 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperationalizing Pluralistic Values in Large Language Model Alignment Reveals Trade-offs in Safety, Inclusivity, and Model Behavior
Nov 18, 2025Although large language models (LLMs) are increasingly trained using human feedback for safety and alignment with human values, alignment decisions often overlook human social diversity. This study examines how incorporating pluralistic values affects LLM behavior by systematically evaluating demographic variation and design parameters in the alignment pipeline. We collected alignment data from US and German participants (N = 1,095, 27,375 ratings) who rated LLM responses across five dimensions: Toxicity, Emotional Awareness (EA), Sensitivity, Stereotypical Bias, and Helpfulness. We fine-tuned multiple Large Language Models and Large Reasoning Models using preferences from different social groups while varying rating scales, disagreement handling methods, and optimization techniques. The results revealed systematic demographic effects: male participants rated responses 18% less toxic than female participants; conservative and Black participants rated responses 27.9% and 44% more emotionally aware than liberal and White participants, respectively. Models fine-tuned on group-specific preferences exhibited distinct behaviors. Technical design choices showed strong effects: the preservation of rater disagreement achieved roughly 53% greater toxicity reduction than majority voting, and 5-point scales yielded about 22% more reduction than binary formats; and Direct Preference Optimization (DPO) consistently outperformed Group Relative Policy Optimization (GRPO) in multi-value optimization. These findings represent a preliminary step in answering a critical question: How should alignment balance expert-driven and user-driven signals to ensure both safety and fair representation?
Position: Measure Dataset Diversity, Don't Just Claim It
Jul 11, 2024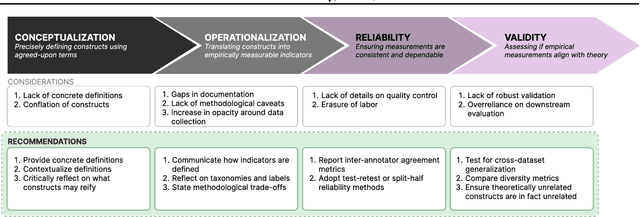
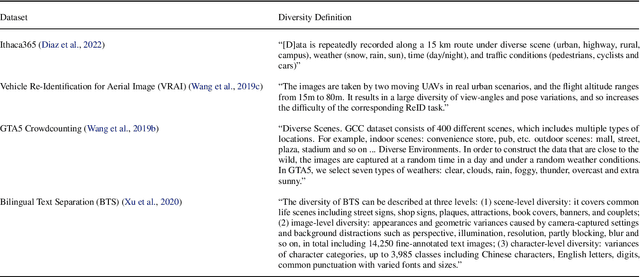
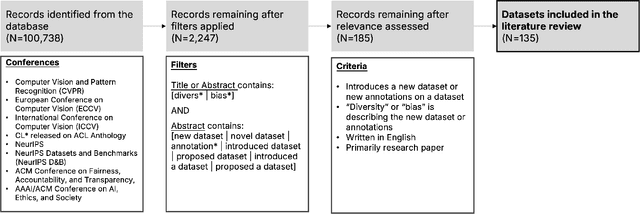
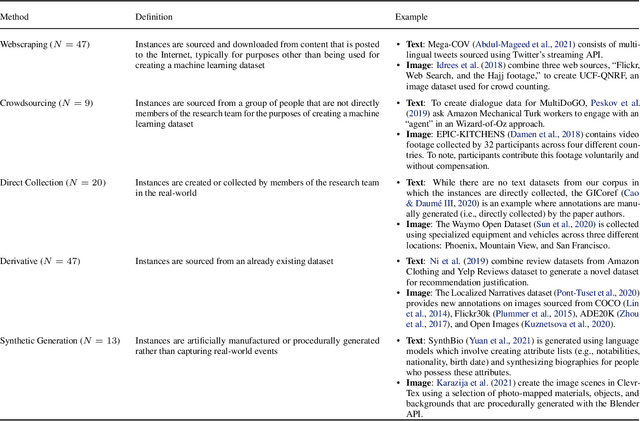
Machine learning (ML) datasets, often perceived as neutral, inherently encapsulate abstract and disputed social constructs. Dataset curators frequently employ value-laden terms such as diversity, bias, and quality to characterize datasets. Despite their prevalence, these terms lack clear definitions and validation. Our research explores the implications of this issue by analyzing "diversity" across 135 image and text datasets. Drawing from social sciences, we apply principles from measurement theory to identify considerations and offer recommendations for conceptualizing, operationalizing, and evaluating diversity in datasets. Our findings have broader implications for ML research, advocating for a more nuanced and precise approach to handling value-laden properties in dataset construction.
