 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Healthy Evolution: Exploring the Role and Mechanisms of Human-Agent Interaction in Self-Evolving Systems
Jun 04, 2026Self-evolving agents improve through continual self-play and self-generated learning signals, but autonomous evolution can also cause capability degradation and safety drift. Although human feedback has proven effective for static and post-trained agents, its role in self-evolving systems remains underexplored. We introduce Agent Norm Correction through Human-like Oversight and Review (ANCHOR), an LLM-based framework that simulates human supervision and delivers feedback at various phases of self-evolution. With ANCHOR, we evaluate two representative open-source self-evolving agent systems across coding, mathematical reasoning, and safety. Our results show that even limited supervision substantially mitigates safety degradation while preserving stable performance on core evolutionary objectives. Further analysis shows that supervision over the output verification phase is the most effective for intervention, whereas increasing supervision frequency yields diminishing returns. These findings provide empirical evidence and practical guidance for designing more stable, controllable, and human-aligned self-evolving agent systems.
Privacy in Image Datasets: A Case Study on Pregnancy Ultrasounds
Feb 06, 2026The rise of generative models has led to increased use of large-scale datasets collected from the internet, often with minimal or no data curation. This raises concerns about the inclusion of sensitive or private information. In this work, we explore the presence of pregnancy ultrasound images, which contain sensitive personal information and are often shared online. Through a systematic examination of LAION-400M dataset using CLIP embedding similarity, we retrieve images containing pregnancy ultrasound and detect thousands of entities of private information such as names and locations. Our findings reveal that multiple images have high-risk information that could enable re-identification or impersonation. We conclude with recommended practices for dataset curation, data privacy, and ethical use of public image datasets.
EMMA: Concept Erasure Benchmark with Comprehensive Semantic Metrics and Diverse Categories
Dec 19, 2025The widespread adoption of text-to-image (T2I) generation has raised concerns about privacy, bias, and copyright violations. Concept erasure techniques offer a promising solution by selectively removing undesired concepts from pre-trained models without requiring full retraining. However, these methods are often evaluated on a limited set of concepts, relying on overly simplistic and direct prompts. To test the boundaries of concept erasure techniques, and assess whether they truly remove targeted concepts from model representations, we introduce EMMA, a benchmark that evaluates five key dimensions of concept erasure over 12 metrics. EMMA goes beyond standard metrics like image quality and time efficiency, testing robustness under challenging conditions, including indirect descriptions, visually similar non-target concepts, and potential gender and ethnicity bias, providing a socially aware analysis of method behavior. Using EMMA, we analyze five concept erasure methods across five domains (objects, celebrities, art styles, NSFW, and copyright). Our results show that existing methods struggle with implicit prompts (i.e., generating the erased concept when it is indirectly referenced) and visually similar non-target concepts (i.e., failing to generate non-targeted concepts resembling the erased one), while some amplify gender and ethnicity bias compared to the original model.
PANICL: Mitigating Over-Reliance on Single Prompt in Visual In-Context Learning
Sep 26, 2025Visual In-Context Learning (VICL) uses input-output image pairs, referred to as in-context pairs (or examples), as prompts alongside query images to guide models in performing diverse vision tasks. However, VICL often suffers from over-reliance on a single in-context pair, which can lead to biased and unstable predictions. We introduce PAtch-based $k$-Nearest neighbor visual In-Context Learning (PANICL), a general training-free framework that mitigates this issue by leveraging multiple in-context pairs. PANICL smooths assignment scores across pairs, reducing bias without requiring additional training. Extensive experiments on a variety of tasks, including foreground segmentation, single object detection, colorization, multi-object segmentation, and keypoint detection, demonstrate consistent improvements over strong baselines. Moreover, PANICL exhibits strong robustness to domain shifts, including dataset-level shift (e.g., from COCO to Pascal) and label-space shift (e.g., FSS-1000), and generalizes well to other VICL models such as SegGPT, Painter, and LVM, highlighting its versatility and broad applicability.
Bias in Gender Bias Benchmarks: How Spurious Features Distort Evaluation
Sep 09, 2025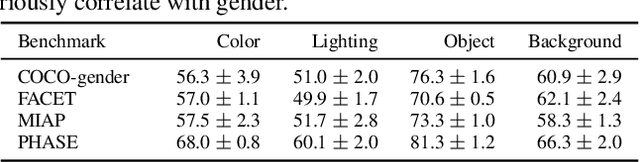

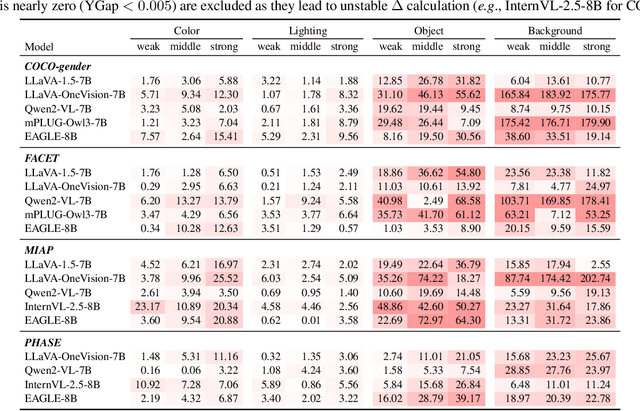

Gender bias in vision-language foundation models (VLMs) raises concerns about their safe deployment and is typically evaluated using benchmarks with gender annotations on real-world images. However, as these benchmarks often contain spurious correlations between gender and non-gender features, such as objects and backgrounds, we identify a critical oversight in gender bias evaluation: Do spurious features distort gender bias evaluation? To address this question, we systematically perturb non-gender features across four widely used benchmarks (COCO-gender, FACET, MIAP, and PHASE) and various VLMs to quantify their impact on bias evaluation. Our findings reveal that even minimal perturbations, such as masking just 10% of objects or weakly blurring backgrounds, can dramatically alter bias scores, shifting metrics by up to 175% in generative VLMs and 43% in CLIP variants. This suggests that current bias evaluations often reflect model responses to spurious features rather than gender bias, undermining their reliability. Since creating spurious feature-free benchmarks is fundamentally challenging, we recommend reporting bias metrics alongside feature-sensitivity measurements to enable a more reliable bias assessment.
From Global to Local: Social Bias Transfer in CLIP
Aug 25, 2025



