 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffectSeek: Agentic Affective Understanding in Long Videos under Vague User Queries
May 07, 2026Existing affective understanding studies have mainly focused on recognizing emotions from images, audio signals, or pre-cliped video clips, where the affective evidence is already given. This passive and clip-centered setting does not fully reflect real-world scenarios, in which users often interact with long videos and express their needs through natural-language queries. In this paper, we study \textbf{Vague-Query-driven video Affective Understanding (VQAU)}, a new task that requires models to localize affective moments in long videos, predict their emotion categories, and generate evidence-grounded rationales under vague user queries. To support this task, we construct \textbf{VQAU-Bench}, a benchmark that integrates long videos, vague affective queries, temporal clip annotations, emotion labels, and rationale explanations into a unified evaluation framework. VQAU-Bench enables systematic assessment of semantic-temporal-affective alignment, affective moment localization, emotion classification, and rationale generation. To address the multi-step reasoning challenges of VQAU, we further propose \textbf{AffectSeek}, an agentic framework that actively seeks, verifies, and explains affective moments in long videos. AffectSeek decomposes VQAU into intent interpretation, candidate localization, clip verification, emotion reasoning, and rationale generation, and progressively aligns vague user intent with long-video evidence through role-specialized reasoning and cross-stage verification. Experiments show that VQAU remains challenging for existing affective recognition models and single-step vision-language models, while AffectSeek provides a simple yet effective framework for agentic long-video affective understanding.
RobotEQ: Transitioning from Passive Intelligence to Active Intelligence in Embodied AI
May 07, 2026Embodied AI is a prominent research topic in both academia and industry. Current research centers on completing tasks based on explicit user instructions. However, for robots to integrate into human society, they must understand which actions are permissible and which are prohibited, even without explicit commands. We refer to the user-guided AI as passive intelligence and the unguided AI as active intelligence. This paper introduces RobotEQ, the first benchmark for active intelligence, aiming to assess whether existing models can comprehend and adhere to social norms in embodied scenarios. First, we construct RobotEQ-Data, a dataset consisting of 1,900 egocentric images, spanning 10 representative embodied categories and 56 subcategories. Through extensive manual annotation, we provide 5,353 action judgment questions and 1,286 spatial grounding questions, specifying appropriate robot actions across diverse scenarios. Furthermore, we establish RobotEQ-Bench to evaluate the performance of state-of-the-art models on this task. Experimental results show that current models still fall short in achieving reliable active intelligence, particularly in spatial grounding. Meanwhile, we observe that leveraging RAG techniques to incorporate external social norm knowledge bases can generally enhance performance. This work can facilitate the transition of robotics from user-guided passive manipulation to active social compliance.
EmoTrans: A Benchmark for Understanding, Reasoning, and Predicting Emotion Transitions in Multimodal LLMs
Apr 25, 2026Recent multimodal large language models (MLLMs) have shown strong capabilities in perception, reasoning, and generation, and are increasingly used in applications such as social robots and human-computer interaction, where understanding human emotions is essential. However, existing benchmarks mainly formulate emotion understanding as a static recognition problem, leaving it largely unclear whether current MLLMs can understand emotion as a dynamic process that evolves, shifts between states, and unfolds across diverse social contexts. To bridge this gap, we present EmoTrans, a benchmark for evaluating emotion dynamics understanding in multimodal videos. EmoTrans contains 1,000 carefully collected and manually annotated video clips, covering 12 real-world scenarios, and further provides over 3,000 task-specific question-answer (QA) pairs for fine-grained evaluation. The benchmark introduces four tasks, namely Emotion Change Detection (ECD), Emotion State Identification (ESI), Emotion Transition Reasoning (ETR), and Next Emotion Prediction (NEP), forming a progressive evaluation framework from coarse-grained detection to deeper reasoning and prediction. We conduct a comprehensive evaluation of 18 state-of-the-art MLLMs on EmoTrans and obtain two main findings. First, although current MLLMs show relatively stronger performance on coarse-grained emotion change detection, they still struggle with fine-grained emotion dynamics modeling. Second, socially complex settings, especially multi-person scenarios, remain substantially challenging, while reasoning-oriented variants do not consistently yield clear improvements. To facilitate future research, we publicly release the benchmark, evaluation protocol, and code at https://github.com/Emo-gml/EmoTrans.
