 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Adoption Across a Multinational Workforce: Sociotechnical Conditions for GenAI Acceptance in Human Resources
Jun 16, 2026Generative AI (GenAI) deployment in the workplace is accelerating rapidly. Nevertheless, questions of who adopts, who benefits, and who is left behind and why are still understudied. In this paper, we investigate these dynamics in the context of a multinational tech company transitioning from a legacy Human Resources (HR) search system to a GenAI-supported system, analyzing search log data, survey data (n=25), and ten semi-structured interviews. Our findings show that adoption depended on the fit between the GenAI system's design assumptions and employees' work positionalities (role, spoken language, tenure). Further, we find that employees' trust in GenAI answers was built through source-checking, comparison among systems, and seeking input from colleagues or HR when in doubt. Our contribution is twofold. First, we provide empirical evidence of workplace GenAI adoption during a live organizational transition, showing that adoption is influenced by factors such as situational fit, search literacy, and trust calibration. It is also further shaped by knowledge conditions such as the system's content quality, employee training, and guidance. Second, we translate these findings into design considerations for inclusive deployment and adoption in high-stakes environments such as HR. We argue that organizations should design systems considering the role and context-sensitive benefits they yield to different social groups. They also need to treat the organizational knowledge infrastructure as AI infrastructure to improve the accountability and usability of GenAI systems
Engaged AI Governance: Addressing the Last Mile Challenge Through Internal Expert Collaboration
Apr 23, 2026Under the EU AI Act, translating AI governance requirements into software development practice remains challenging. While AI governance frameworks exist at industry and organizational levels, empirical evidence of team-level implementation is scarce. We address this "Last Mile" Challenge through insider action research embedded within an AI startup. We present a legal-text-to-action pipeline that translates EU AI Act requirements into actionable strategies through internal expert collaboration by extracting requirements from legal text, engaging practitioners in assessment and ideation, and prioritizing implementation through collective evaluation. Our analysis reveals three patterns in how practitioners perceive regulatory requirements: convergence (compliance aligns with development priorities), existing practice (current work already satisfies requirements), and disconnection (requirements perceived as administrative overhead). Based on these patterns, we discuss when governance might be treated genuinely or performatively. Practitioners prioritize requirements that serve end-users or their own development needs, but view verification-oriented requirements as box-ticking exercises. This distinction suggests a translation challenge: regulatory requirements risk superficial treatment unless practitioners understand how compliance serves system quality and user protection. Expert collaboration offers a practical mechanism for transforming governance from external imposition to shared ownership and making previously invisible governance work visible and collective.
Operationalizing Pluralistic Values in Large Language Model Alignment Reveals Trade-offs in Safety, Inclusivity, and Model Behavior
Nov 18, 2025Although large language models (LLMs) are increasingly trained using human feedback for safety and alignment with human values, alignment decisions often overlook human social diversity. This study examines how incorporating pluralistic values affects LLM behavior by systematically evaluating demographic variation and design parameters in the alignment pipeline. We collected alignment data from US and German participants (N = 1,095, 27,375 ratings) who rated LLM responses across five dimensions: Toxicity, Emotional Awareness (EA), Sensitivity, Stereotypical Bias, and Helpfulness. We fine-tuned multiple Large Language Models and Large Reasoning Models using preferences from different social groups while varying rating scales, disagreement handling methods, and optimization techniques. The results revealed systematic demographic effects: male participants rated responses 18% less toxic than female participants; conservative and Black participants rated responses 27.9% and 44% more emotionally aware than liberal and White participants, respectively. Models fine-tuned on group-specific preferences exhibited distinct behaviors. Technical design choices showed strong effects: the preservation of rater disagreement achieved roughly 53% greater toxicity reduction than majority voting, and 5-point scales yielded about 22% more reduction than binary formats; and Direct Preference Optimization (DPO) consistently outperformed Group Relative Policy Optimization (GRPO) in multi-value optimization. These findings represent a preliminary step in answering a critical question: How should alignment balance expert-driven and user-driven signals to ensure both safety and fair representation?