Resampled Datasets Are Not Enough: Mitigating Societal Bias Beyond Single Attributes
Jul 04, 2024
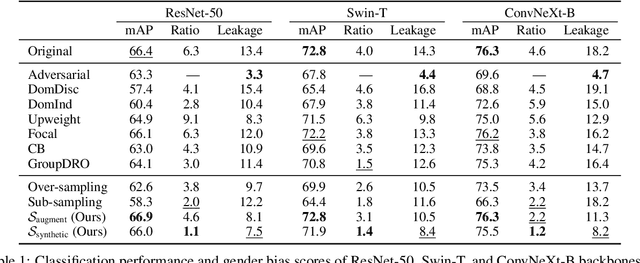
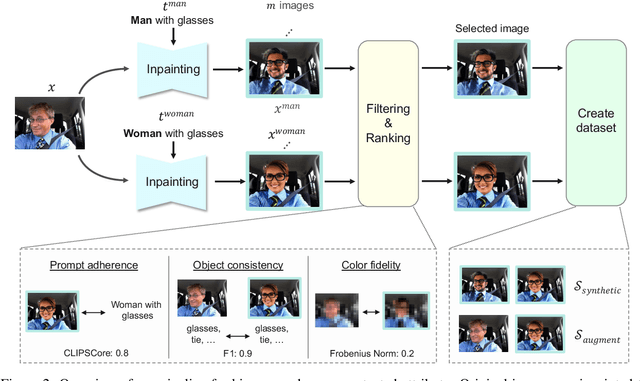
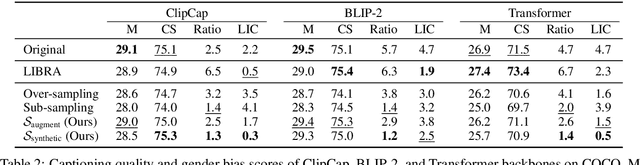
We tackle societal bias in image-text datasets by removing spurious correlations between protected groups and image attributes. Traditional methods only target labeled attributes, ignoring biases from unlabeled ones. Using text-guided inpainting models, our approach ensures protected group independence from all attributes and mitigates inpainting biases through data filtering. Evaluations on multi-label image classification and image captioning tasks show our method effectively reduces bias without compromising performance across various models.
A Taxonomy of Challenges to Curating Fair Datasets
Jun 10, 2024Despite extensive efforts to create fairer machine learning (ML) datasets, there remains a limited understanding of the practical aspects of dataset curation. Drawing from interviews with 30 ML dataset curators, we present a comprehensive taxonomy of the challenges and trade-offs encountered throughout the dataset curation lifecycle. Our findings underscore overarching issues within the broader fairness landscape that impact data curation. We conclude with recommendations aimed at fostering systemic changes to better facilitate fair dataset curation practices.
Ethical Considerations for Collecting Human-Centric Image Datasets
Feb 07, 2023
Human-centric image datasets are critical to the development of computer vision technologies. However, recent investigations have foregrounded significant ethical issues related to privacy and bias, which have resulted in the complete retraction, or modification, of several prominent datasets. Recent works have tried to reverse this trend, for example, by proposing analytical frameworks for ethically evaluating datasets, the standardization of dataset documentation and curation practices, privacy preservation methodologies, as well as tools for surfacing and mitigating representational biases. Little attention, however, has been paid to the realities of operationalizing ethical data collection. To fill this gap, we present a set of key ethical considerations and practical recommendations for collecting more ethically-minded human-centric image data. Our research directly addresses issues of privacy and bias by contributing to the research community best practices for ethical data collection, covering purpose, privacy and consent, as well as diversity. We motivate each consideration by drawing on lessons from current practices, dataset withdrawals and audits, and analytical ethical frameworks. Our research is intended to augment recent scholarship, representing an important step toward more responsible data curation practices.