SayNext-Bench: Why Do LLMs Struggle with Next-Utterance Prediction?
Jan 30, 2026We explore the use of large language models (LLMs) for next-utterance prediction in human dialogue. Despite recent advances in LLMs demonstrating their ability to engage in natural conversations with users, we show that even leading models surprisingly struggle to predict a human speaker's next utterance. Instead, humans can readily anticipate forthcoming utterances based on multimodal cues, such as gestures, gaze, and emotional tone, from the context. To systematically examine whether LLMs can reproduce this ability, we propose SayNext-Bench, a benchmark that evaluates LLMs and Multimodal LLMs (MLLMs) on anticipating context-conditioned responses from multimodal cues spanning a variety of real-world scenarios. To support this benchmark, we build SayNext-PC, a novel large-scale dataset containing dialogues with rich multimodal cues. Building on this, we further develop a dual-route prediction MLLM, SayNext-Chat, that incorporates cognitively inspired design to emulate predictive processing in conversation. Experimental results demonstrate that our model outperforms state-of-the-art MLLMs in terms of lexical overlap, semantic similarity, and emotion consistency. Our results prove the feasibility of next-utterance prediction with LLMs from multimodal cues and emphasize the (i) indispensable role of multimodal cues and (ii) actively predictive processing as the foundation of natural human interaction, which is missing in current MLLMs. We hope that this exploration offers a new research entry toward more human-like, context-sensitive AI interaction for human-centered AI. Our benchmark and model can be accessed at https://saynext.github.io/.
Emotion-LLaMAv2 and MMEVerse: A New Framework and Benchmark for Multimodal Emotion Understanding
Jan 23, 2026Understanding human emotions from multimodal signals poses a significant challenge in affective computing and human-robot interaction. While multimodal large language models (MLLMs) have excelled in general vision-language tasks, their capabilities in emotional reasoning remain limited. The field currently suffers from a scarcity of large-scale datasets with high-quality, descriptive emotion annotations and lacks standardized benchmarks for evaluation. Our preliminary framework, Emotion-LLaMA, pioneered instruction-tuned multimodal learning for emotion reasoning but was restricted by explicit face detectors, implicit fusion strategies, and low-quality training data with limited scale. To address these limitations, we present Emotion-LLaMAv2 and the MMEVerse benchmark, establishing an end-to-end pipeline together with a standardized evaluation setting for emotion recognition and reasoning. Emotion-LLaMAv2 introduces three key advances. First, an end-to-end multiview encoder eliminates external face detection and captures nuanced emotional cues via richer spatial and temporal multiview tokens. Second, a Conv Attention pre-fusion module is designed to enable simultaneous local and global multimodal feature interactions external to the LLM backbone. Third, a perception-to-cognition curriculum instruction tuning scheme within the LLaMA2 backbone unifies emotion recognition and free-form emotion reasoning. To support large-scale training and reproducible evaluation, MMEVerse aggregates twelve publicly available emotion datasets, including IEMOCAP, MELD, DFEW, and MAFW, into a unified multimodal instruction format. The data are re-annotated via a multi-agent pipeline involving Qwen2 Audio, Qwen2.5 VL, and GPT 4o, producing 130k training clips and 36k testing clips across 18 evaluation benchmarks.
A Unified Evaluation Framework for Multi-Annotator Tendency Learning
Aug 14, 2025Recent works have emerged in multi-annotator learning that shift focus from Consensus-oriented Learning (CoL), which aggregates multiple annotations into a single ground-truth prediction, to Individual Tendency Learning (ITL), which models annotator-specific labeling behavior patterns (i.e., tendency) to provide explanation analysis for understanding annotator decisions. However, no evaluation framework currently exists to assess whether ITL methods truly capture individual tendencies and provide meaningful behavioral explanations. To address this gap, we propose the first unified evaluation framework with two novel metrics: (1) Difference of Inter-annotator Consistency (DIC) quantifies how well models capture annotator tendencies by comparing predicted inter-annotator similarity structures with ground-truth; (2) Behavior Alignment Explainability (BAE) evaluates how well model explanations reflect annotator behavior and decision relevance by aligning explainability-derived with ground-truth labeling similarity structures via Multidimensional Scaling (MDS). Extensive experiments validate the effectiveness of our proposed evaluation framework.