Position: Measure Dataset Diversity, Don't Just Claim It
Jul 11, 2024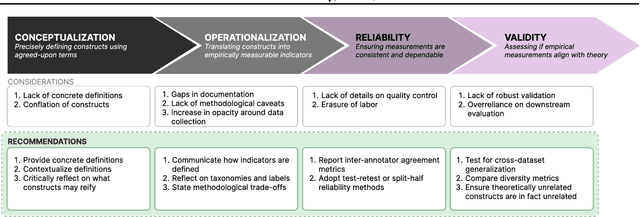
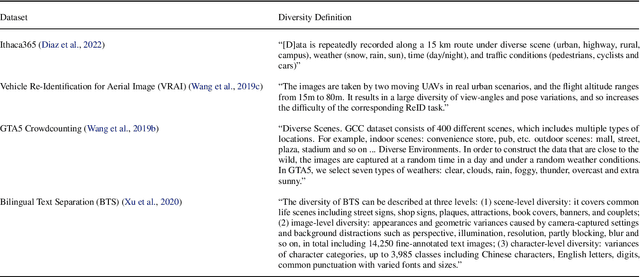
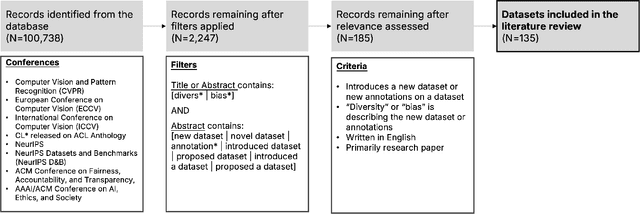
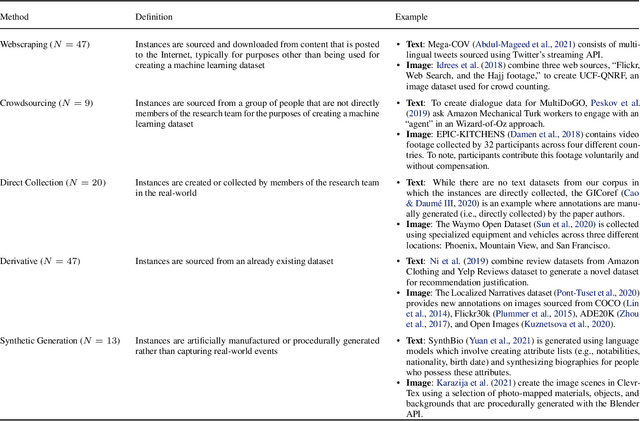
Machine learning (ML) datasets, often perceived as neutral, inherently encapsulate abstract and disputed social constructs. Dataset curators frequently employ value-laden terms such as diversity, bias, and quality to characterize datasets. Despite their prevalence, these terms lack clear definitions and validation. Our research explores the implications of this issue by analyzing "diversity" across 135 image and text datasets. Drawing from social sciences, we apply principles from measurement theory to identify considerations and offer recommendations for conceptualizing, operationalizing, and evaluating diversity in datasets. Our findings have broader implications for ML research, advocating for a more nuanced and precise approach to handling value-laden properties in dataset construction.
Resampled Datasets Are Not Enough: Mitigating Societal Bias Beyond Single Attributes
Jul 04, 2024
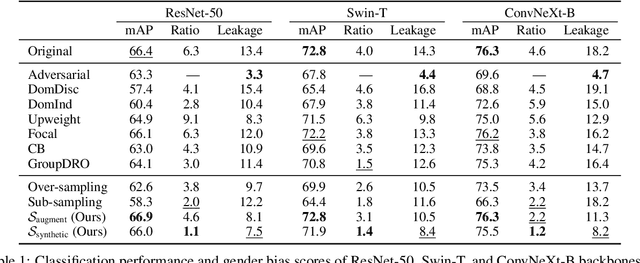
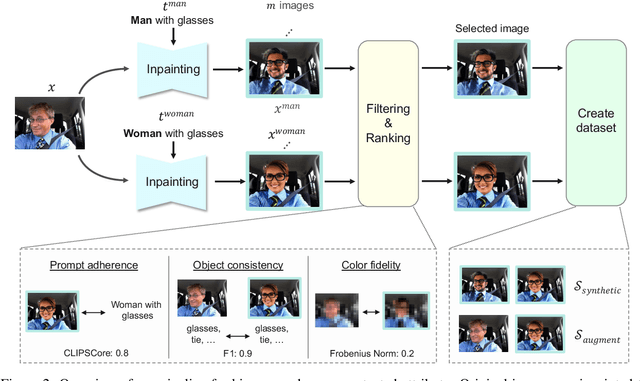
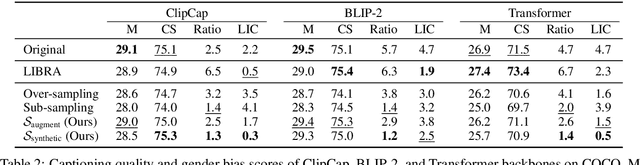
We tackle societal bias in image-text datasets by removing spurious correlations between protected groups and image attributes. Traditional methods only target labeled attributes, ignoring biases from unlabeled ones. Using text-guided inpainting models, our approach ensures protected group independence from all attributes and mitigates inpainting biases through data filtering. Evaluations on multi-label image classification and image captioning tasks show our method effectively reduces bias without compromising performance across various models.