The recycling of contrastive language-image pre-trained (CLIP) models as backbones for a large number of downstream tasks calls for a thorough analysis of their transferability implications, especially their well-documented reproduction of social biases and human stereotypes. How do such biases, learned during pre-training, propagate to downstream applications like visual question answering or image captioning? Do they transfer at all? We investigate this phenomenon, referred to as bias transfer in prior literature, through a comprehensive empirical analysis. Firstly, we examine how pre-training bias varies between global and local views of data, finding that bias measurement is highly dependent on the subset of data on which it is computed. Secondly, we analyze correlations between biases in the pre-trained models and the downstream tasks across varying levels of pre-training bias, finding difficulty in discovering consistent trends in bias transfer. Finally, we explore why this inconsistency occurs, showing that under the current paradigm, representation spaces of different pre-trained CLIPs tend to converge when adapted for downstream tasks. We hope this work offers valuable insights into bias behavior and informs future research to promote better bias mitigation practices.
QuMAB: Query-based Multi-annotator Behavior Pattern Learning
Jul 23, 2025Multi-annotator learning traditionally aggregates diverse annotations to approximate a single ground truth, treating disagreements as noise. However, this paradigm faces fundamental challenges: subjective tasks often lack absolute ground truth, and sparse annotation coverage makes aggregation statistically unreliable. We introduce a paradigm shift from sample-wise aggregation to annotator-wise behavior modeling. By treating annotator disagreements as valuable information rather than noise, modeling annotator-specific behavior patterns can reconstruct unlabeled data to reduce annotation cost, enhance aggregation reliability, and explain annotator decision behavior. To this end, we propose QuMATL (Query-based Multi-Annotator Behavior Pattern Learning), which uses light-weight queries to model individual annotators while capturing inter-annotator correlations as implicit regularization, preventing overfitting to sparse individual data while maintaining individualization and improving generalization, with a visualization of annotator focus regions offering an explainable analysis of behavior understanding. We contribute two large-scale datasets with dense per-annotator labels: STREET (4,300 labels/annotator) and AMER (average 3,118 labels/annotator), the first multimodal multi-annotator dataset.
E-InMeMo: Enhanced Prompting for Visual In-Context Learning
Apr 25, 2025Large-scale models trained on extensive datasets have become the standard due to their strong generalizability across diverse tasks. In-context learning (ICL), widely used in natural language processing, leverages these models by providing task-specific prompts without modifying their parameters. This paradigm is increasingly being adapted for computer vision, where models receive an input-output image pair, known as an in-context pair, alongside a query image to illustrate the desired output. However, the success of visual ICL largely hinges on the quality of these prompts. To address this, we propose Enhanced Instruct Me More (E-InMeMo), a novel approach that incorporates learnable perturbations into in-context pairs to optimize prompting. Through extensive experiments on standard vision tasks, E-InMeMo demonstrates superior performance over existing state-of-the-art methods. Notably, it improves mIoU scores by 7.99 for foreground segmentation and by 17.04 for single object detection when compared to the baseline without learnable prompts. These results highlight E-InMeMo as a lightweight yet effective strategy for enhancing visual ICL. Code is publicly available at: https://github.com/Jackieam/E-InMeMo
Measure Twice, Cut Once: Grasping Video Structures and Event Semantics with LLMs for Video Temporal Localization
Mar 12, 2025



Localizing user-queried events through natural language is crucial for video understanding models. Recent methods predominantly adapt Video LLMs to generate event boundary timestamps to handle temporal localization tasks, which struggle to leverage LLMs' powerful semantic understanding. In this work, we introduce MeCo, a novel timestamp-free framework that enables video LLMs to fully harness their intrinsic semantic capabilities for temporal localization tasks. Rather than outputting boundary timestamps, MeCo partitions videos into holistic event and transition segments based on the proposed structural token generation and grounding pipeline, derived from video LLMs' temporal structure understanding capability. We further propose a query-focused captioning task that compels the LLM to extract fine-grained, event-specific details, bridging the gap between localization and higher-level semantics and enhancing localization performance. Extensive experiments on diverse temporal localization tasks show that MeCo consistently outperforms boundary-centric methods, underscoring the benefits of a semantic-driven approach for temporal localization with video LLMs.
No Annotations for Object Detection in Art through Stable Diffusion
Dec 09, 2024



Object detection in art is a valuable tool for the digital humanities, as it allows for faster identification of objects in artistic and historical images compared to humans. However, annotating such images poses significant challenges due to the need for specialized domain expertise. We present NADA (no annotations for detection in art), a pipeline that leverages diffusion models' art-related knowledge for object detection in paintings without the need for full bounding box supervision. Our method, which supports both weakly-supervised and zero-shot scenarios and does not require any fine-tuning of its pretrained components, consists of a class proposer based on large vision-language models and a class-conditioned detector based on Stable Diffusion. NADA is evaluated on two artwork datasets, ArtDL 2.0 and IconArt, outperforming prior work in weakly-supervised detection, while being the first work for zero-shot object detection in art. Code is available at https://github.com/patrick-john-ramos/nada