Learning Transferable Facial Emotion Representations from Large-Scale Semantically Rich Captions
Jul 28, 2025Current facial emotion recognition systems are predominately trained to predict a fixed set of predefined categories or abstract dimensional values. This constrained form of supervision hinders generalization and applicability, as it reduces the rich and nuanced spectrum of emotions into oversimplified labels or scales. In contrast, natural language provides a more flexible, expressive, and interpretable way to represent emotions, offering a much broader source of supervision. Yet, leveraging semantically rich natural language captions as supervisory signals for facial emotion representation learning remains relatively underexplored, primarily due to two key challenges: 1) the lack of large-scale caption datasets with rich emotional semantics, and 2) the absence of effective frameworks tailored to harness such rich supervision. To this end, we introduce EmoCap100K, a large-scale facial emotion caption dataset comprising over 100,000 samples, featuring rich and structured semantic descriptions that capture both global affective states and fine-grained local facial behaviors. Building upon this dataset, we further propose EmoCapCLIP, which incorporates a joint global-local contrastive learning framework enhanced by a cross-modal guided positive mining module. This design facilitates the comprehensive exploitation of multi-level caption information while accommodating semantic similarities between closely related expressions. Extensive evaluations on over 20 benchmarks covering five tasks demonstrate the superior performance of our method, highlighting the promise of learning facial emotion representations from large-scale semantically rich captions. The code and data will be available at https://github.com/sunlicai/EmoCapCLIP.
QuMAB: Query-based Multi-annotator Behavior Pattern Learning
Jul 23, 2025Multi-annotator learning traditionally aggregates diverse annotations to approximate a single ground truth, treating disagreements as noise. However, this paradigm faces fundamental challenges: subjective tasks often lack absolute ground truth, and sparse annotation coverage makes aggregation statistically unreliable. We introduce a paradigm shift from sample-wise aggregation to annotator-wise behavior modeling. By treating annotator disagreements as valuable information rather than noise, modeling annotator-specific behavior patterns can reconstruct unlabeled data to reduce annotation cost, enhance aggregation reliability, and explain annotator decision behavior. To this end, we propose QuMATL (Query-based Multi-Annotator Behavior Pattern Learning), which uses light-weight queries to model individual annotators while capturing inter-annotator correlations as implicit regularization, preventing overfitting to sparse individual data while maintaining individualization and improving generalization, with a visualization of annotator focus regions offering an explainable analysis of behavior understanding. We contribute two large-scale datasets with dense per-annotator labels: STREET (4,300 labels/annotator) and AMER (average 3,118 labels/annotator), the first multimodal multi-annotator dataset.
Are MLMs Trapped in the Visual Room?
May 29, 2025Can multi-modal large models (MLMs) that can ``see'' an image be said to ``understand'' it? Drawing inspiration from Searle's Chinese Room, we propose the \textbf{Visual Room} argument: a system may process and describe every detail of visual inputs by following algorithmic rules, without genuinely comprehending the underlying intention. This dilemma challenges the prevailing assumption that perceptual mastery implies genuine understanding. In implementation, we introduce a two-tier evaluation framework spanning perception and cognition. The perception component evaluates whether MLMs can accurately capture the surface-level details of visual contents, where the cognitive component examines their ability to infer sarcasm polarity. To support this framework, We further introduce a high-quality multi-modal sarcasm dataset comprising both 924 static images and 100 dynamic videos. All sarcasm labels are annotated by the original authors and verified by independent reviewers to ensure clarity and consistency. We evaluate eight state-of-the-art (SoTA) MLMs. Our results highlight three key findings: (1) MLMs perform well on perception tasks; (2) even with correct perception, models exhibit an average error rate of ~16.1\% in sarcasm understanding, revealing a significant gap between seeing and understanding; (3) error analysis attributes this gap to deficiencies in emotional reasoning, commonsense inference, and context alignment. This work provides empirical grounding for the proposed Visual Room argument and offers a new evaluation paradigm for MLMs.