Beyond web-scraping: Crowd-sourcing a geographically diverse image dataset
Jan 05, 2023



Current dataset collection methods typically scrape large amounts of data from the web. While this technique is extremely scalable, data collected in this way tends to reinforce stereotypical biases, can contain personally identifiable information, and typically originates from Europe and North America. In this work, we rethink the dataset collection paradigm and introduce GeoDE, a geographically diverse dataset with 61,940 images from 40 classes and 6 world regions, and no personally identifiable information, collected through crowd-sourcing. We analyse GeoDE to understand differences in images collected in this manner compared to web-scraping. Despite the smaller size of this dataset, we demonstrate its use as both an evaluation and training dataset, highlight shortcomings in current models, as well as show improved performances when even small amounts of GeoDE (1000 - 2000 images per region) are added to a training dataset. We release the full dataset and code at https://geodiverse-data-collection.cs.princeton.edu/
Gender Artifacts in Visual Datasets
Jun 18, 2022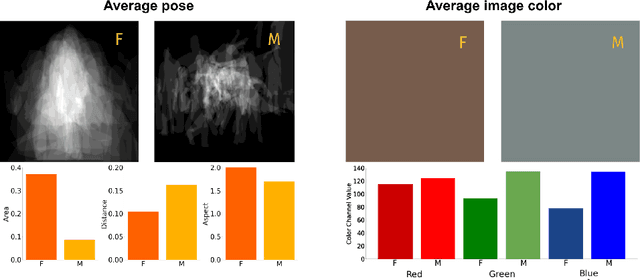

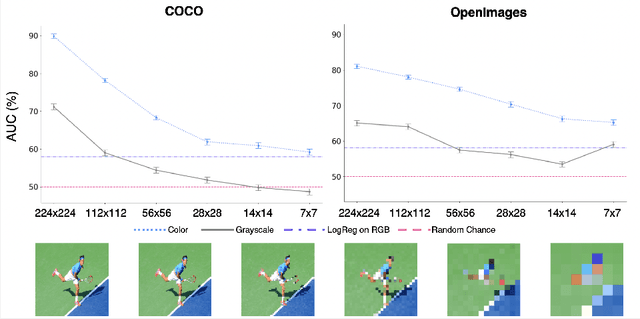
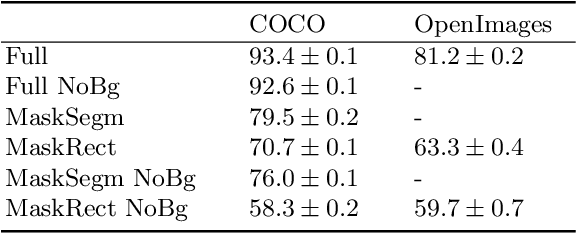
Gender biases are known to exist within large-scale visual datasets and can be reflected or even amplified in downstream models. Many prior works have proposed methods for mitigating gender biases, often by attempting to remove gender expression information from images. To understand the feasibility and practicality of these approaches, we investigate what $\textit{gender artifacts}$ exist within large-scale visual datasets. We define a $\textit{gender artifact}$ as a visual cue that is correlated with gender, focusing specifically on those cues that are learnable by a modern image classifier and have an interpretable human corollary. Through our analyses, we find that gender artifacts are ubiquitous in the COCO and OpenImages datasets, occurring everywhere from low-level information (e.g., the mean value of the color channels) to the higher-level composition of the image (e.g., pose and location of people). Given the prevalence of gender artifacts, we claim that attempts to remove gender artifacts from such datasets are largely infeasible. Instead, the responsibility lies with researchers and practitioners to be aware that the distribution of images within datasets is highly gendered and hence develop methods which are robust to these distributional shifts across groups.
Understanding and Evaluating Racial Biases in Image Captioning
Jun 16, 2021



Image captioning is an important task for benchmarking visual reasoning and for enabling accessibility for people with vision impairments. However, as in many machine learning settings, social biases can influence image captioning in undesirable ways. In this work, we study bias propagation pathways within image captioning, focusing specifically on the COCO dataset. Prior work has analyzed gender bias in captions using automatically-derived gender labels; here we examine racial and intersectional biases using manual annotations. Our first contribution is in annotating the perceived gender and skin color of 28,315 of the depicted people after obtaining IRB approval. Using these annotations, we compare racial biases present in both manual and automatically-generated image captions. We demonstrate differences in caption performance, sentiment, and word choice between images of lighter versus darker-skinned people. Further, we find the magnitude of these differences to be greater in modern captioning systems compared to older ones, thus leading to concerns that without proper consideration and mitigation these differences will only become increasingly prevalent. Code and data is available at https://princetonvisualai.github.io/imagecaptioning-bias .