Considerations for Ethical Speech Recognition Datasets
May 03, 2023Speech AI Technologies are largely trained on publicly available datasets or by the massive web-crawling of speech. In both cases, data acquisition focuses on minimizing collection effort, without necessarily taking the data subjects' protection or user needs into consideration. This results to models that are not robust when used on users who deviate from the dominant demographics in the training set, discriminating individuals having different dialects, accents, speaking styles, and disfluencies. In this talk, we use automatic speech recognition as a case study and examine the properties that ethical speech datasets should possess towards responsible AI applications. We showcase diversity issues, inclusion practices, and necessary considerations that can improve trained models, while facilitating model explainability and protecting users and data subjects. We argue for the legal & privacy protection of data subjects, targeted data sampling corresponding to user demographics & needs, appropriate meta data that ensure explainability & accountability in cases of model failure, and the sociotechnical \& situated model design. We hope this talk can inspire researchers \& practitioners to design and use more human-centric datasets in speech technologies and other domains, in ways that empower and respect users, while improving machine learning models' robustness and utility.
Upvotes? Downvotes? No Votes? Understanding the relationship between reaction mechanisms and political discourse on Reddit
Feb 19, 2023A significant share of political discourse occurs online on social media platforms. Policymakers and researchers try to understand the role of social media design in shaping the quality of political discourse around the globe. In the past decades, scholarship on political discourse theory has produced distinct characteristics of different types of prominent political rhetoric such as deliberative, civic, or demagogic discourse. This study investigates the relationship between social media reaction mechanisms (i.e., upvotes, downvotes) and political rhetoric in user discussions by engaging in an in-depth conceptual analysis of political discourse theory. First, we analyze 155 million user comments in 55 political subforums on Reddit between 2010 and 2018 to explore whether users' style of political discussion aligns with the essential components of deliberative, civic, and demagogic discourse. Second, we perform a quantitative study that combines confirmatory factor analysis with difference in differences models to explore whether different reaction mechanism schemes (e.g., upvotes only, upvotes and downvotes, no reaction mechanisms) correspond with political user discussion that is more or less characteristic of deliberative, civic, or demagogic discourse. We produce three main takeaways. First, despite being "ideal constructs of political rhetoric," we find that political discourse theories describe political discussions on Reddit to a large extent. Second, we find that discussions in subforums with only upvotes, or both up- and downvotes are associated with user discourse that is more deliberate and civic. Third, social media discussions are most demagogic in subreddits with no reaction mechanisms at all. These findings offer valuable contributions for ongoing policy discussions on the relationship between social media interface design and respectful political discussion among users.
Ethical Considerations for Collecting Human-Centric Image Datasets
Feb 07, 2023
Human-centric image datasets are critical to the development of computer vision technologies. However, recent investigations have foregrounded significant ethical issues related to privacy and bias, which have resulted in the complete retraction, or modification, of several prominent datasets. Recent works have tried to reverse this trend, for example, by proposing analytical frameworks for ethically evaluating datasets, the standardization of dataset documentation and curation practices, privacy preservation methodologies, as well as tools for surfacing and mitigating representational biases. Little attention, however, has been paid to the realities of operationalizing ethical data collection. To fill this gap, we present a set of key ethical considerations and practical recommendations for collecting more ethically-minded human-centric image data. Our research directly addresses issues of privacy and bias by contributing to the research community best practices for ethical data collection, covering purpose, privacy and consent, as well as diversity. We motivate each consideration by drawing on lessons from current practices, dataset withdrawals and audits, and analytical ethical frameworks. Our research is intended to augment recent scholarship, representing an important step toward more responsible data curation practices.