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix
May 19, 2025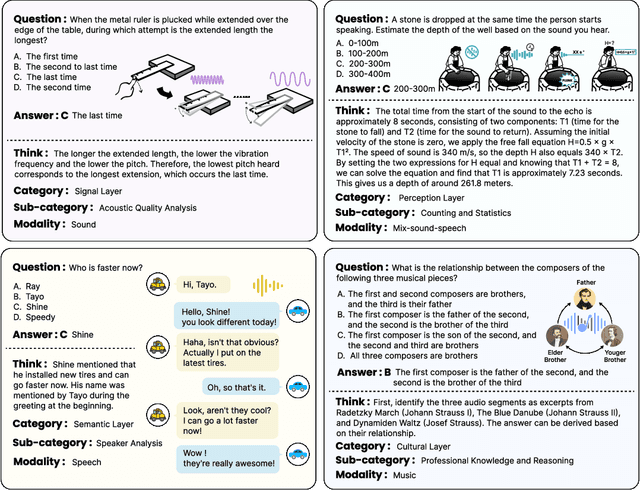

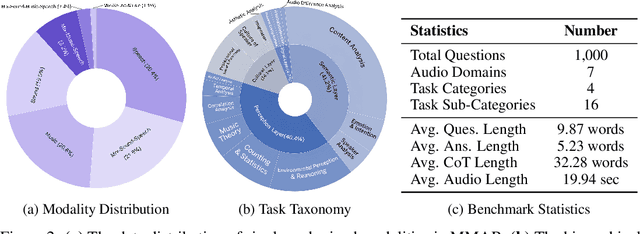
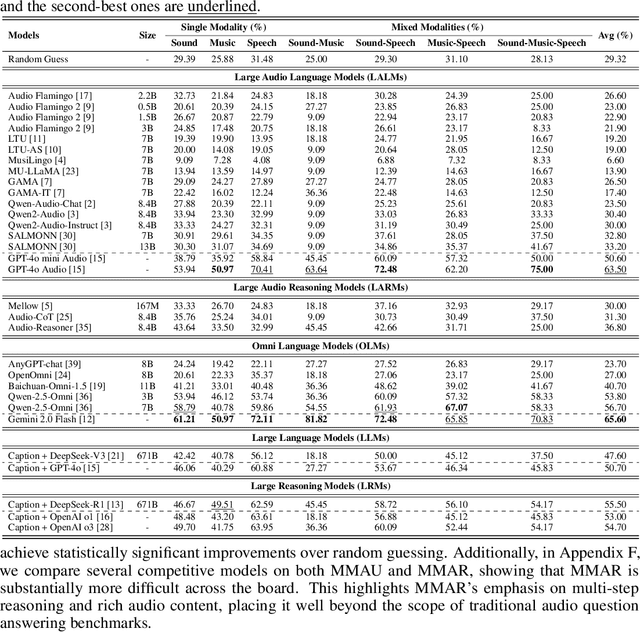
We introduce MMAR, a new benchmark designed to evaluate the deep reasoning capabilities of Audio-Language Models (ALMs) across massive multi-disciplinary tasks. MMAR comprises 1,000 meticulously curated audio-question-answer triplets, collected from real-world internet videos and refined through iterative error corrections and quality checks to ensure high quality. Unlike existing benchmarks that are limited to specific domains of sound, music, or speech, MMAR extends them to a broad spectrum of real-world audio scenarios, including mixed-modality combinations of sound, music, and speech. Each question in MMAR is hierarchically categorized across four reasoning layers: Signal, Perception, Semantic, and Cultural, with additional sub-categories within each layer to reflect task diversity and complexity. To further foster research in this area, we annotate every question with a Chain-of-Thought (CoT) rationale to promote future advancements in audio reasoning. Each item in the benchmark demands multi-step deep reasoning beyond surface-level understanding. Moreover, a part of the questions requires graduate-level perceptual and domain-specific knowledge, elevating the benchmark's difficulty and depth. We evaluate MMAR using a broad set of models, including Large Audio-Language Models (LALMs), Large Audio Reasoning Models (LARMs), Omni Language Models (OLMs), Large Language Models (LLMs), and Large Reasoning Models (LRMs), with audio caption inputs. The performance of these models on MMAR highlights the benchmark's challenging nature, and our analysis further reveals critical limitations of understanding and reasoning capabilities among current models. We hope MMAR will serve as a catalyst for future advances in this important but little-explored area.