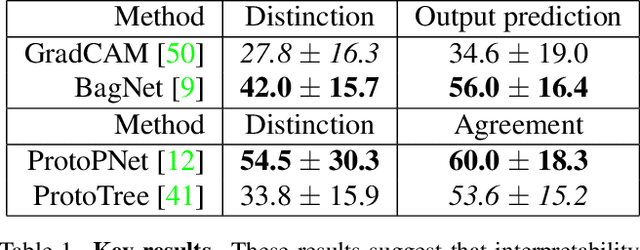

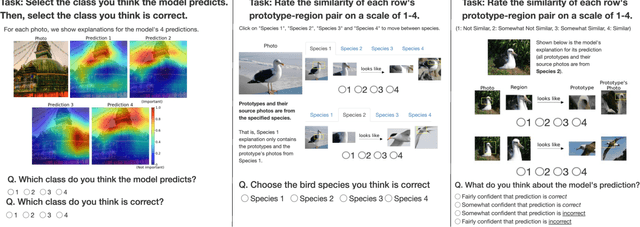
As machine learning is increasingly applied to high-impact, high-risk domains, there have been a number of new methods aimed at making AI models more human interpretable. Despite the recent growth of interpretability work, there is a lack of systematic evaluation of proposed techniques. In this work, we propose a novel human evaluation framework HIVE (Human Interpretability of Visual Explanations) for diverse interpretability methods in computer vision; to the best of our knowledge, this is the first work of its kind. We argue that human studies should be the gold standard in properly evaluating how interpretable a method is to human users. While human studies are often avoided due to challenges associated with cost, study design, and cross-method comparison, we describe how our framework mitigates these issues and conduct IRB-approved studies of four methods that represent the diversity of interpretability works: GradCAM, BagNet, ProtoPNet, and ProtoTree. Our results suggest that explanations (regardless of if they are actually correct) engender human trust, yet are not distinct enough for users to distinguish between correct and incorrect predictions. Lastly, we also open-source our framework to enable future studies and to encourage more human-centered approaches to interpretability.